-
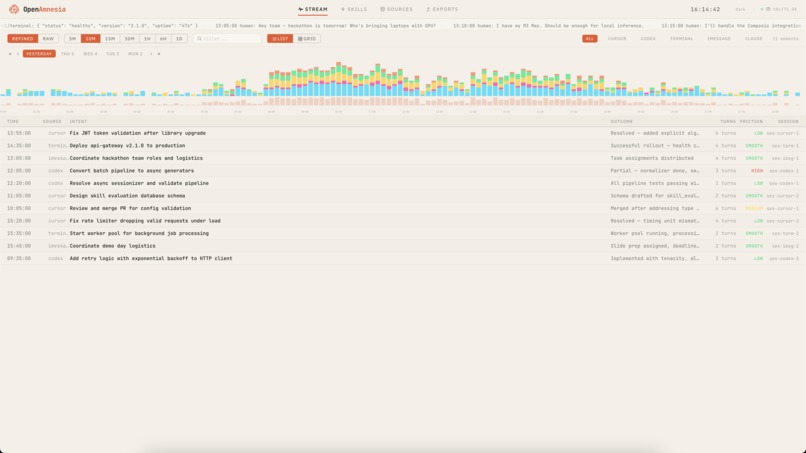
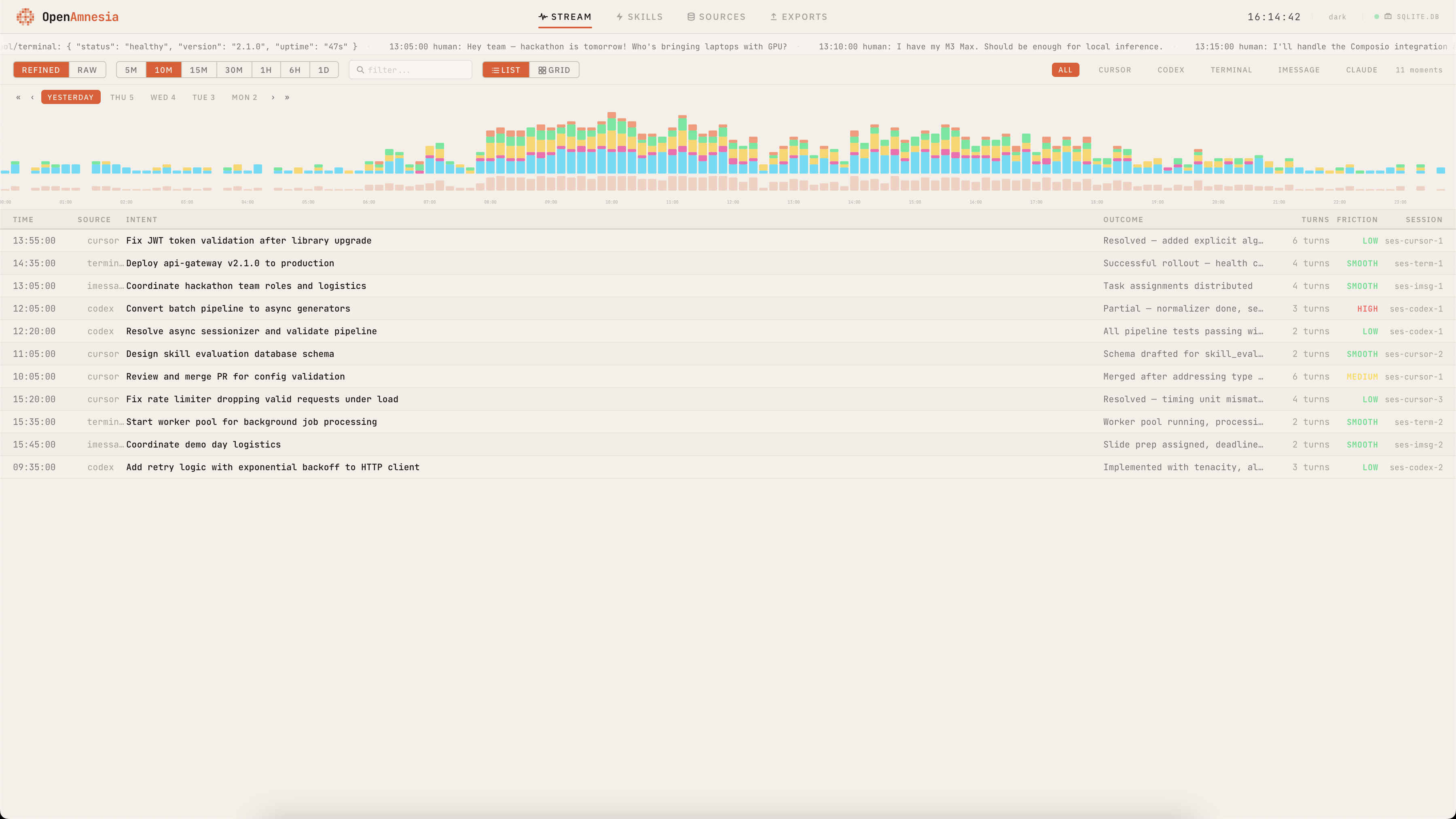
Frontend UI light mode discovery of skills and moments
-
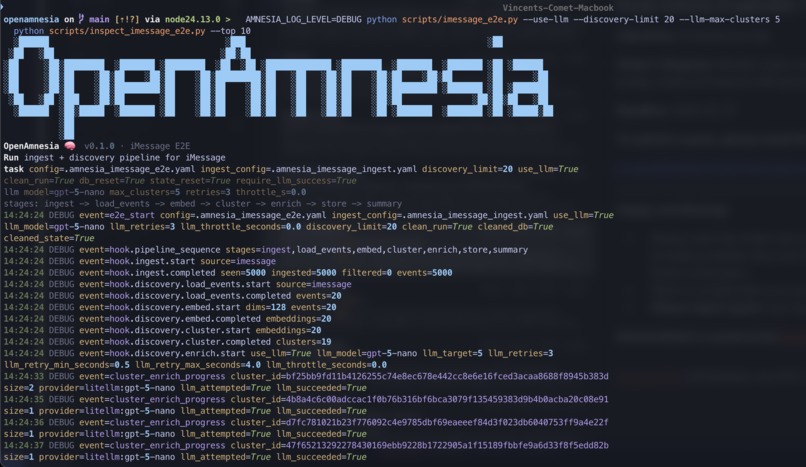
SDK agent which can be installed as service which will find and extract moments and skills
-
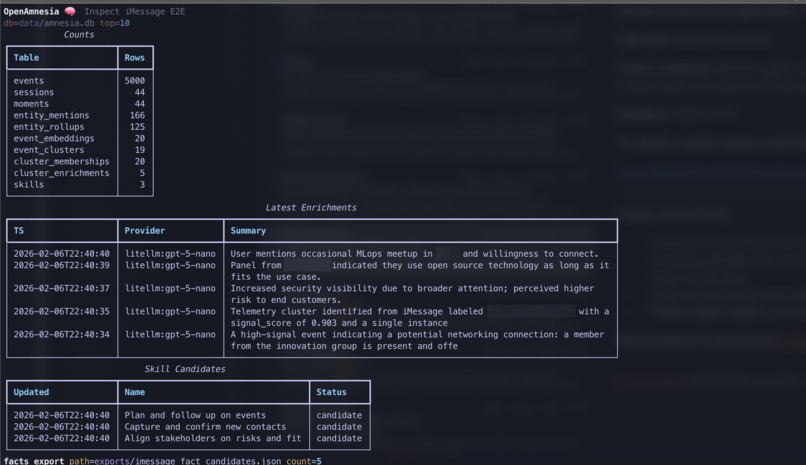
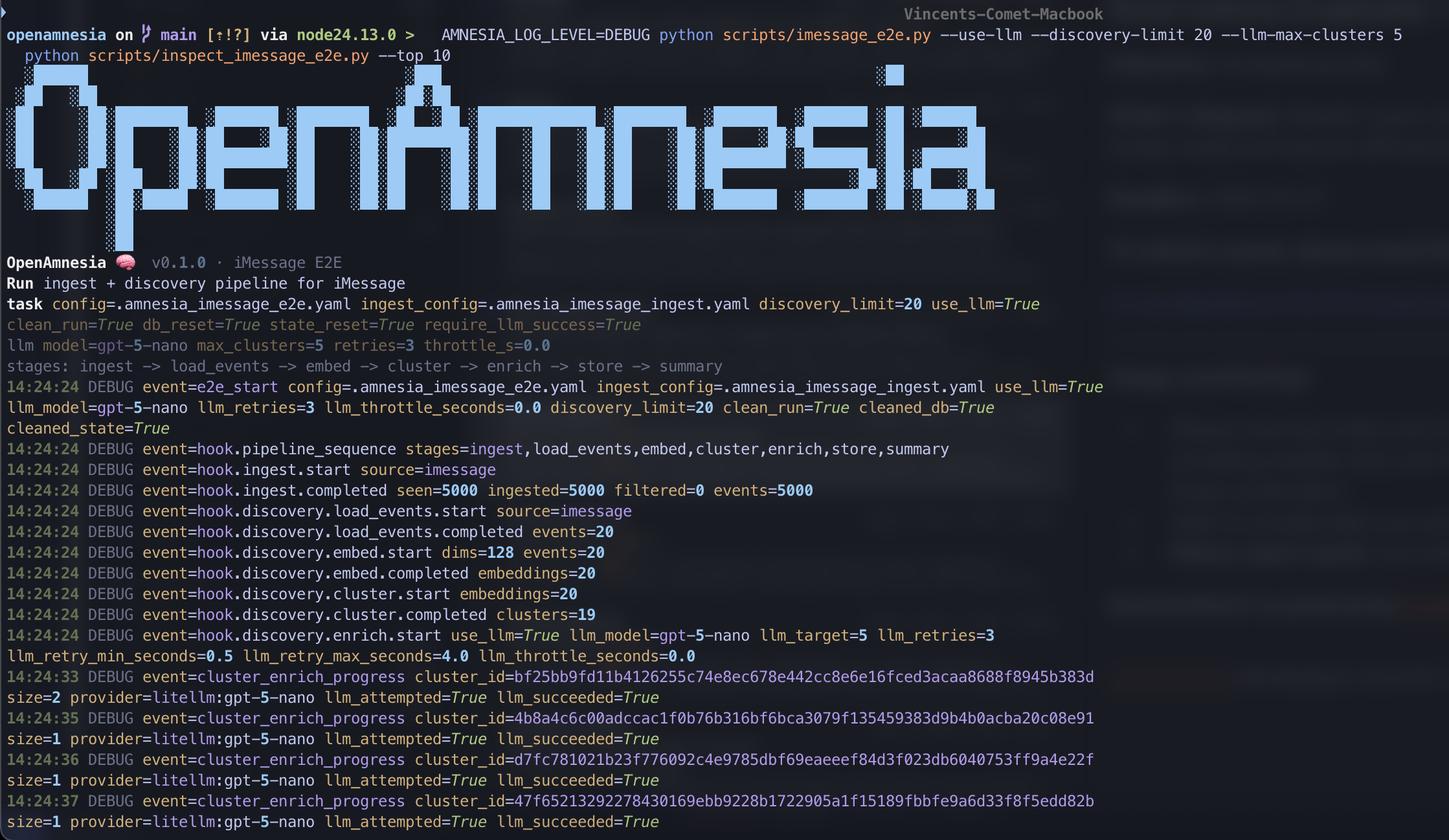
SDK debug output showing skill and conversation discovery
-
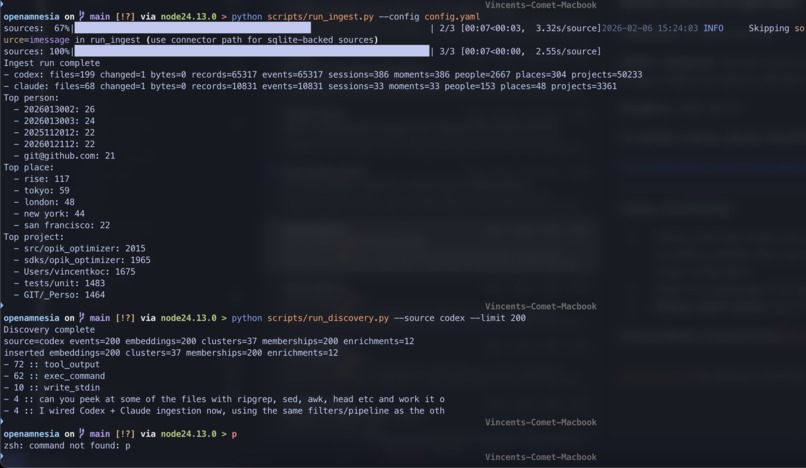
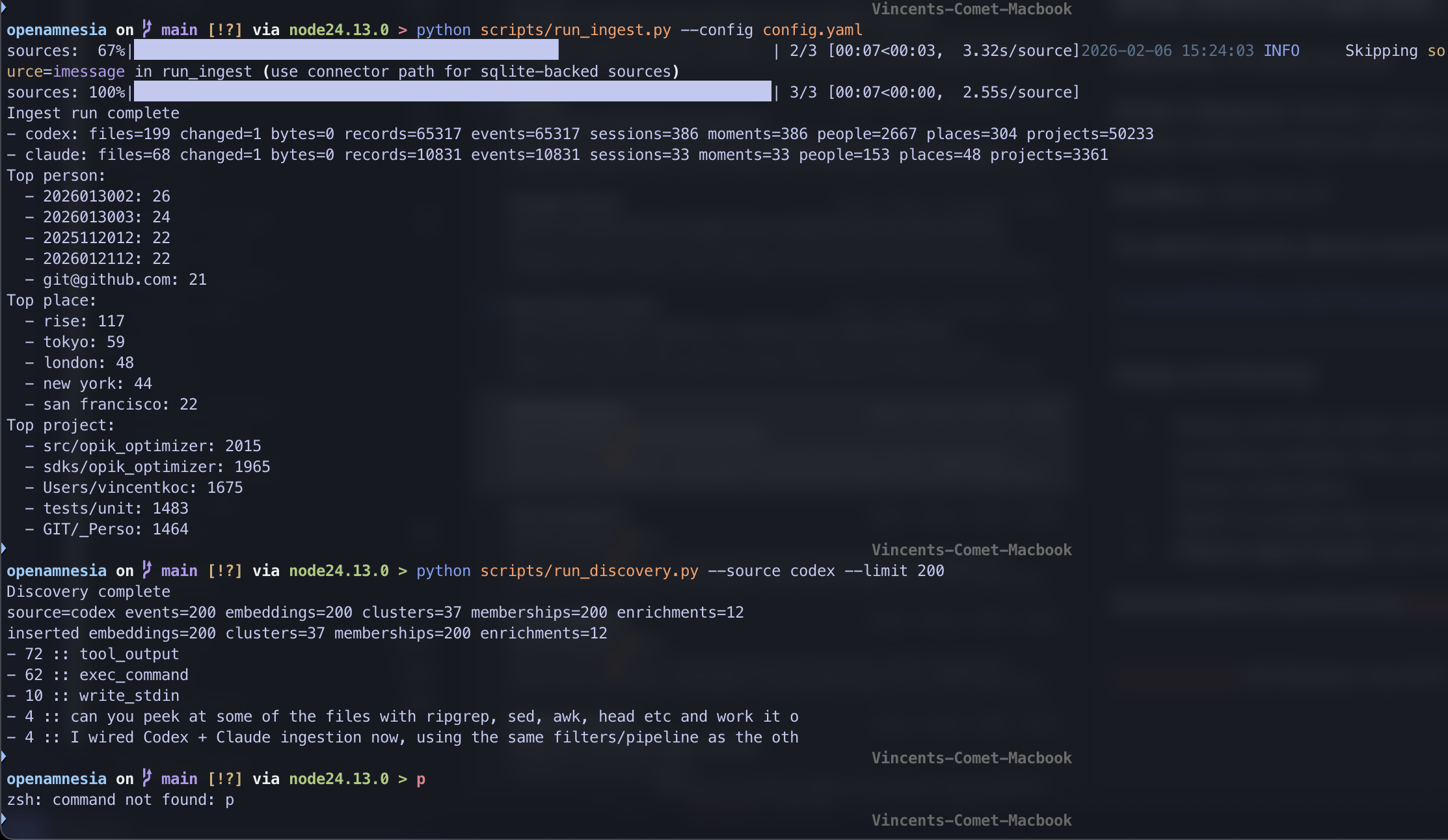
SDK debug output showing codex and coding agent output
Inspiration
Agents are only as good as their context—but most context lives in scattered traces: coding agent sessions, IDE chats, tool calls, and personal messages. We wanted a continual learning context engine that can securely extract memory from real activity, so agents can cold-start with high-signal history and stay current as your projects evolve.
Open Amnesia is our answer: a local-first “memory stream” that turns messy session logs into structured moments, facts, and skills automatically. And this can run on a continoual loop without having to wire all your sensitive data to agents like OpenClawd and others.
What it does
Open Amnesia ingests multi-source logs (e.g., Codex, Claude, iMessage, Discord, Whatsapp based on localstoage on your machine no APIs used) and transforms them into a structured memory layer:
- Normalizes heterogeneous session formats into a single event schema
- Segments activity into “moments” (intent → actions/tool calls → outcomes → artifacts)
- Clusters + summarizes sessions into high-signal timelines (per day/week/month)
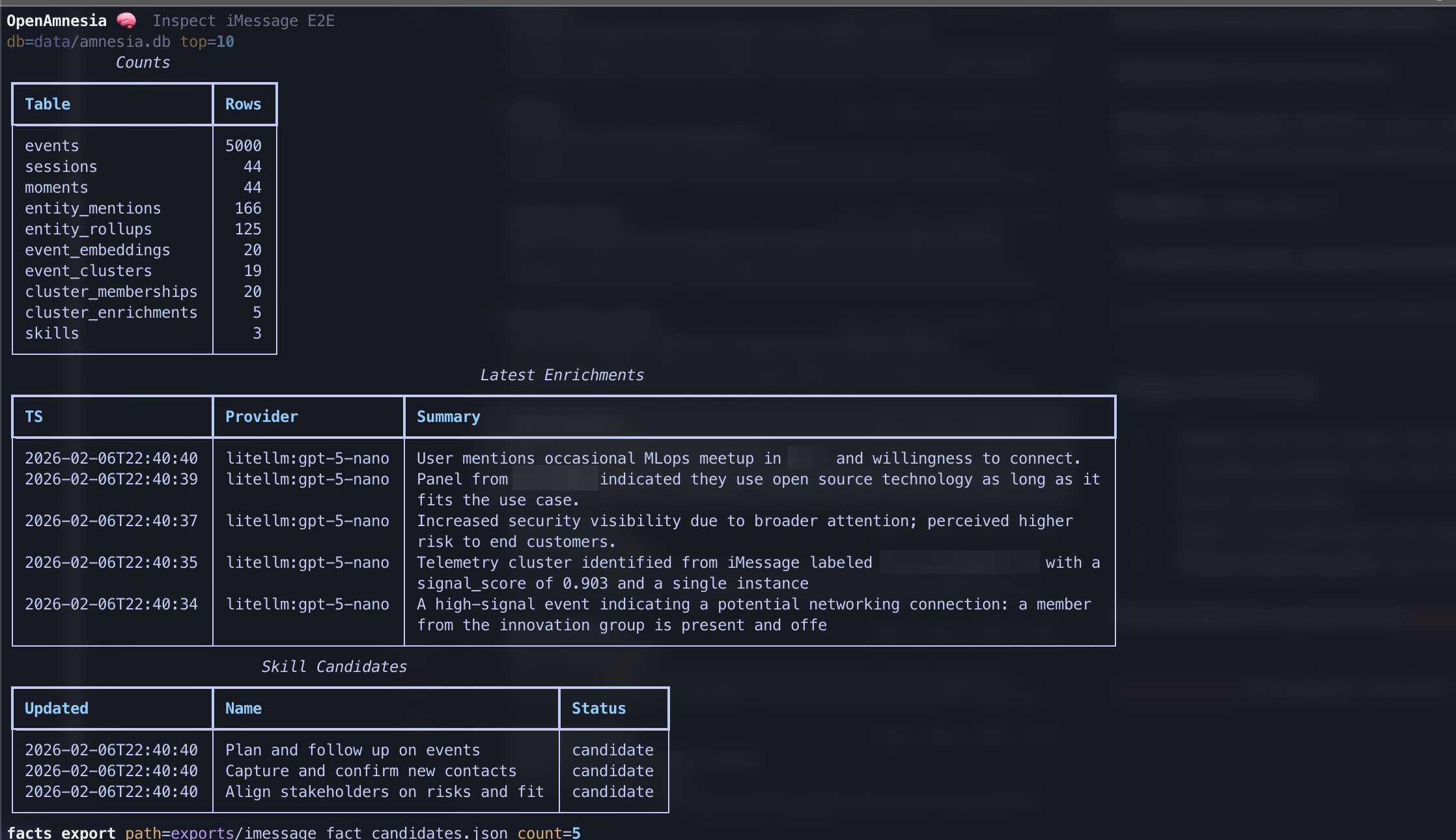
- Extracts candidates for: Facts (stable context: projects, decisions, people, configs) and Skills (repeatable workflows: triggers, steps, checks)
- Exports: Date-based memory files (
YYYY_MM_DD.md) for PKM/agents, JSON + HTTP endpoints so any agent/runtime can fetch context on demand and SKILL.md for skills built with Composio
Result: a privacy-preserving cold start + continual update pipeline for personal and project agents which can be deployed onto Render and/or Akash. Skills engine can also be served as an MCP layer as well as the moments.
How I (Vincent) built it
I built a local-first pipeline designed for determinism and reprocessing:
- Connectors ingest logs from different sources (Codex, Claude, iMessage)
- Filters + redaction clean and scope data (time ranges, project tags, secret/PII patterns)
- Normalization converts everything into a stable Event IR (turn-by-turn with tool call/result structure)
- Sessionization + clustering groups events into coherent moments and threads
- Enrichment (LLM-assisted summaries + extraction) runs only after deterministic preprocessing
- Storage lands in SQLite as the system-of-record
- Serving layer exposes read-only context via a FastAPI API
- UI (React) provides inspection, filtering, and export controls
Memory is exported daily/weekly/monthly in consistent templates so downstream agents can reliably consume it and this is configurable.
Challenges we ran into
- Schema normalization: each source logs “turns” differently (tool calls, metadata, timestamps, nesting)
- Deterministic grouping: making time/project filters behave consistently across connectors
- LLM noise + token budgets: enrichment is expensive and can amplify messy clusters if run too early
- Deduplication: avoiding repeated banners, retries, and tool spam creating low-quality memories
- Privacy constraints: extracting value while respecting local-first + redaction requirements
Accomplishments that we're proud of
- End-to-end ingestion from three real sources (Codex, Claude, iMessage)
- Stable Event IR → Moment → Memory → Skill Generation kiio pipeline with reproducible outputs
- Date-based memory exports plus a clean read-only API for agent consumption
- Tool call/result extraction that preserves evidence and artifacts (diffs, commands, links)
- Practical filtering: by time window and “project group” for multi-project workflows
What we learned
Data consistency beats prompt cleverness. The quality of agent memory depends on stable, deterministic preprocessing—normalization, filtering, and deduplication—before any LLM step. Once the “shape” of the data is reliable, extraction and summarization become dramatically better and cheaper.
What's next for Open Amnesia
- Continual learning loops: friction signals → skills → eval → promote and learn from new moments
- Per-project memory streams and timeline “playback” UI
- Skill Gym: auto-generate and manage skills as versioned artifacts (triggers/steps/checks/metrics)
- Sponsor integrations as modules:
- You.com for grounded enrichment and fresh context
- Composio for actions (create issues, post summaries, update docs)
- A third integration for deployment/compute/voice, depending on workflow
- Local watchers + LaunchAgent for real-time ingestion (opt-in), plus stronger redaction policies
Tech stack
- Languages: Python, TypeScript
- Backend: FastAPI, SQLite
- Frontend: React, Vite, Tailwind CSS, React Router, TanStack Query
- LLM/Enrichment: LiteLLM (OpenAI models), You.com APIs, Composio
- Tooling: ruff, mypy, pytest, pre-commit

Log in or sign up for Devpost to join the conversation.