-
-

Open Mind
-

Mental Health
-

Problems
-

Emotion Detection
-
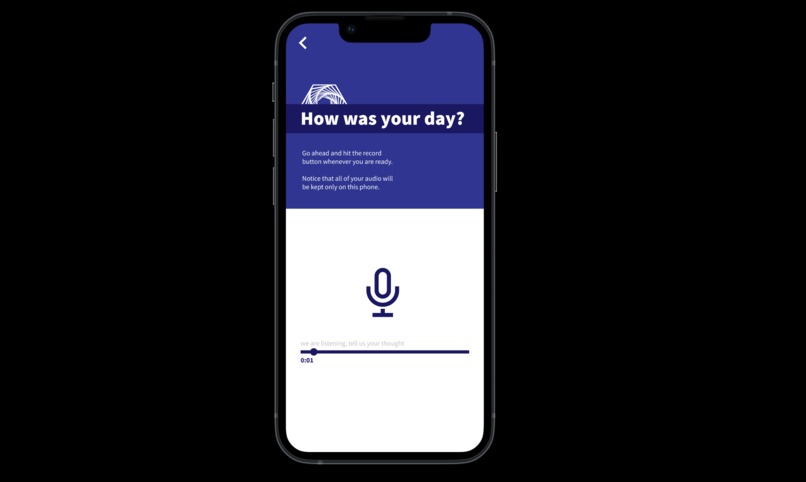
Recording Journal
-

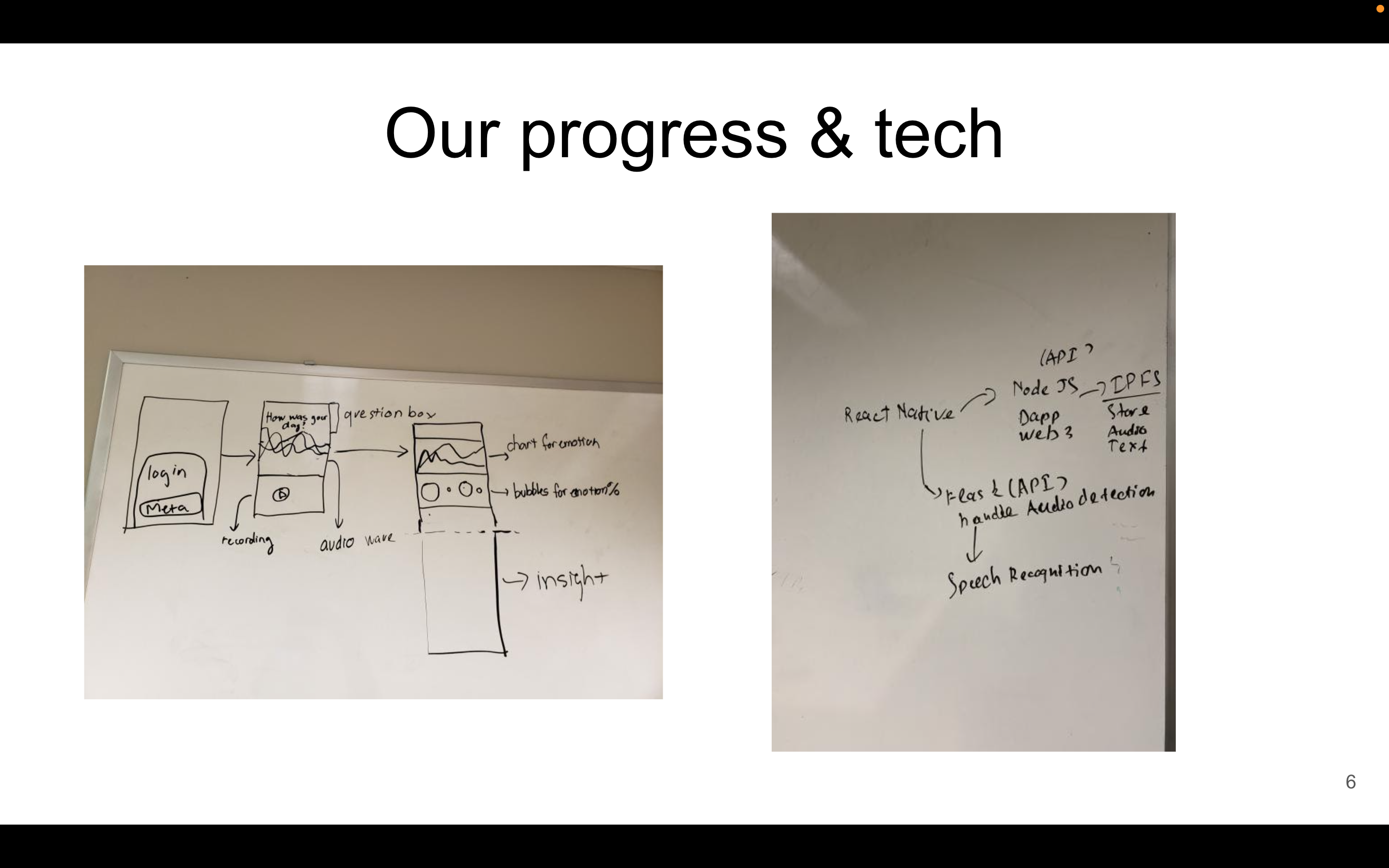
Progress & Tech
-
Machine Learning Progress





🤯 Inspiration
Mental health is always an alarming and significant problem, especially in this era where there are tons of distractions and horrible things happening around us, both in the real world and digital world. Thus it is more important than ever that we should focus on our mental health.
- 1 in 5 Americans has experienced some form of mental illness
- 1 in 10 young people experienced a period of major depression
- Since 2013, millennials have seen a 47% increase in major-depression diagnoses
🧐 What it does
Our team wanted to build a speech-to-text therapy app that helps detect your mental health and give advice based on your emotions and mind state.
Basically it records your thoughts about the day and the app will detect and give the results of the percentage of different kinds of moods with charts and weekly statistics. Then give the users advice based on emotions
🥸How we built it
- React Native App with expo
- NodeJS, IPFS, and Web3 to store secured audio files encrypted as hashes on the blockchain.
- Meta Mask for user authentication. Machine Learning
- Sklearn (machine learning library)
- Librosa (library for audio and music processing in Python)
- Pydub (for manipulating audio files)
Model Training
- We take in an audio file as input
- We split the audio file into small snippets, each 1 second long (although we can adjust the snippet length)
- We feed each snippet into our Classifier model, which returns a prediction for the emotion being expressed.
- One of seven emotions to choose from
- We gather the predictions for the various snippets to help us form a graph of emotions over time. (Optimally, as the snippet length gets smaller, our program more closely simulates "real time." However, we chose a length of 1 second because predicting emotion in a shorter time than that is difficult).
- We obtain statistics about the emotions, e.g the percentage of each emotion expressed throughout the full audio file
 Overview of the model:
Overview of the model:
- We train a feedforward neural network to predict the emotion expressed in an audio file
- We use the sklearn library to build the neural network
- Our dataset is a set of 1,440 short audio clips of trained actors, both male and female, uttering sentences while expressing different emotions (https://www.kaggle.com/uwrfkaggler/ravdess-emotional-speech-audio). Each audio clip is labeled with the emotion
- First 75% of clips are used as training data. The other 25% are used for test data.
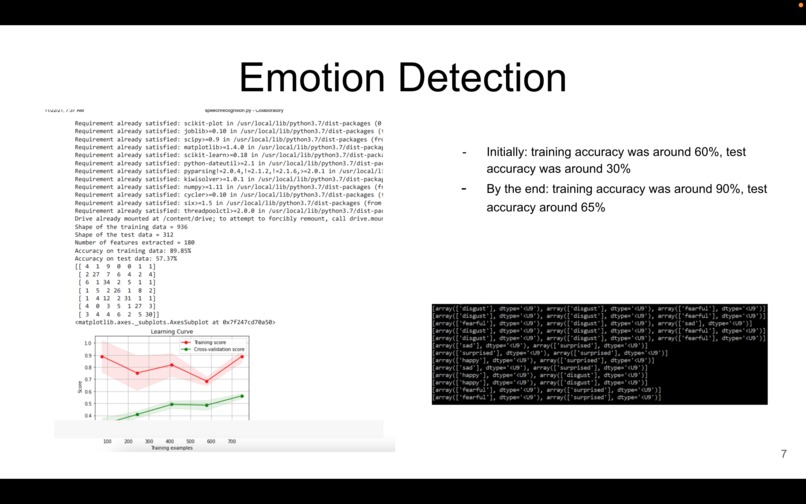
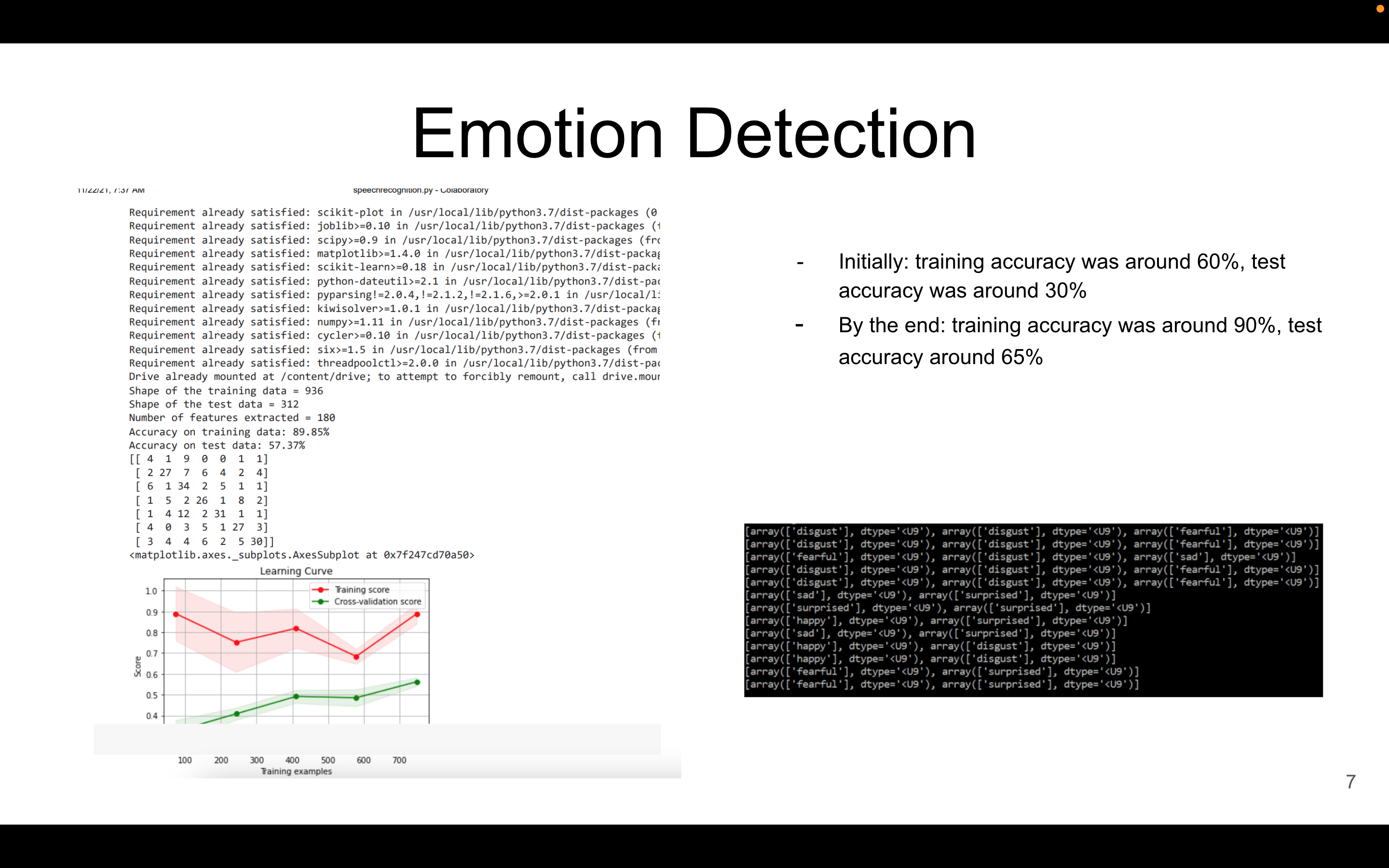
We spent quite a bit of time to improve model's performance on this dataset: the number of hidden layers, the number of nodes per layer, the learning rate, and the L2 penalty. This allowed us to drastically improve model performance Initially: training accuracy was around 60%, test accuracy was around 30% By the end: training accuracy was around 90%, test accuracy around 65%

However, the gap between the training and test accuracy suggests that the model may be overfitting to the training data, which is something that should be addressed in the future
😅 Challenges we ran into
- building an interface with so many different features and functions within very constrained time processing large amounts of data and complex audio wave
- Learning web3 in a short time frame
- s c o p e ## 😊Accomplishments that we're proud of Implement nearly e v e r y t h i n g we stated in the beginning to do in the span of 24 hours Literally proud!
🤔What we learned
- Aiming for ambitious projects is terrifying but feels good
😤 What's next for Open Mind
- Implementation in the real world! We aim to continue developing this to push out to real users
- We would love to learn more about the technology (ML, web3) and work with users from different backgrounds to understand more about their problems regarding mental health


Log in or sign up for Devpost to join the conversation.