Inspiration
While building my own deep learning library and researching graph algorithms, I became fascinated by the challenge of AI explainability. Modern Large Language Models rely heavily on linear Chain-of-Thought (CoT) to solve complex problems. However, linear text is fragile: a single hallucination early in a verbose paragraph can compound, derailing the entire response.
Mathematically, if an LLM generates a linear chain of $N$ sequential reasoning steps, and each step has an independent probability $p$ of being a hallucination, the probability of a completely sound reasoning chain is strictly bounded:
$$P(\text{sound}) = (1 - p)^N$$
As $N$ grows, the likelihood of a logical collapse approaches certainty.
I realized that graphs could be used to decrease this reliance on linear CoT. By forcing the LLM to structure its reasoning as a sparse Graph Intermediate Representation (IR)—where $G = (V, E)$ represents distinct subgoals, hypotheses, and evidence—we isolate errors, reduce hallucination rates, and suddenly make the AI's "thought process" entirely observable and human-steerable. We call it One-Point-Five Sigma, because it bridges the gap between standard $1\sigma$ linear prompting and highly complex, computationally heavy $2\sigma$ agentic tree-searches.
What it does
One-Point-Five Sigma replaces black-box text reasoning with an interactive, controllable pipeline.
When a user submits a query:
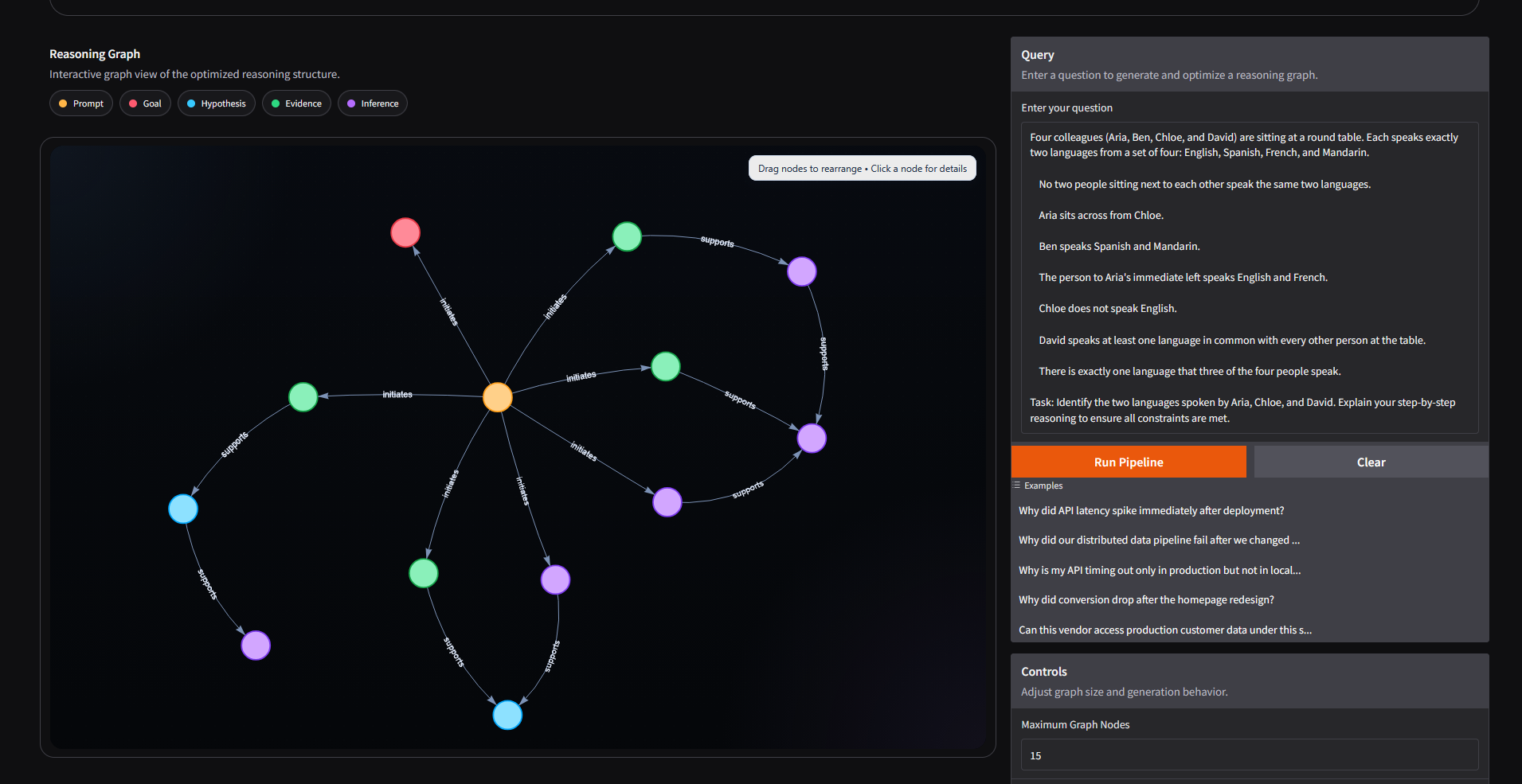
- Graph Generation: The pipeline prompts an LLM to generate a sparse JSON reasoning graph instead of a text answer. Nodes are categorized strictly by an ontology (
goal,hypothesis,evidence,inference), complete with AI-generated certainty/confidence scores (0.0 to 1.0) and relational edges (supports,depends_on). - Deterministic Optimization: Our backend prunes isolated nodes, strips generic AI filler (e.g., "think step by step"), and deduplicates parallel logic.
- Human-in-the-Loop Steering: The graph is rendered in a premium dark-mode UI. Users can visually inspect the AI's logic, click on nodes to view their certainty scores, and manually "prune" flawed hypotheses.
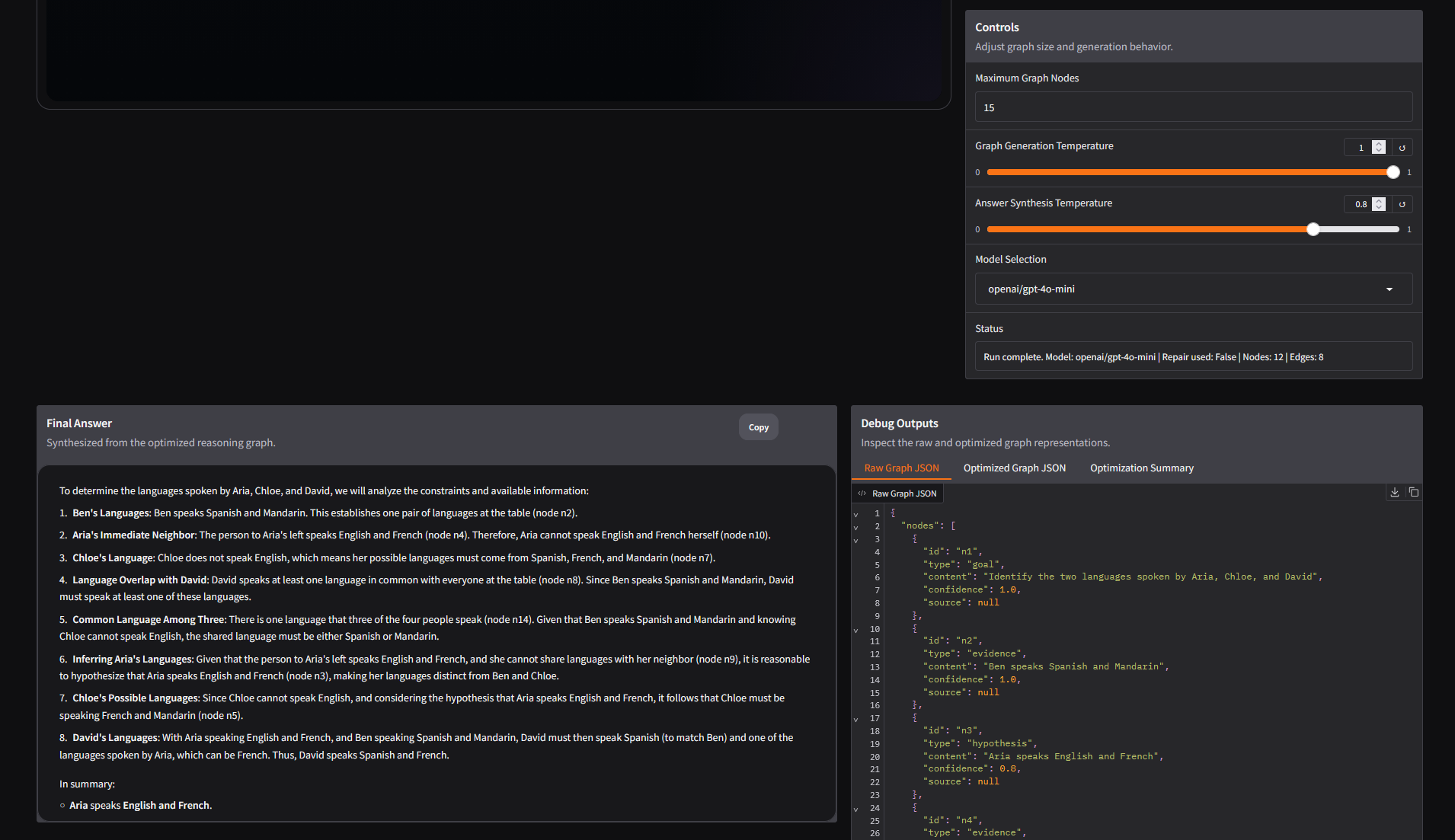
- Answer Synthesis: Once the graph is optimized (or manually adjusted), the structured graph is fed back into the LLM as rigid context to synthesize a concise, highly accurate final answer without exposing the internal ID markers to the user.
How we built it
We built the backend in Python, utilizing Pydantic to enforce strict semantic schemas for the graph ontology. We integrated the OpenRouter API to make the pipeline model-agnostic, allowing users to dynamically switch between cutting-edge models (like Qwen, Claude 3.5, GPT-4o, and Llama 3.1) to compare their graph-generation capabilities.
For the frontend, we built a custom Gradio application injected with heavy custom CSS and JavaScript. To render the graph interactively, we utilized the vis-network JS library housed within a dynamic HTML iframe. We wrote custom JS event listeners to pass postMessage signals from the iframe back into hidden Gradio textboxes, allowing frontend node-pruning to instantly trigger backend Python re-synthesis.
Challenges we ran into
- LLM Schema Adherence: LLMs desperately want to output conversational markdown instead of pure JSON. We had to heavily engineer the system prompts and ultimately build a Fallback Repair Mechanism. If the generated JSON is malformed, our pipeline catches the exception and routes the broken string to a secondary LLM specialized purely in repairing JSON schemas.
- State Synchronization: Getting a local JavaScript iframe (
vis-network) to communicate synchronously with a server-side Gradio state was notoriously difficult. We had to devise a hidden-DOM strategy to pass messages seamlessly so that when a user clicks "Prune Node," the backend actually drops the corresponding JSON dictionary and re-runs the synthesis. - Graph Instability: Initial graphs were often cluttered with isolated nodes or circular logic. We had to write a custom deterministic Python optimizer to clean the graph topology before rendering it to the user.
Accomplishments that we're proud of
- Zero-Shot Graph Generation: We successfully engineered prompts that force standard LLMs to decompose complex problems into valid nodes and directed edges without needing expensive fine-tuning.
- Self-Evaluated Certainty: Getting the models to assign realistic floating-point confidence scores ($C_i \in [0, 1]$) to their own reasoning nodes, adding a massive layer of explainability.
- The UI/UX: We pushed Gradio to its absolute limits, creating a premium, responsive, glass-morphism interface with smooth real-time graph physics that genuinely feels like a production app.
What we learned
We learned that intermediate representations (IRs) severely limit AI hallucinations. By forcing the LLM to adhere to a rigid schema.py definition, we constrain its output space. It turns out that LLMs are much better at evaluating their own logic when that logic is isolated into distinct, measurable units rather than buried in a wall of text. We also leveled up our skills in bridging Python backends with asynchronous JavaScript frontends.
What's next for One-Point-Five Sigma
- Tool Calling Integration: Expanding the ontology to include
toolnodes, allowing the graph to execute external API/DB calls to verifyhypothesisnodes with real-worldevidence. - Automated Metrics: Building an evaluation suite using graph-theoretic metrics (like centrality and density) to programmatically score how "good" a reasoning graph is.
- Multi-Agent Graph Construction: Allowing different specialized models to iteratively collaborate on building the same reasoning graph before synthesis.
Built With
- css3
- gradio
- html5
- javascript
- networkx
- openrouter

Log in or sign up for Devpost to join the conversation.