
Inspiration
Despite the advent of the information age, misinformation remains a big issue in today's day and age. Yet, mass media accessibility for newer language speakers, such as younger children or recent immigrants, remains lacking. We want these people to be able to do their own research on various news topics easily and reliably, without being limited by their understanding of the language.
What it does
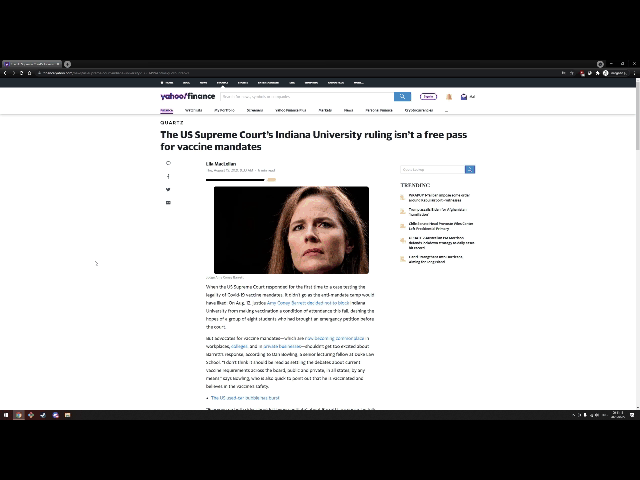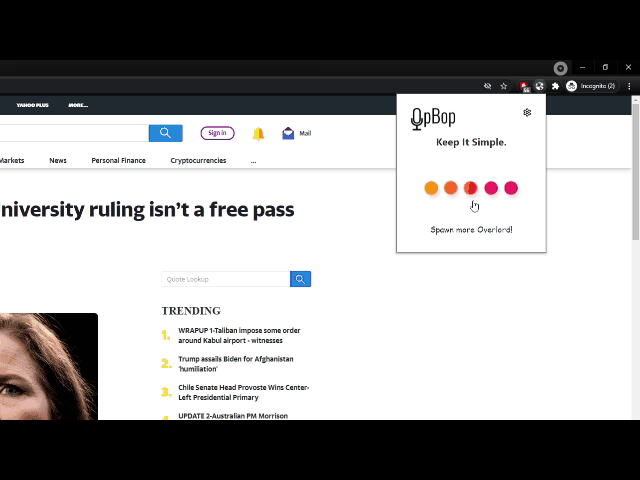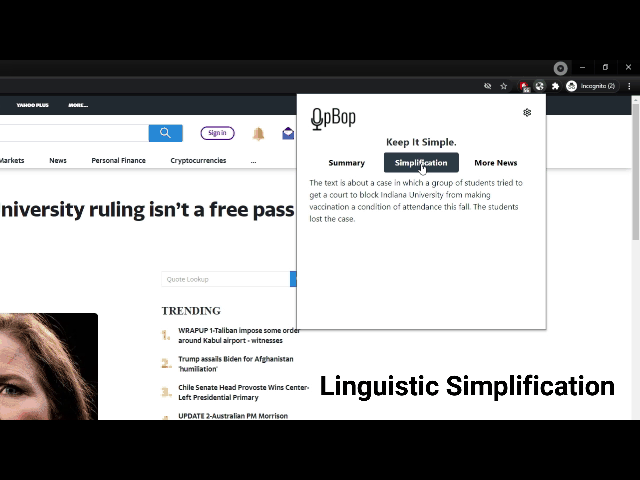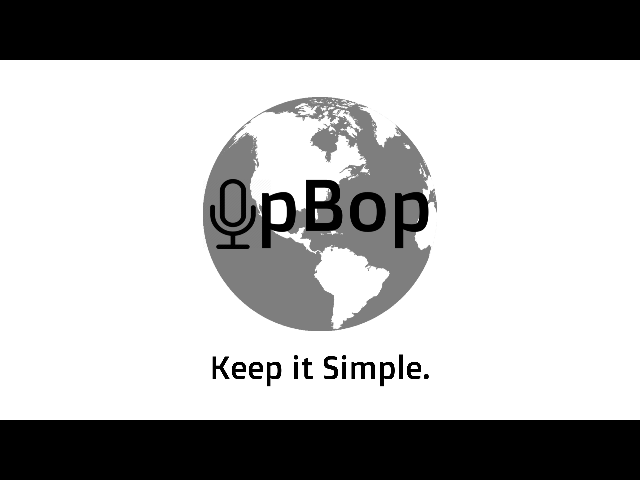
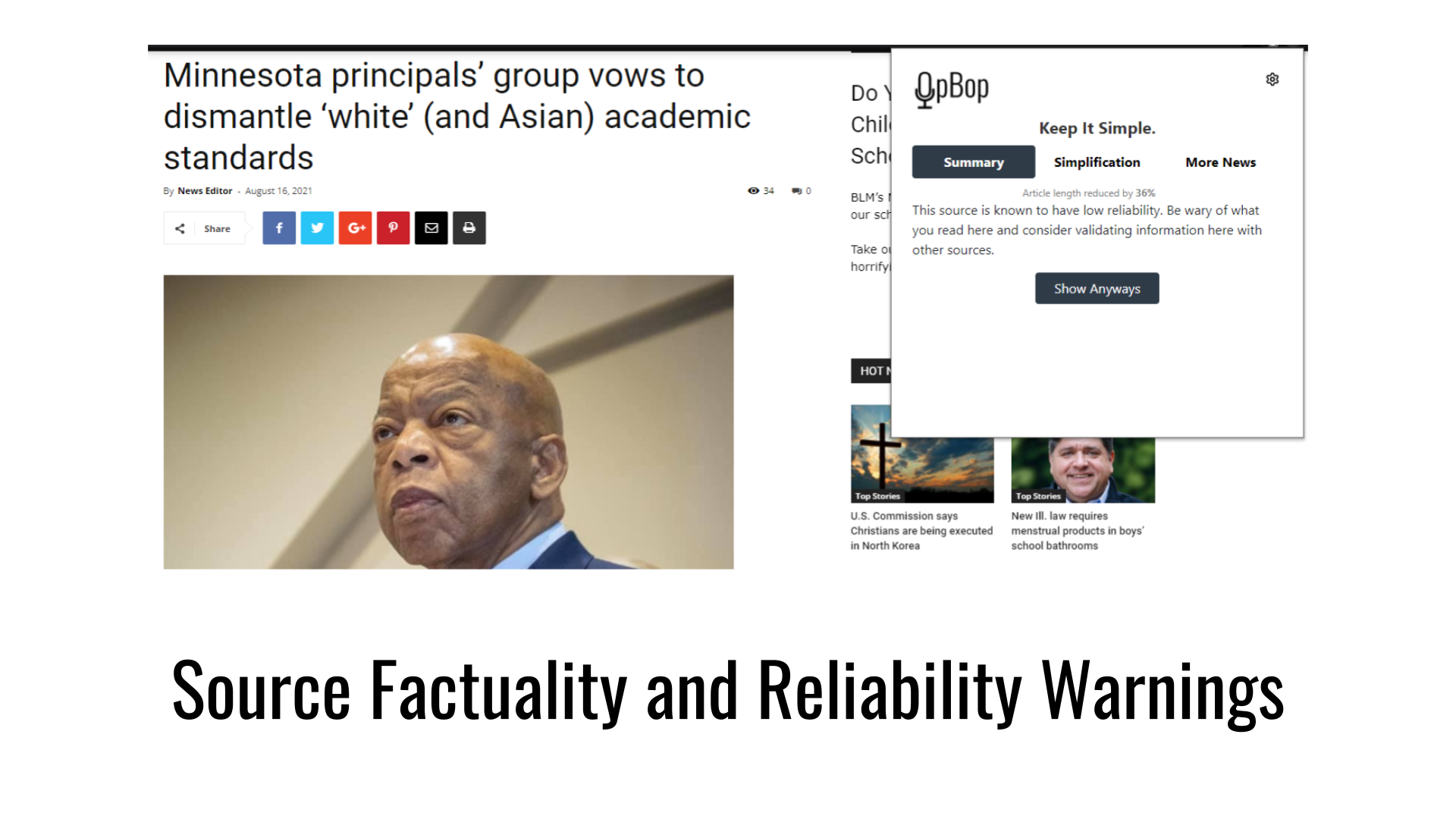
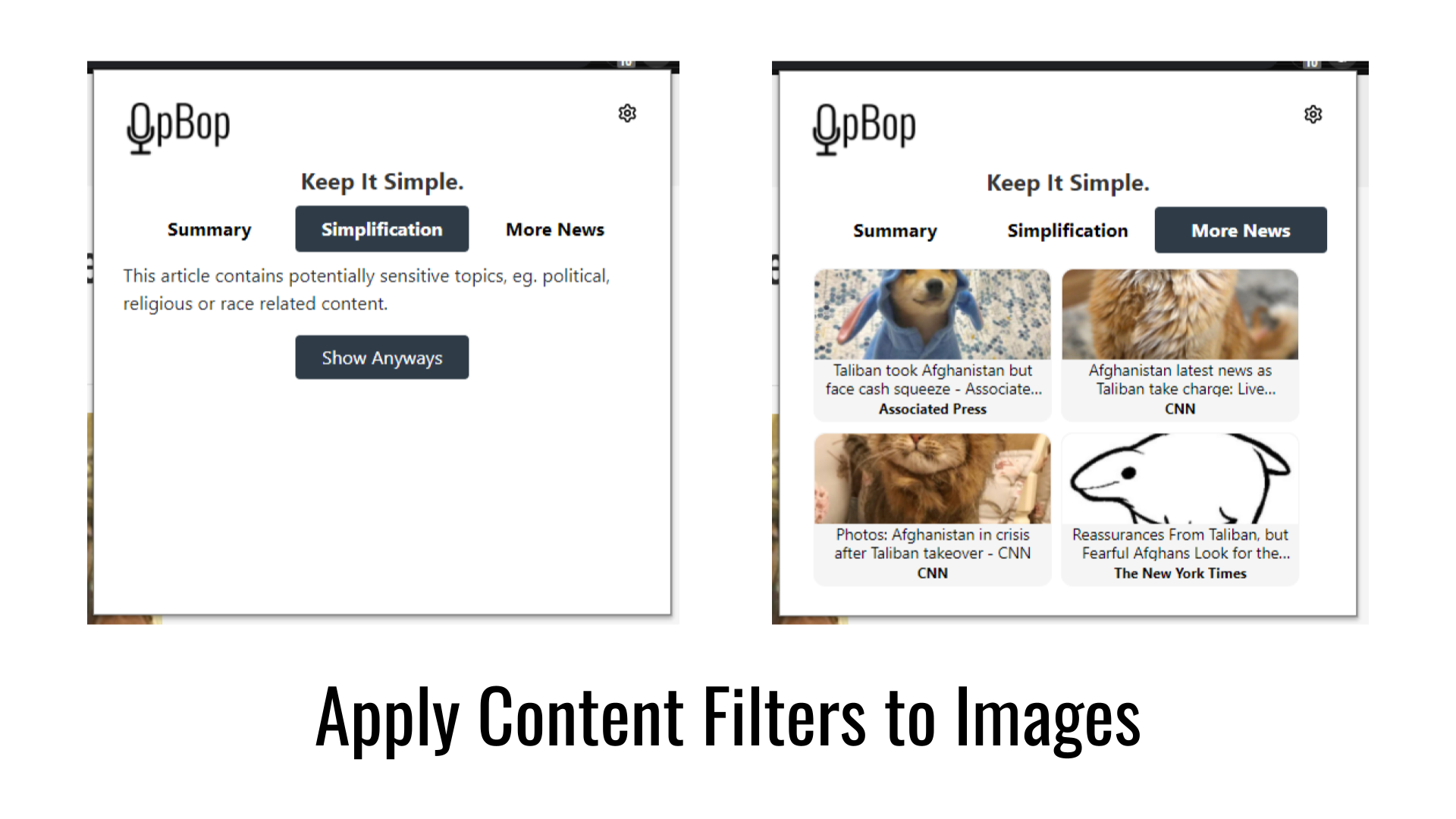
Our Chrome extension allows users to shorten and simplify and any article of text to a basic reading level. Additionally, if a user is not interested in reading the entire article, it comes with a tl;dr feature. Lastly, if a user finds the article interesting, our extension will find and link related articles that the user may wish to read later. We also include warnings to the user if the content of the article contains potentially sensitive topics, or comes from a source that is known to be unreliable.
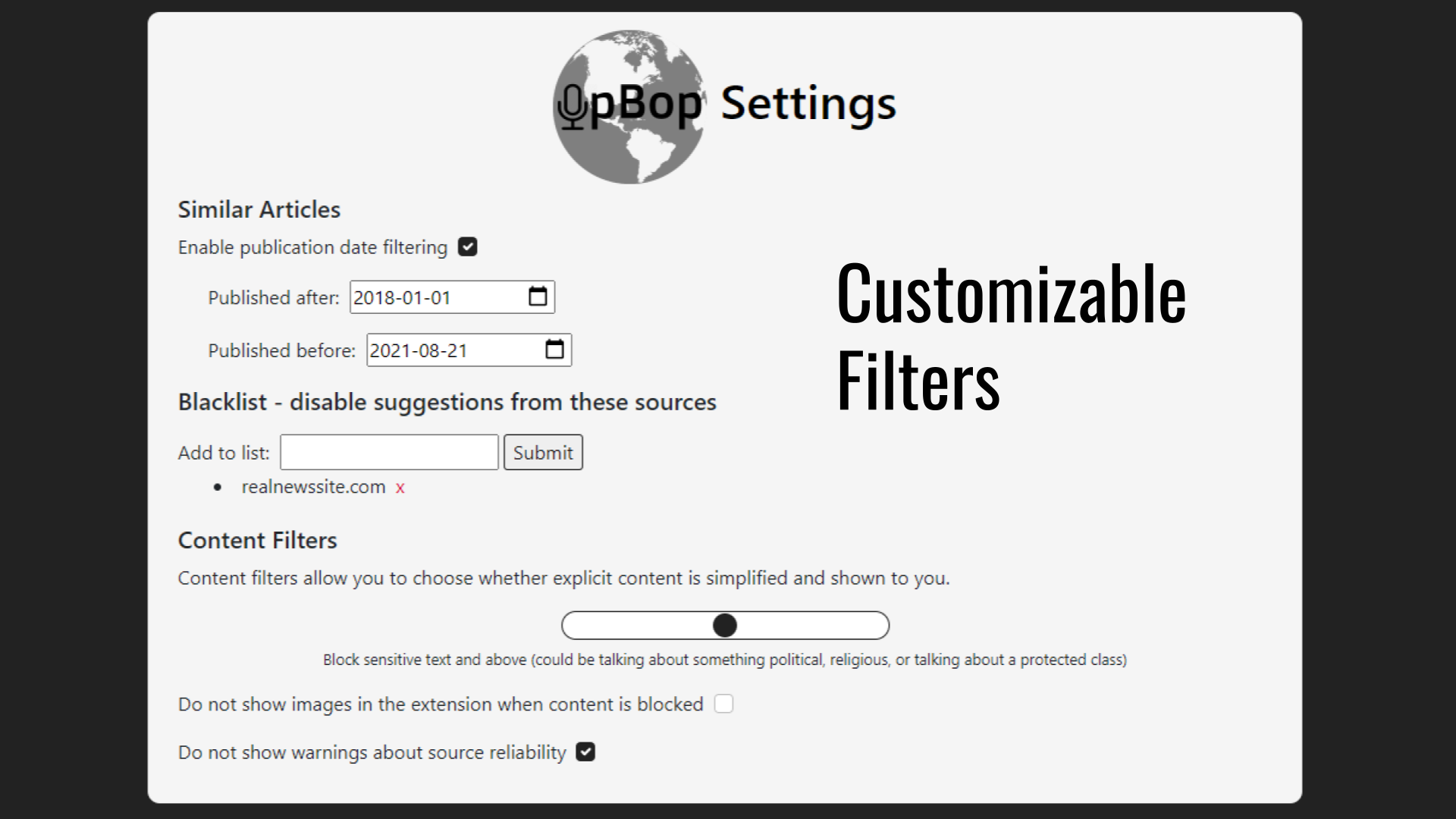
Inside of the settings menu, users can choose a range of dates for the related articles which our extension finds. Additionally, users can also disable the extension from working on articles that feature explicit or political content, alongside being able to disable thumbnail images for related articles if they do not wish to view such content.
How we built it
The front-end Chrome extension was developed in pure HTML, CSS and JavaScript. The CSS was done with the help of Bootstrap, but still mostly written on our own. The front-end communicates with the back-end using REST API calls.
The back-end server was built using Flask, which is where we handled all of our web scraping and natural language processing.
We implemented text summaries using various NLP techniques (SMMRY, TF-IDF), which were then fed into the OpenAI API in order to generate a simplified version of the summary. Source reliability was determined using a combination of research data provided by Ad Fontes Media and Media Bias Check.
To save time (and spend less on API tokens), parsed articles are saved in a MongoDB database, which acts as a cache and saves considerable time by skipping all the NLP for previously processed news articles.
Finally, GitHub Actions was used to automate our builds and deployments to Heroku, which hosted our server.
Challenges we ran into
Heroku was having issues with API keys, causing very confusing errors which took a significant amount of time to debug.
In regards to web scraping, news websites have wildly different formatting which made extracting the article's main text difficult to generalize across different sites. This difficulty was compounded by the closure of many prevalent APIs in this field, such as Google News API which shut down in 2011.
We also faced challenges with tuning the prompts in our requests to OpenAI to generate the output we were expecting. A significant amount of work done in the Flask server is pre-processing the article's text, in order to feed OpenAI a more suitable prompt, while retaining the meaning.
Accomplishments that we're proud of
This was everyone on our team's first time creating a Google Chrome extension, and we felt that we were successful at it. Additionally, we are happy that our first attempt at NLP was relatively successful, since none of us have had any prior experience with NLP.
Finally, we slept at a Hackathon for the first time, so that's pretty cool.
What we learned
We gained knowledge of how to build a Chrome extension, as well as various natural language processing techniques.
What's next for OpBop
Increasing the types of text that can be simplified, such as academic articles. Making summaries and simplifications more accurate to what a human would produce.
Improving the hit rate of the cache by web crawling and scraping new articles while idle.



Log in or sign up for Devpost to join the conversation.