Inspiration
Liver cancer is one of the deadliest cancers worldwide, and hepatitis B is a major cause. We wanted to build a simple tool to highlight differences between HBV-driven and non-viral cases.
What it does
HepaClass classifies liver cancer patients as HBV-positive or non-viral using open data. It also shows the most important features driving the predictions.
How we built it
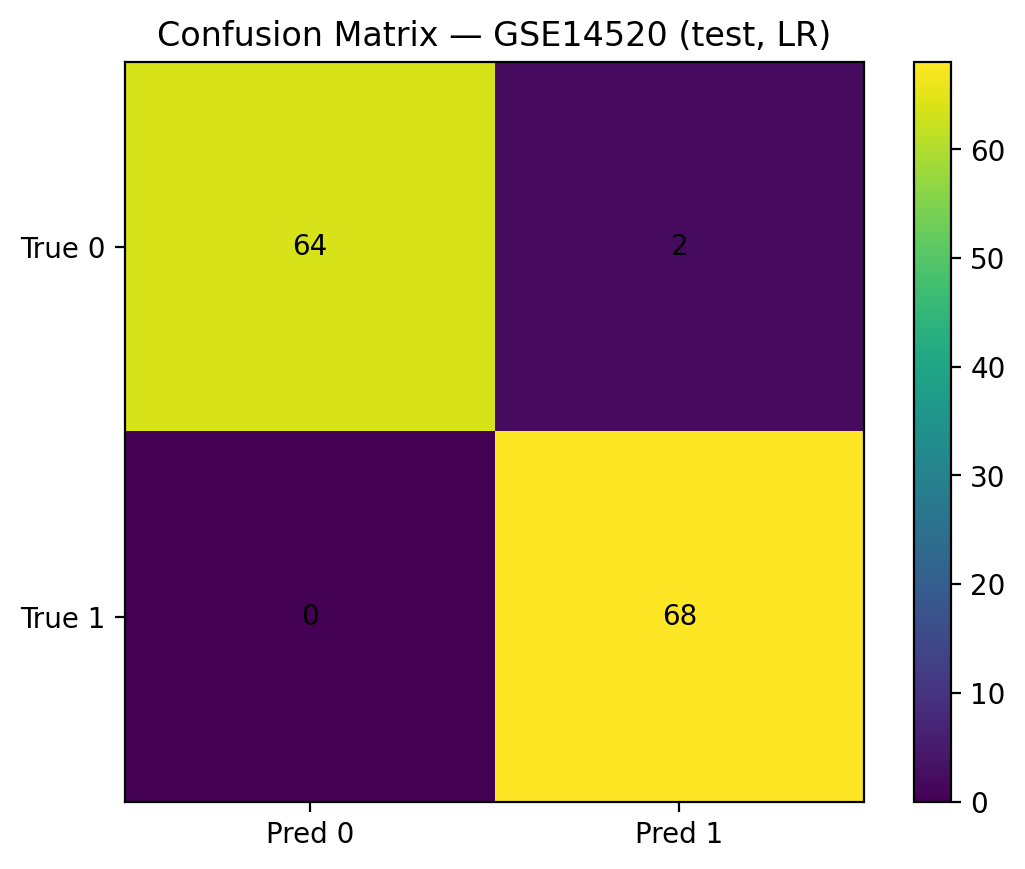
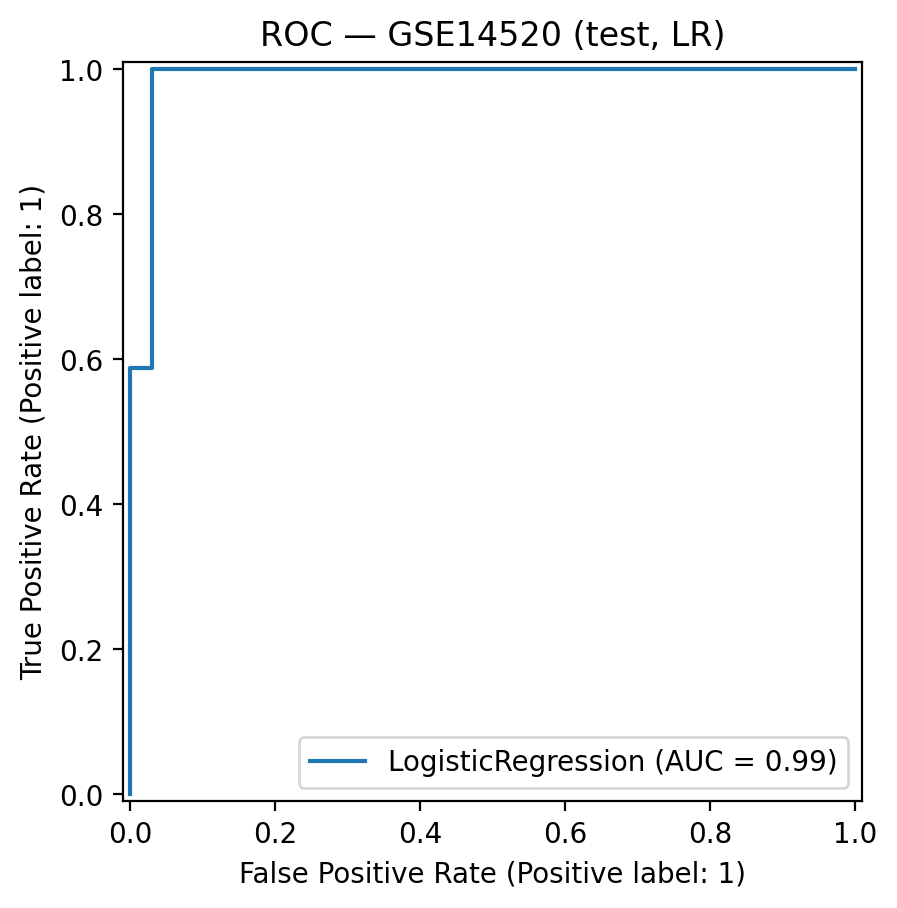
We used TCGA-LIHC data, cleaned it, and labeled patients into HBV+ vs non-viral groups. Then we trained logistic regression and random forest models and evaluated them with ROC curves, F1, and accuracy.
Challenges we ran into
We had to carefully filter the data to avoid mislabeled patients and class imbalance. We also balanced speed and interpretability to keep the workflow lightweight.
Accomplishments that we're proud of
We created a clear baseline pipeline that is reproducible and easy to build upon. Our models performed well using only simple features, and the results are easy to interpret.
What we learned
We learned how important preprocessing is for real medical data. We also saw how simple models can be powerful when designed carefully.
What's next for HepaClass
We plan to test the pipeline on external datasets like ICGC to validate results. We also want to combine clinical and gene expression data and eventually build a small demo app.
Built With
- fastapi
- grad-cam
- numpy
- opencv
- pillow
- python
- pytorch
- react-native
- streamlit

Log in or sign up for Devpost to join the conversation.