-
-
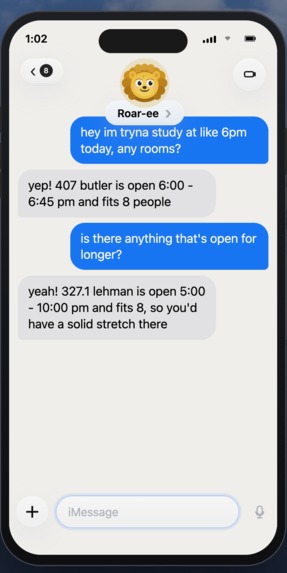
library study space demo
-
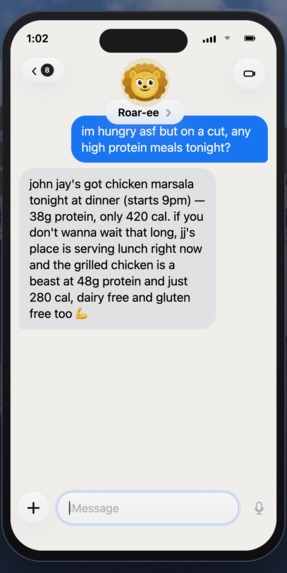
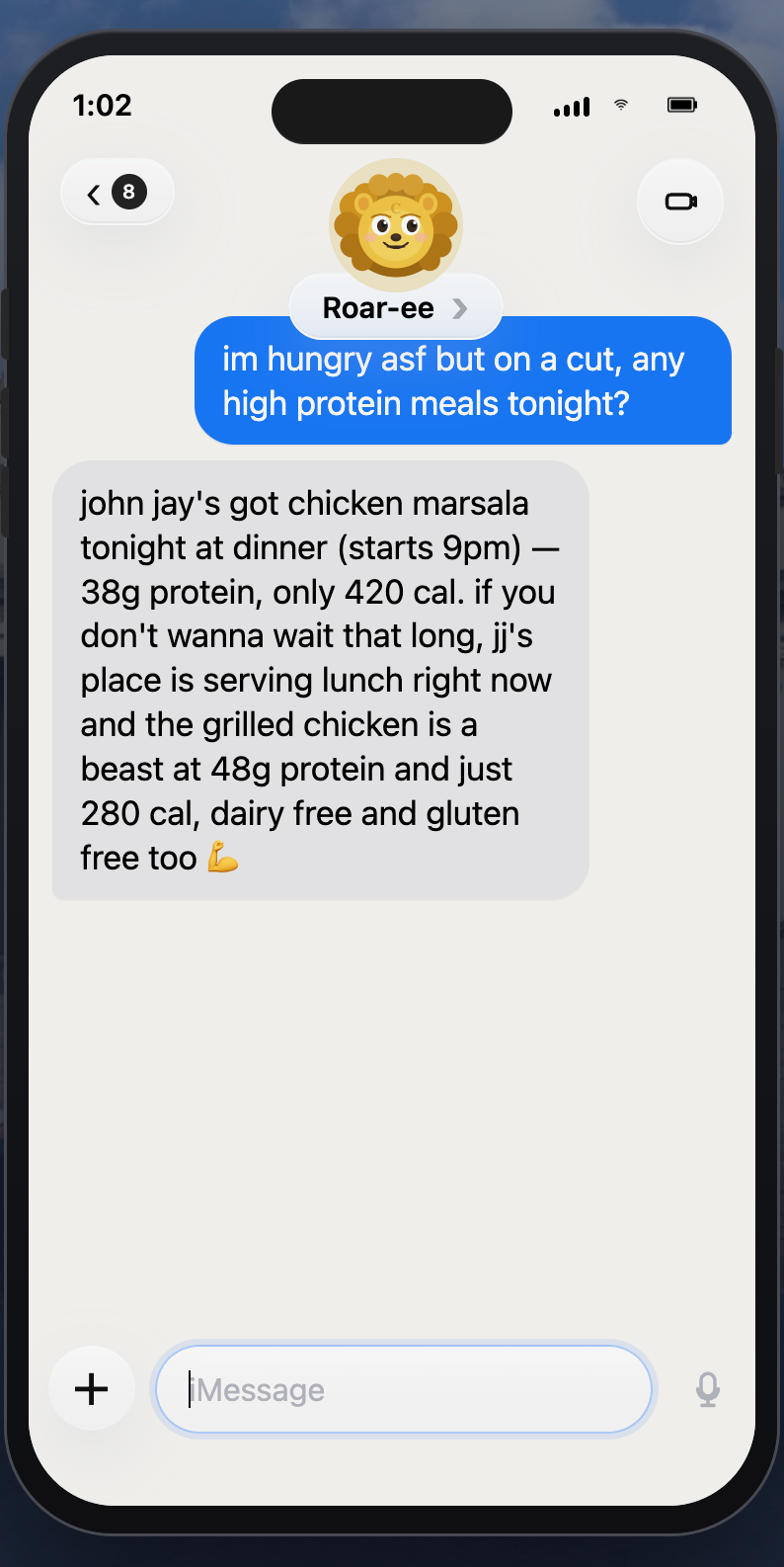
dining hall options for high protein meals
-
landing
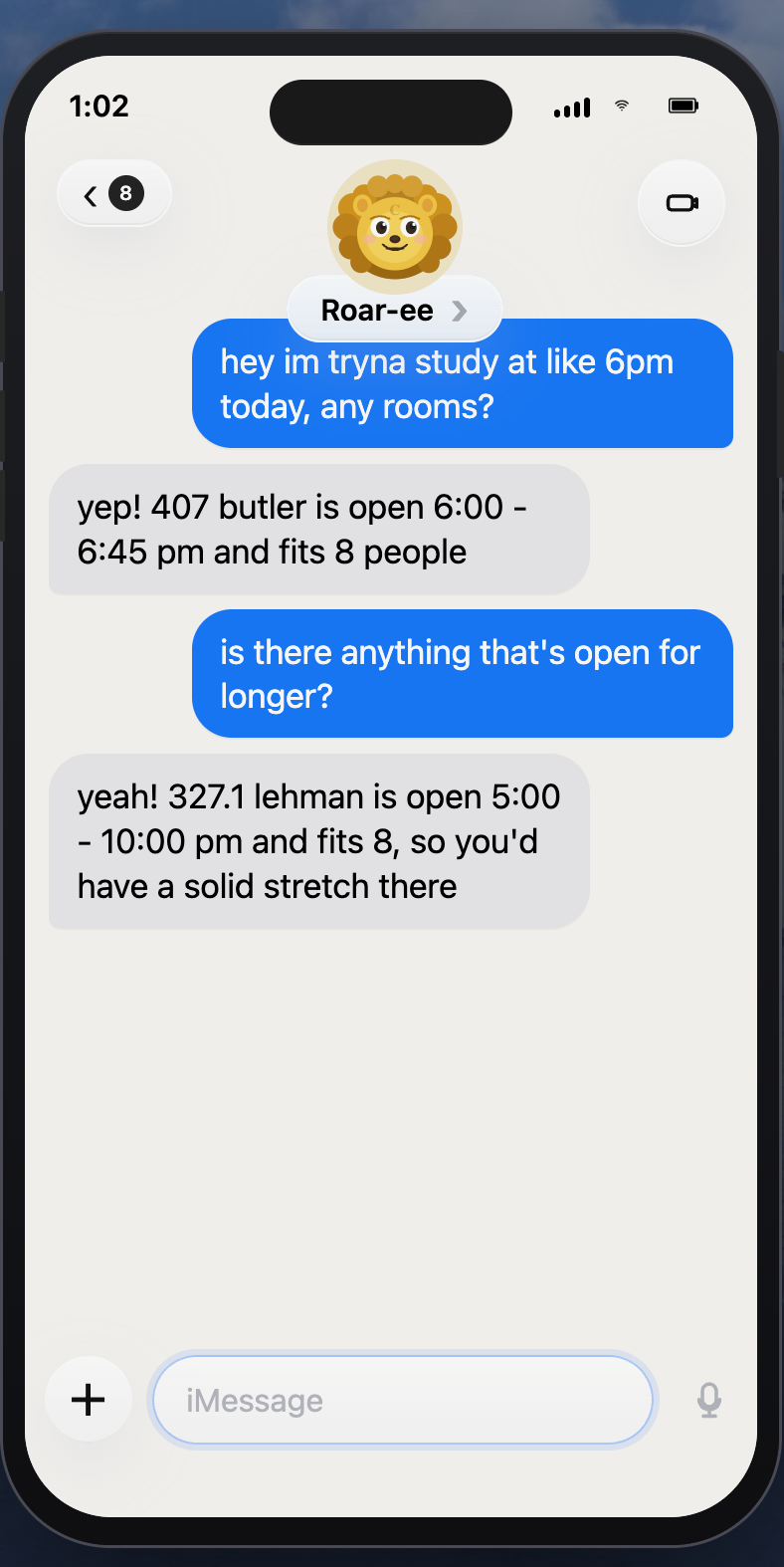
OpenCampus
Inspiration
Columbia students constantly juggle multiple websites to check basic campus info — gym hours, dining menus, study room availability, library books. There is no single place that answers these questions quickly.
OpenCampus solves this by providing a conversational assistant that delivers real-time campus data in plain language.
What it does
OpenCampus is a chatbot that gives Columbia students instant answers about four core campus services (for now):
Gym
Real-time hours for Dodge Fitness Center, Uris Pool, Blue Gym, Levien, Aerobics Room, and Functional Fitness Studio, including live activity schedules.Dining
Daily menus across JJ's Place, Ferris Booth, and John Jay with dietary tags and nutritional macros (protein, carbs, fat, calories).Study Rooms
Live availability across 29 rooms in 5 libraries with specific time slots.Library Books
Search Columbia's CLIO catalog for availability, location, call number, and copy count.
Live Demo — Real Data (April 12, 2026)
Every response is grounded in live data scraped from Columbia systems.
| Source | Data Point | Method |
|---|---|---|
| Gym | 6 facilities with activity schedules (e.g. Basketball 10am–1:45pm) | HTML tables + Google Calendar iCal |
| Dining | 167 menu items across 10 meal periods with macros | Angular scope extraction (Playwright) |
| Study Rooms | 302 available slots across 29 rooms, ~100ms latency | Direct LibCal API (HTTP POST) |
| Library | 23 books with copy-level metadata | CLIO Blacklight JSON API |
Example query:
"Is there a basketball game at Dodge right now?"
Returns a real-time answer from Google Calendar data.
How we built it
Backend (Python)
Each data source uses a purpose-built scraping strategy:
Dining
Playwright loads the Angular site and extracts structured data viapage.evaluate().Gym
HTML parsing for hours + iCal feeds for activity schedules usingicalendarandrecurring-ical-events.Study Rooms
Direct POST to/spaces/availability/gridendpoint (~100ms latency).Library
CLIO Blacklight JSON API via.jsonendpoints.
Nutritional macros are batch-estimated using Claude Haiku and cached for near-zero marginal cost.
Frontend
- Next.js chat interface (iPhone-style UI)
- Scraped data injected into LLM context for grounded responses
- Designed for future iMessage integration (SendBlue pending)
Challenges
- macOS
com.apple.provenanceblocked git, pip, and pytest workflows - Each source required a different extraction strategy (Angular, HTML, iCal, REST, Blacklight)
- LibCal API required reverse-engineering (
eid=-1, exclusive end-date) via XHR inspection pytest-asyncioversion conflicts caused test hangs
Accomplishments
- 100% real data — no mock responses
- ~100ms study room queries with no caching
- 78 menu items with cached macro estimates
- 22 textbooks pre-indexed with detailed metadata
- 3/4 sources require zero API keys
What we learned
- XHR inspection is more reliable than static analysis
- Public iCal feeds are high-value, underused data sources
- LLM-based macro estimation is accurate enough for real use
- Blacklight exposes a hidden JSON API via
.jsonendpoints
What's next
Raspberry Pi deployment
On-campus node with cron jobs (15-min refresh for gym/dining, real-time for others)OpenClaw intent parsing
Replace keyword matching with LLM-based multi-turn understandingExpanded calendar integration
Classes, campus events, office hours via iCal feedsProactive notifications
Alerts for study room openings and book availabilityPlaywright on ARM
System Chromium on Pi for browser-based scraping
Built With
- campus-events
- floor-5
- httpx
- nextjs
- openclaw
- pydantic
- python
- raspberry-pi
- sqlite



Log in or sign up for Devpost to join the conversation.