

Onkos
Inspiration
Oncologists are drowning. The average oncologist sees 50+ patients a week, each with a folder of PDFs, scans, and lab CSVs that have to be read, reconciled, and turned into a treatment plan that holds up against NCCN guidelines and the latest literature. Then they have to figure out if any active clinical trial fits the patient, and where the nearest site is. We watched a family member go through this on the patient side and realized the bottleneck wasn't medical knowledge, it was time and synthesis. We wanted to build the tool we wished existed for them: something that reads everything, reasons through it, and hands the oncologist a starting point in 90 seconds.
What it does
Onkos is cursor for oncologists. Drop a folder of messy patient records (PDFs, scanned pathology reports, intake CSVs, imaging notes) and it:
- Extracts every oncology-relevant field (diagnosis, stage, biomarkers, mutations, ECOG, prior therapies) using a vision language model for scanned pages and Kimi-K2 for the structured cleanup.
- Walks an NCCN-grounded treatment railway with K2-Think v2, streaming the model's reasoning live so the oncologist can watch it think through each decision node, with every recommendation grounded in PubMed citations from a Chroma RAG corpus.
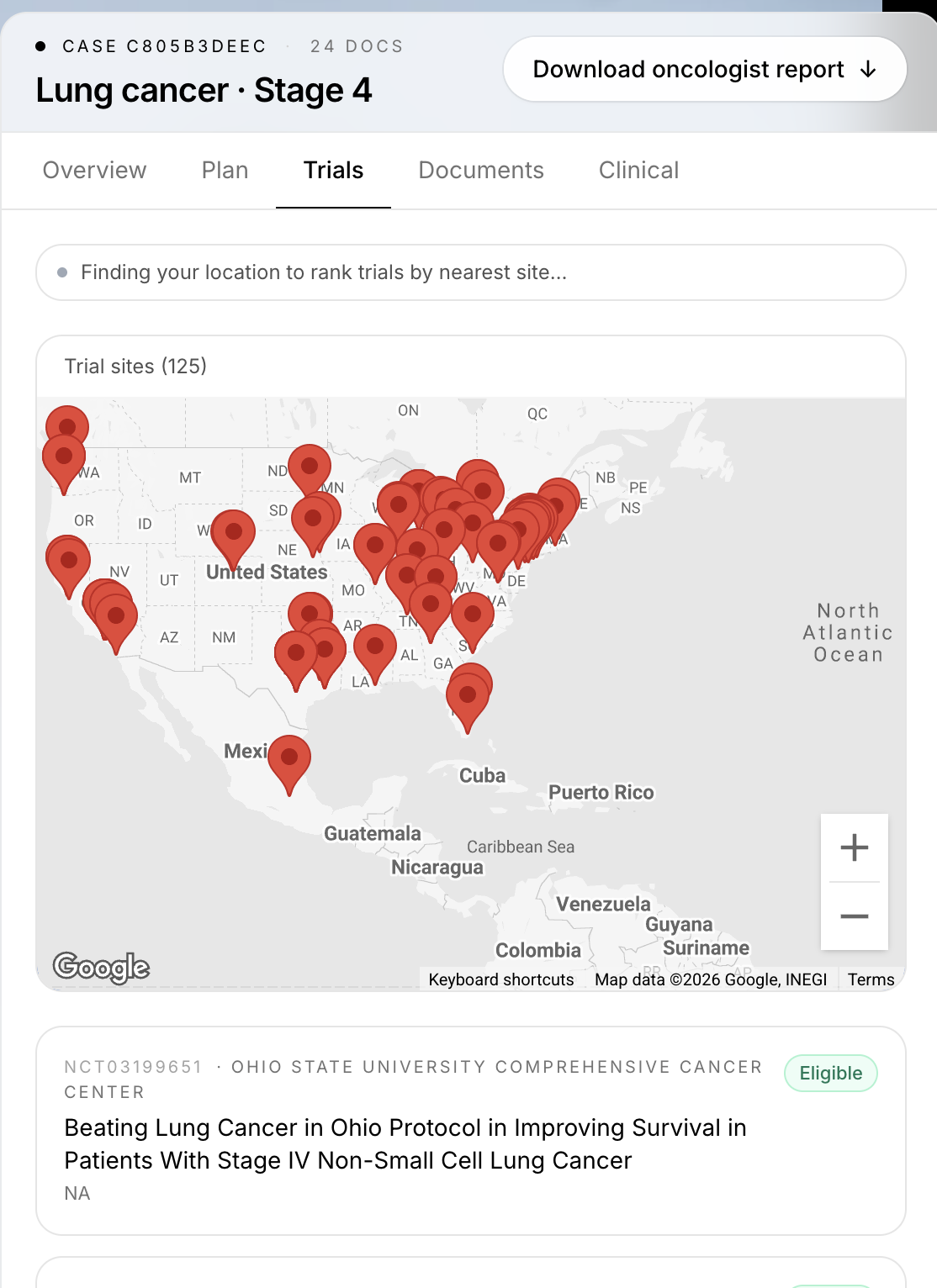
- Matches Regeneron-sponsored clinical trials against the patient using structured eligibility predicates, then geocodes recruiting sites on a Google Map so the oncologist can see the nearest options instantly.
- Generates a downloadable oncologist report with diagnosis, plan, citations, and trial matches, ready to drop into the chart.
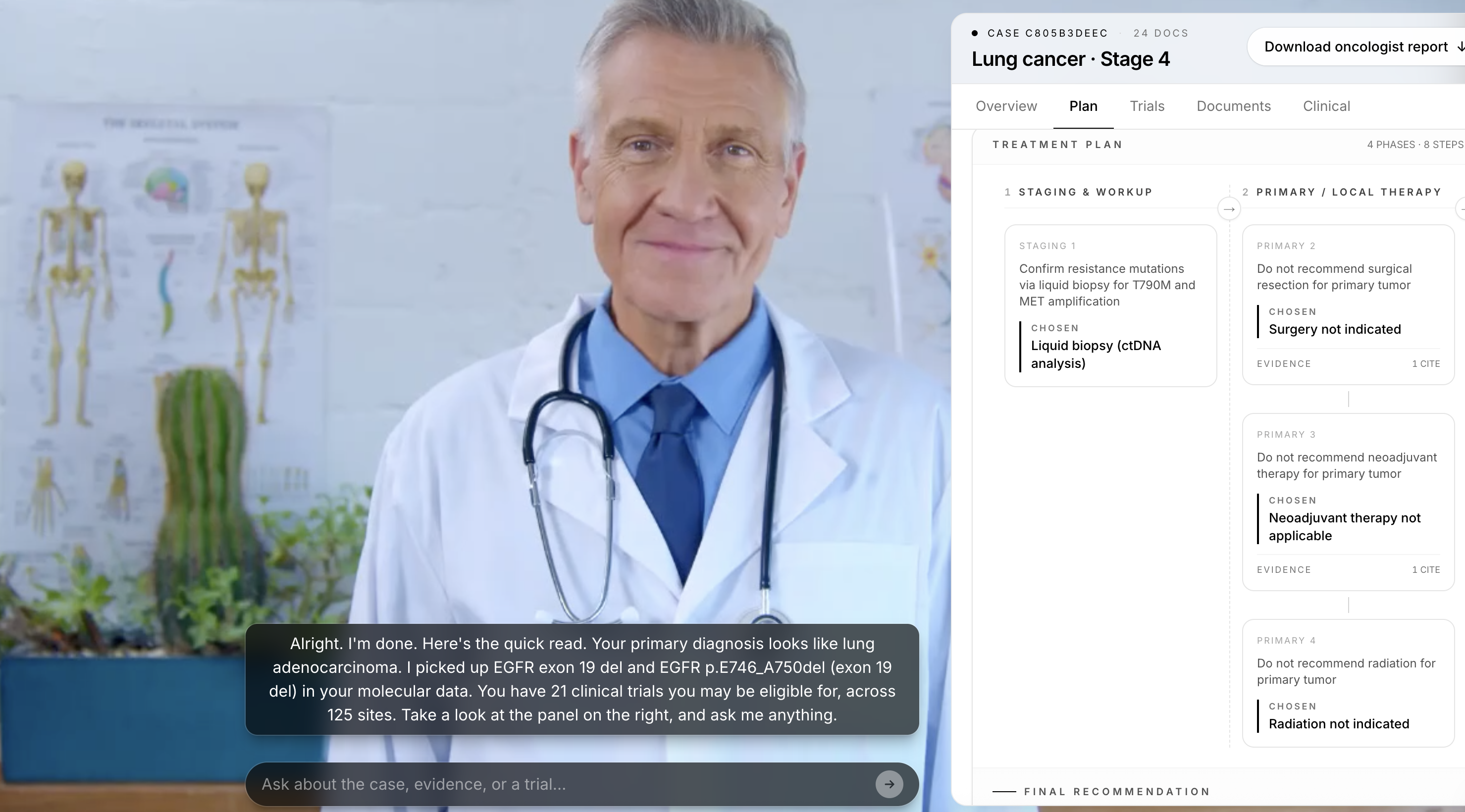
- Drives a live avatar doctor powered by Kimi-K2: the oncologist talks to a video avatar, asks "why this drug?" and Kimi answers AND navigates the UI for them via tool calls.
There's also a patient view at /patient that retells the same case data in plain English: "Your diagnosis," "Your plan," "How to heal," "Next steps," and "Questions to ask your oncologist." Same backend, same SSE stream, different audience.
For the Regeneron Track
Onkos was built with the Regeneron pipeline as the first-class trial source. Every design decision, every data source, every model call flows through the question "does this help a Regeneron trial get filled faster and with fewer screen-fails." In total we:
Scraped the entire Regeneron oncology trial registry off ClinicalTrials.gov v2, live. The scripts/scrape_regeneron_trials.py script hits the official ClinicalTrials.gov REST v2 API, filters for Regeneron as sponsor or collaborator, pulls every recruiting oncology study, and emits one Python file per trial under backend/src/neoantigen/external/regeneron/. As of our April 2026 scrape we ship 29 recruiting Regeneron-sponsored trials wired into the matcher, not the four we started with. Each file captures the real NCT ID, phase, enrollment status, AJCC-grounded inclusion/exclusion criteria verbatim, mapped cancer types, and a structured TrialRule object. Re-running the scraper refreshes the entire registry in one command, so the pipeline stays current with whatever Regeneron has recruiting on any given day.
We built a real structured eligibility engine, not regex over free text. Clinical trial criteria are deceptively adversarial: "no prior anti-PD-1 within 6 months" or "ECOG ≤1 with measurable disease per RECIST v1.1" cannot be matched with keyword search. So we built evaluate_all in regeneron_rules.py, a rules engine that evaluates every patient case against every Regeneron trial across a library of typed predicates:
- Stage and histology gates: AJCC 8th-edition T-stage buckets (T3a/T3b/T4a/T4b for advanced, T2b+ for high-risk resectable), unresectable vs. metastatic, histological confirmation, exclusion of uveal/acral/mucosal subtypes.
- Biomarker gates: BRAF V600E/K, EGFR mutation + T790M, ALK fusion, ROS1 fusion, MET exon 14, KRAS G12C, HER2 positive/low, BRCA, MSI-high, PD-L1 with a minimum TPS threshold, LAG-3 IHC status. Each marked
required,excluded, oranyper trial. - Treatment history gates: prior systemic therapy for advanced disease, prior anti-PD-(L)1 specifically, prior checkpoint inhibitors other than anti-PD-(L)1, washout windows.
- Performance status gates: ECOG 0–1, measurable disease per RECIST v1.1, minimum life expectancy in months.
- Demographic gates: min/max age bounds per trial.
Every gate returns a verdict of pass, fail, or needs_more_data, and the trial card shows exactly which gates are green, red, or unresolved. A coordinator looking at a patient gets a ranked match list with a to-do of "ask the patient these three things and you'll know for sure," which is the single highest-leverage intervention against screen-fail rate.
We geocode every Regeneron site on a live Google Map. external/trial_sites.py pulls the official site list for each matched trial from ClinicalTrials.gov and geocodes every address through the Google Maps Geocoding API server-side, with results cached to disk. The frontend's TrialMap renders the recruiting sites as clickable pins next to the trial card, so the second question an oncologist asks ("where's the nearest site") is answered before they can type it.
We ground every recommendation in real PubMed literature. The rag/store.py layer runs a ChromaDB corpus built by scripts/build_pubmed_rag.py, seeded off NCBI E-utilities with topic queries across the Regeneron-relevant universe: BRAF V600E, NRAS Q61, KIT, NF1, anti-PD-1, anti-LAG-3, TMB, AJCC staging, neoadjuvant melanoma, brain mets, and beyond. Each abstract is embedded with all-MiniLM-L6-v2 and tagged with a cancer_type metadata field, so the walker's top-K retrieval is filtered to the patient's actual tumor type.
The NCCN walker itself is Regeneron-aware. The dynamic walker in nccn/dynamic_walker.py runs a four-phase decision graph (staging, primary, systemic, followup), and at the systemic-therapy phase it cross-references the matched Regeneron trials so checkpoint-inhibitor combinations that are already under investigation at Regeneron surface inside the plan.
Every case produces a downloadable Regeneron-ready report. report/pdf_report.build_report_pdf uses ReportLab to render a full oncologist report: diagnosis, staging, biomarkers, mutations, the walked NCCN plan with PubMed citations, and the ranked Regeneron trial matches with each eligibility gate annotated pass / fail / needs_more_data.
Real-world PDF intake. Our pipeline emulates the messy documents oncology actually generates: scanned pathology reports, faxed imaging notes, intake CSVs with missing fields. io/pdf_extract.py tries pypdf first, falls back to pdf2image + the self-hosted MediX-R1-30B VLM on scanned pages, and routes the raw extract through Kimi for structured cleanup into the PathologyFindings, ClinicianIntake, and Mutation[] schemas. The test fixtures in backend/test_fixtures/ are a full real-world case (pathology, imaging, chemo PDFs, ground-truth JSON), and the pipeline chews through it end to end.
Readiness. The repo ships under MIT on GitHub. Setup is two commands: pip install -e './backend[agent,web,pdf-vision,rag]' and npm install. Every external dependency (K2-Think, Kimi, MediX VLM, Google Maps, the RAG corpus) has a documented env var and a silent fallback path so the app runs end to end with whatever credentials are present. CORS, env config, and the /api/* proxy layer are all production-ready. The /api/health endpoint reports which optional dependencies are wired up so an ops team knows exactly what's live.
Utility. The bottleneck Onkos targets is the synthesis step between "patient walks in" and "patient enrolled in a trial." For a Regeneron trial coordinator, this means automated pre-screening: instead of a clinician manually checking 12+ eligibility criteria across a folder of PDFs for every one of 29 active trials, the system surfaces a ranked match list with each gate marked pass / fail / needs_more_data, telling the coordinator exactly what intake question to ask next. This directly attacks the single biggest cost driver in oncology trial enrollment, the screen-fail rate, and it does it in seconds instead of hours.
Design. The cockpit is built around the oncologist's mental model, not the model's output. Five tabs map to the five questions an oncologist actually asks: who is this patient (Overview), what should we do (Plan), what trials fit (Trials), where did this come from (Documents), what are the raw fields (Clinical). The avatar handles the "why" follow-ups.
Relevance. The registry covers the real Regeneron investigational pipeline: cemiplimab (Libtayo) combinations, fianlimab (anti-LAG-3) melanoma trials including Harmony and Harmony Head-to-Head, the BNT111 fixed-antigen vaccine partnership with BioNTech, plus ubamatamab, odronextamab, and the broader bispecific antibody program. The trial registry lives in backend/src/neoantigen/external/regeneron/ as 29 generated files, and adding a new trial is literally one scraper re-run away. The geocoded site map, the oncologist PDF report, the Kimi-driven avatar tour, and the patient-facing plain-English view all light up the moment a new trial lands.
Packaging. README, CLAUDE.md, and backend/CLAUDE.md document the architecture, env vars, request flow, silent-fallback table, every event kind on the SSE bus, and where every model call is logged. The codebase is heavily commented at the architectural level (request flow, event bus, dual frontend views, scraper provenance). Demo video, slide deck, and the full test-fixture case accompany the submission.
For the Best Use of Kimi-K2 Track
We use Kimi-K2 in the role it's strongest at: a tool-calling, agentic conversational layer that actually orchestrates a UI, grounds itself in retrieved literature, and speaks out loud, not just a text generator.
The avatar is Kimi, and it talks. A HeyGen LiveAvatar handles the video and lip sync, but its built-in LLM is fully disabled. Every word the avatar speaks is generated by Kimi-K2 first, then piped to HeyGen as pure TTS. The oncologist can talk to the avatar with voice, hear Kimi's answer spoken back in real time, and watch the UI update while the avatar is still mid-sentence. HeyGen's default brain is generic. Kimi-K2 is the one that actually knows the patient's case, the NCCN plan, and the trial registry, so Kimi is the one that speaks.
Agentic tool calling drives the cockpit. Kimi is wired through LangGraph as a real agent with conversation memory, not a single-shot chat endpoint. It has access to a chat_ui_focus tool that lets it change tabs, focus a specific trial by NCT ID, or scroll the railway to a specific node. When an oncologist asks "show me the trial in Boston," Kimi both answers ("That's NCT12345, recruiting at Dana-Farber") and emits a tool call that updates the URL to ?tab=trials&nct=12345. The avatar feels like a copilot because Kimi is literally driving the UI while speaking.
RAG-grounded answers, not hallucinations. Kimi is backed by a ChromaDB + sentence-transformers PubMed RAG corpus that the NCCN walker also pulls from. When the oncologist asks "why cemiplimab here," Kimi retrieves the relevant PubMed abstracts that grounded the recommendation in the first place and quotes them back with citations. No made-up drug names, no hallucinated trial IDs, every clinical claim traces back to a real paper.
Tools never mutate state. Every Kimi tool returns either a UI focus hint or a short string the model can keep reasoning over. Case data is immutable from the chat layer's perspective. This means the oncologist can fully trust what they see on screen, the avatar can guide them but cannot rewrite their patient's record.
We went off-the-shelf with MBZUAI's full model family, and this is the part we're loudest about. Kimi-K2 is built by Moonshot, but we didn't stop there. We pulled in MBZUAI's own models straight off Hugging Face and stood them up ourselves:
- MediX-R1-30B VLM from MBZUAI, a 30-billion-parameter medical vision language model we self-hosted on a GH200 GPU via vLLM over an SSH tunnel. This is not a hosted API call, we ran the weights. It reads scanned pathology PDFs that pure-text extraction misses and is what lets us handle real-world clinical document chaos instead of clean digital records.
- K2-Think v2 from MBZUAI walks the NCCN treatment railway, with
<think>tokens streamed live to the UI for full reasoning transparency. - Kimi-K2 (chat + tools + voice) is the layer the user actually talks to, wired through LangGraph for proper agent orchestration with conversation memory and RAG retrieval.
Pulling a university research VLM off the shelf, getting it serving on a GH200 in tmux, keeping the tunnel alive, and fronting it with Kimi-K2 as the agentic interface is the flex. Each model does what it's best at, and the user experiences them as a single coherent assistant they can literally talk to. That stack, plus the streaming UX, voice, RAG, and agentic tool calling, is our answer to "best use of Kimi-K2": not a chatbot, but a grounded, voiced, agentic conversational layer that actually controls the application.
How we built it
Backend is a Python 3.11 package (neoantigen) with a Typer CLI and a FastAPI app served over SSE. The orchestrator is a single PatientOrchestrator that runs the pipeline asynchronously, publishing every step on an event bus that the frontend subscribes to.
Frontend is Next.js 15 with Tailwind. The case page is a two-pane cockpit: avatar on the left, a five-tab data panel on the right (Overview, Plan, Trials, Documents, Clinical), with the active tab URL-synced so the avatar can navigate programmatically.
Model stack:
- MediX-R1-30B VLM from MBZUAI, self-hosted on a GH200 GPU via vLLM, for reading scanned pathology PDFs.
- K2-Think v2 from MBZUAI for the NCCN treatment reasoning, with
<think>blocks streamed to the UI so users can watch the model deliberate. - Kimi-K2 as the conversational brain with tool calling, wired through LangGraph, driving the avatar.
Other pieces: ChromaDB + sentence-transformers for the PubMed RAG layer, Google Maps for trial site geocoding, ReportLab for the oncologist PDF, HeyGen for the live avatar video stream.
Challenges we ran into
Hosting a 30B vision language model on a GH200 over an SSH tunnel and keeping it stable during a demo was the hardest infra problem. We had to keep vllm serve alive in tmux, the SSH tunnel up in another terminal, and make the backend silently degrade when either dropped.
Wrangling K2-Think's <think> token stream into discrete UI events without buffering the whole response took a custom stream_with_thinking wrapper.
Getting Kimi-K2's tool calls to drive the frontend cleanly (without letting HeyGen's built-in LLM hijack the conversation) required disabling HeyGen's brain entirely and treating the avatar as a pure TTS puppet that just speaks whatever Kimi generates.
The Regeneron eligibility logic was deceptively hard. Trial criteria like "no prior anti-PD-1 within 6 months" need structured predicates, not regex on free text, so we built an evaluate_all rules engine that returns pass / fail / needs_more_data per gate so the oncologist knows exactly what to chase.
Accomplishments that we're proud of
The pipeline is fully streaming end to end: a user drops a PDF and within seconds they see fields extracting, the railway building node by node, trials populating, and the avatar starting to talk, all without page reloads.
The dual oncologist + patient view from a single backend was something we scoped on day two and actually shipped. Same case data, two completely different audiences, one URL toggle.
We got the avatar to actually drive the UI. Kimi emits chat_ui_focus tool calls, the frontend interprets them as URL changes, and the right tab/trial smoothly comes into focus while the avatar is mid-sentence. It feels like a copilot, not a chatbot.
Every clinical recommendation traces back to a PubMed citation. No hallucinated drug names, no made-up trial IDs.
What we learned
Streaming UX changes everything. The same pipeline feels 10x faster when users see progress, even if total wall time is identical.
Letting the medical model do medical reasoning and the chat model do chat (instead of forcing one model to do both) gave us better answers and faster responses on both sides.
Silent fallbacks are a hackathon superpower. The orchestrator never hard-fails: missing API key, missing RAG store, scanned PDF without pdf-vision, all degrade to needs_more_data with a logged warning. We could demo with anything missing and still have something on screen.
You cannot mock clinical trial eligibility. The criteria are too domain-specific. Structured predicates per trial, written by hand, beat any LLM-only approach we tried.
What's next for Onkos
Real EHR integration via FHIR so oncologists don't have to manually upload folders. Expanding the trial registry beyond the Regeneron trials we wired up to cover the full ClinicalTrials.gov pipeline with daily refreshes. Persistent storage (right now case state is in-memory and dies on backend restart) backed by Postgres. A proper audit log so every model call, every citation, every avatar utterance is traceable for compliance. And eventually, a tumor-board mode: multiple oncologists in the same cockpit, the avatar mediating between them.
Built With
- chromadb
- clinicaltrials.gov
- fastapi
- gh200-gpu
- git
- google-maps
- heygen-liveavatar
- javascript
- k2-think-v2
- kimi-k2
- langgraph
- mbzuai-models
- medix-r1-30b
- nccn-guidelines
- next.js-15
- node.js
- npm
- openai-sdk
- pdf2image
- pubmed
- pydantic
- python
- python-dotenv
- react
- reportlab
- sentence-transformers
- sse-(server-sent-events)
- ssh-tunneling
- tailwind-css
- tmux
- typer
- typescript
- uvicorn
- vllm





Log in or sign up for Devpost to join the conversation.