OncoTwin-BRCA
OncoTwin-BRCA is an open multimodal breast cancer digital twin platform designed to model a patient’s latent cancer state across screening, diagnosis, biology, and long-term recurrence. Instead of acting like a narrow classifier that outputs one score from one modality, OncoTwin-BRCA is built as a full-stack oncology world model: it ingests imaging, pathology, molecular data, structured clinical variables, and lifestyle context, fuses them into a shared patient representation, and uses that representation to estimate near-term risk, detection opportunity, subtype, spread, and recurrence trajectories over time.
At a strategic level, the project is breast-first and pan-cancer second. That choice is deliberate. Breast cancer has one of the richest public multimodal data ecosystems available today: screening mammography, tomosynthesis, MRI, pathology, genomics, proteomics, survival data, and external clinicogenomic resources all exist in a form that can be aligned into one coherent benchmark. That makes OncoTwin-BRCA scientifically grounded, technically ambitious, and realistically buildable in public.
In its current form, the platform is designed as both a research system and a product demo. It includes a three-tier neural architecture, a five-stage training pipeline, four simulation engines, a 12-tab interactive dashboard, evidence and explainability layers, and a deployment-ready FastAPI/Vercel stack. The result is not just “an AI that predicts cancer,” but a platform that tries to answer a more interesting question: what is the patient’s current disease state, how likely is meaningful detection to become actionable, and how does risk evolve under different biological and lifestyle scenarios?
By the numbers
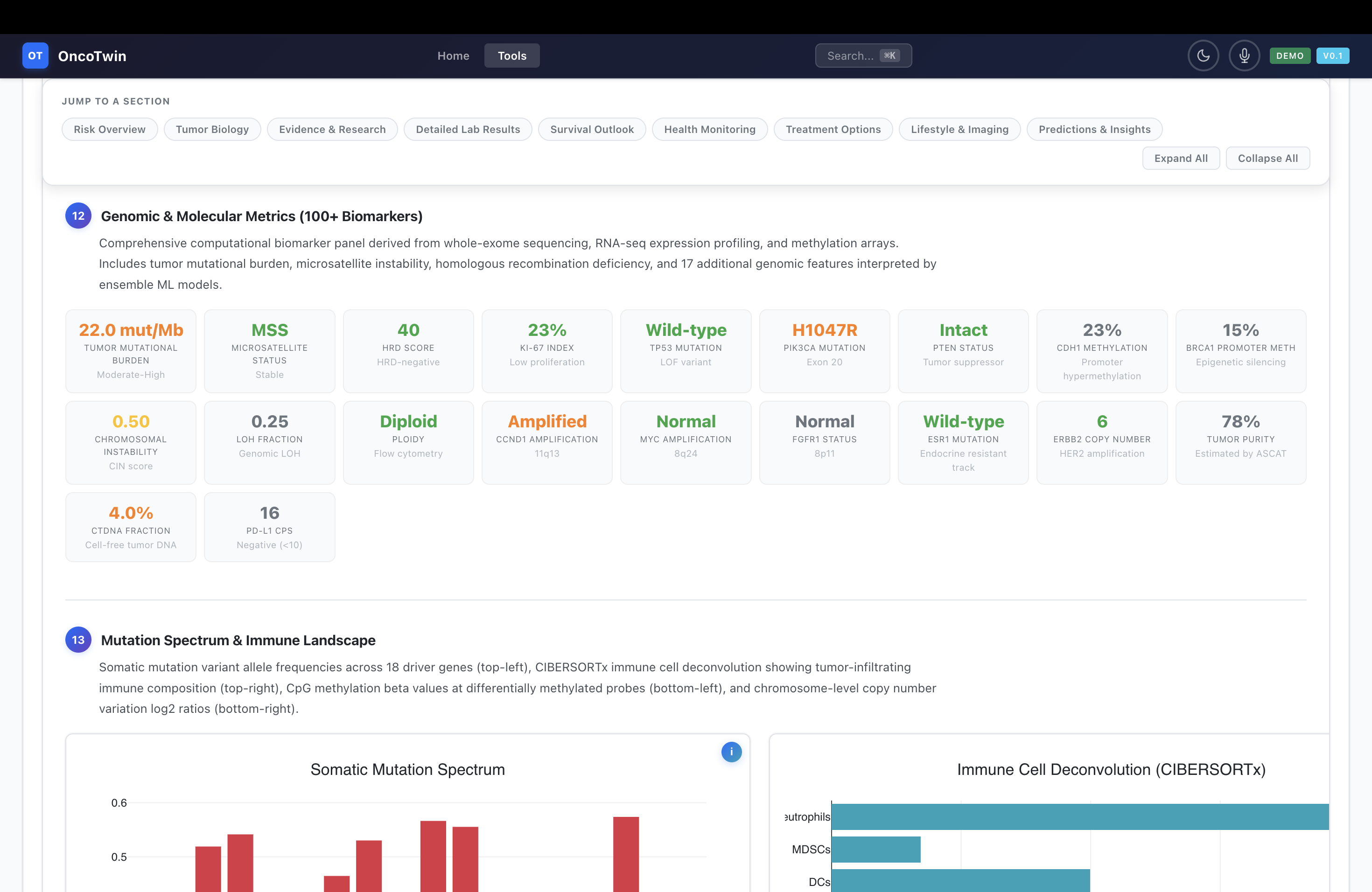
OncoTwin-BRCA currently spans roughly 208 files and about 31,000 lines of code. The modeling stack includes 7 neural encoders, 5 prediction heads, a shared 512-dimensional latent state, a 64-token bottleneck fusion layer, and a 9-subspace world model for temporal disease dynamics. The system is connected to 10 public datasets, supports 4 simulation engines, exposes 12+ backend endpoints, and powers a 12-tab dashboard built with roughly 8,800 lines of JavaScript, 4,200 lines of CSS, and 3,100 lines of HTML. The intake workflow includes a 122-field survey, 50 prebuilt epidemiologic personas, and 16 agent archetypes for patient-journey simulation.
Executive summary
The central thesis of OncoTwin-BRCA is that oncology AI should move beyond flat prediction. A real cancer “twin” should not be a single-output classifier trained on a siloed dataset. It should be a structured patient-state model that integrates what can be seen on screening images, what is revealed by pathology, what is encoded in molecular profiles, what is known from clinical context, and how those signals interact over time.
That is why OncoTwin-BRCA is organized into three linked layers. The Screening Twin models suspicion, density, and detectability from mammography and tomosynthesis. The Tumor State Twin refines that into a multimodal biological picture using MRI, pathology, omics, clinical variables, and knowledge features. The Recurrence Twin then treats the patient state as a temporal dynamical system and forecasts recurrence-free survival, hazard evolution, and long-term uncertainty. This architecture gives the project a real “world model” feel: not image-to-label, but multimodal patient-state to clinical trajectory.
The platform is also careful about novelty. OncoTwin-BRCA is not the first oncology digital twin, not the first multimodal cancer AI project, and not the first recurrence model. Its novelty is more precise and more defensible: it combines screening, tumor-state inference, and recurrence forecasting into one open, public-data-driven, evidence-grounded system centered on a shared latent patient representation. The signature contribution is the Detection Opportunity Score, which reframes the problem from “is this patient high risk?” to “when is disease most likely to become meaningfully detectable or actionably suspicious under current uncertainty?”
Inspiration
The inspiration for OncoTwin-BRCA came from a simple observation: most cancer AI systems are much narrower than the clinical problem they claim to address. One model predicts malignancy from a screening image. Another predicts subtype from pathology. Another estimates recurrence from a structured table. But patients do not exist inside one modality, and cancer does not unfold as a static binary event. It is a changing biological process expressed through imaging phenotypes, molecular programs, pathology patterns, clinical history, treatment exposures, and time.
That gap between clinical reality and model design is what motivated this project. I wanted to build something that felt less like “another classifier” and more like a true computational patient model: a system that could absorb multiple forms of evidence, reconcile them inside a shared state, and tell a coherent story about risk, detectability, biology, and trajectory. In other words, I wanted to build a cancer AI system that behaves more like a research-grade digital twin than a benchmark script.
Breast cancer was the right place to start because the public data landscape is unusually strong from end to end. Screening mammography can be anchored in datasets such as VinDr-Mammo and CBIS-DDSM. Tomosynthesis adds a more advanced 3D screening modality. The Duke Breast MRI dataset provides an exceptional bridge from diagnostic imaging to treatment and outcomes, with 922 biopsy-confirmed invasive cases. TCGA-BRCA, CPTAC, HTAN, HPA, DepMap, and related resources extend the project into radiogenomics, proteogenomics, biomarker interpretation, and pathway reasoning. CAMELYON17 adds a powerful pathology metastasis component. That means breast cancer offers not just scale, but modality completeness.
There was also a product inspiration. Judges and users do not remember isolated AUC numbers; they remember systems that feel coherent. A demo with a strong narrative, a visible patient twin, interpretable evidence panels, realistic simulation, and a polished interface creates a different level of credibility. OncoTwin-BRCA was designed to feel like a real translational platform, not just a model checkpoint.
What it does
OncoTwin-BRCA takes a patient profile and constructs a multimodal digital twin for early detection support and recurrence forecasting. The system accepts structured demographic and clinical inputs, lifestyle variables, family history, biomarker context, and—in its research framing—imaging, pathology, and molecular features from public datasets. Once that information is assembled, the platform estimates three major things: current risk, detection opportunity, and future recurrence dynamics.
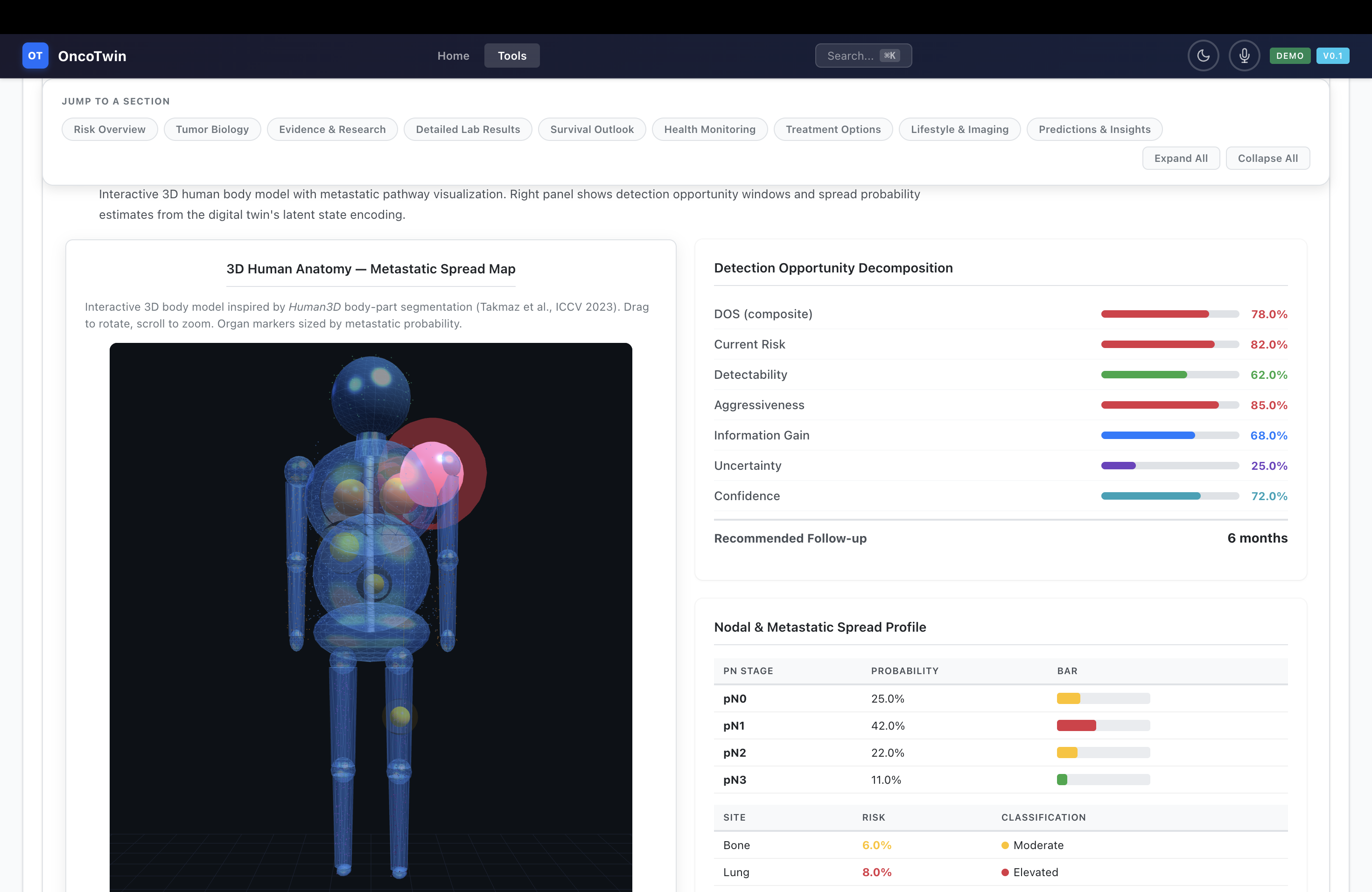
The first layer, the Screening Twin, is designed around mammography and digital breast tomosynthesis. It estimates malignancy probability, BI-RADS-like suspicion signals, and breast density while reasoning about detectability and uncertainty. Instead of stopping at a single risk score, it outputs a Detection Opportunity Score (DOS), a composite signal that blends risk, visibility, uncertainty, and expected information gain. That makes the question more clinically meaningful: not only whether something is wrong, but whether earlier or different follow-up is likely to become more actionable.
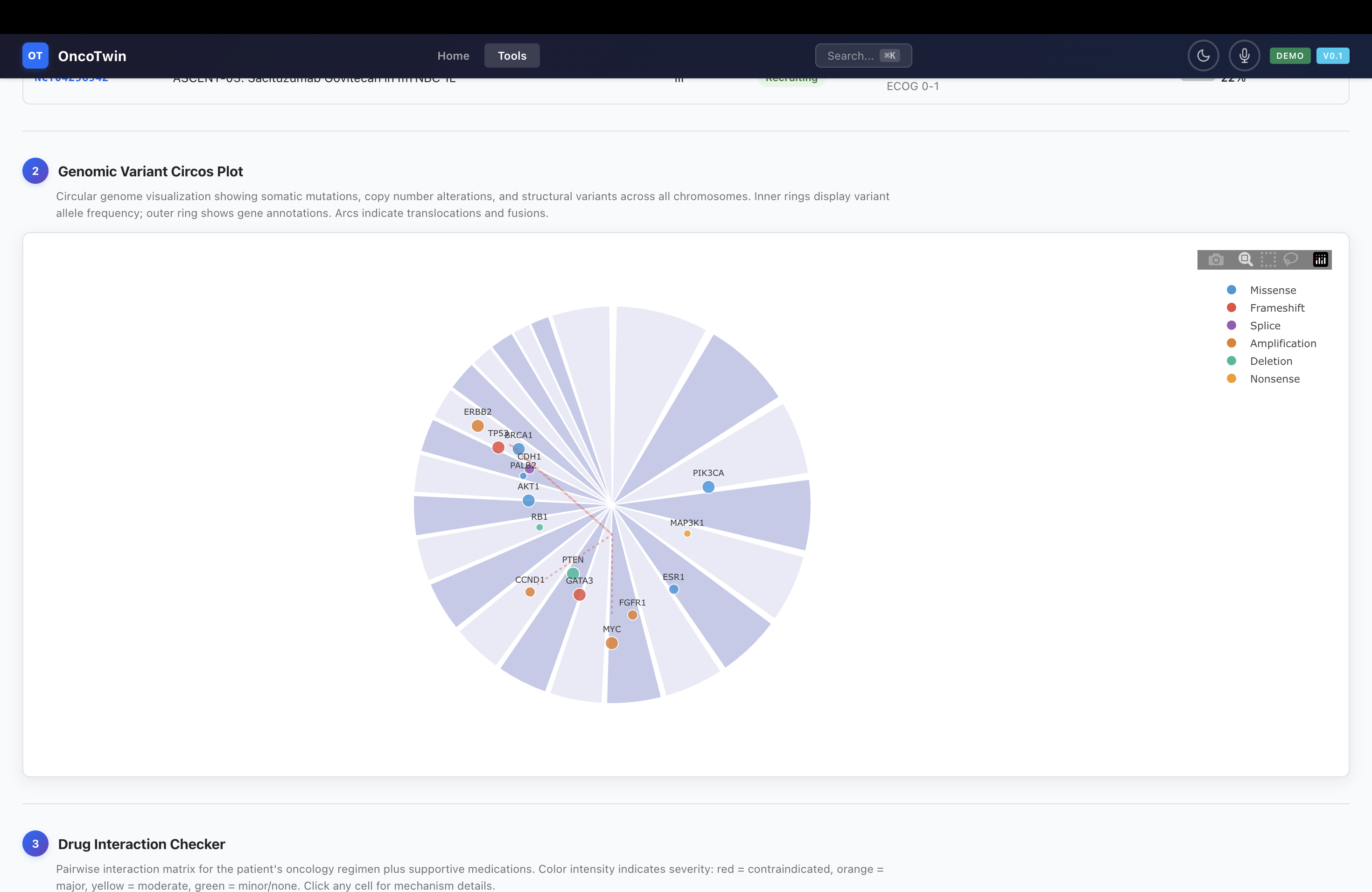
The second layer, the Tumor State Twin, expands the patient into a richer biological and clinical state. This layer incorporates MRI, pathology tile embeddings, omics features such as RNA-seq and mutations, clinical structured variables, and pathway or literature-derived knowledge representations. From there, the system predicts subtype, receptor status, proliferation proxies, nodal involvement, and metastatic tendencies. It is meant to approximate an internal disease portrait rather than a disconnected list of outputs.
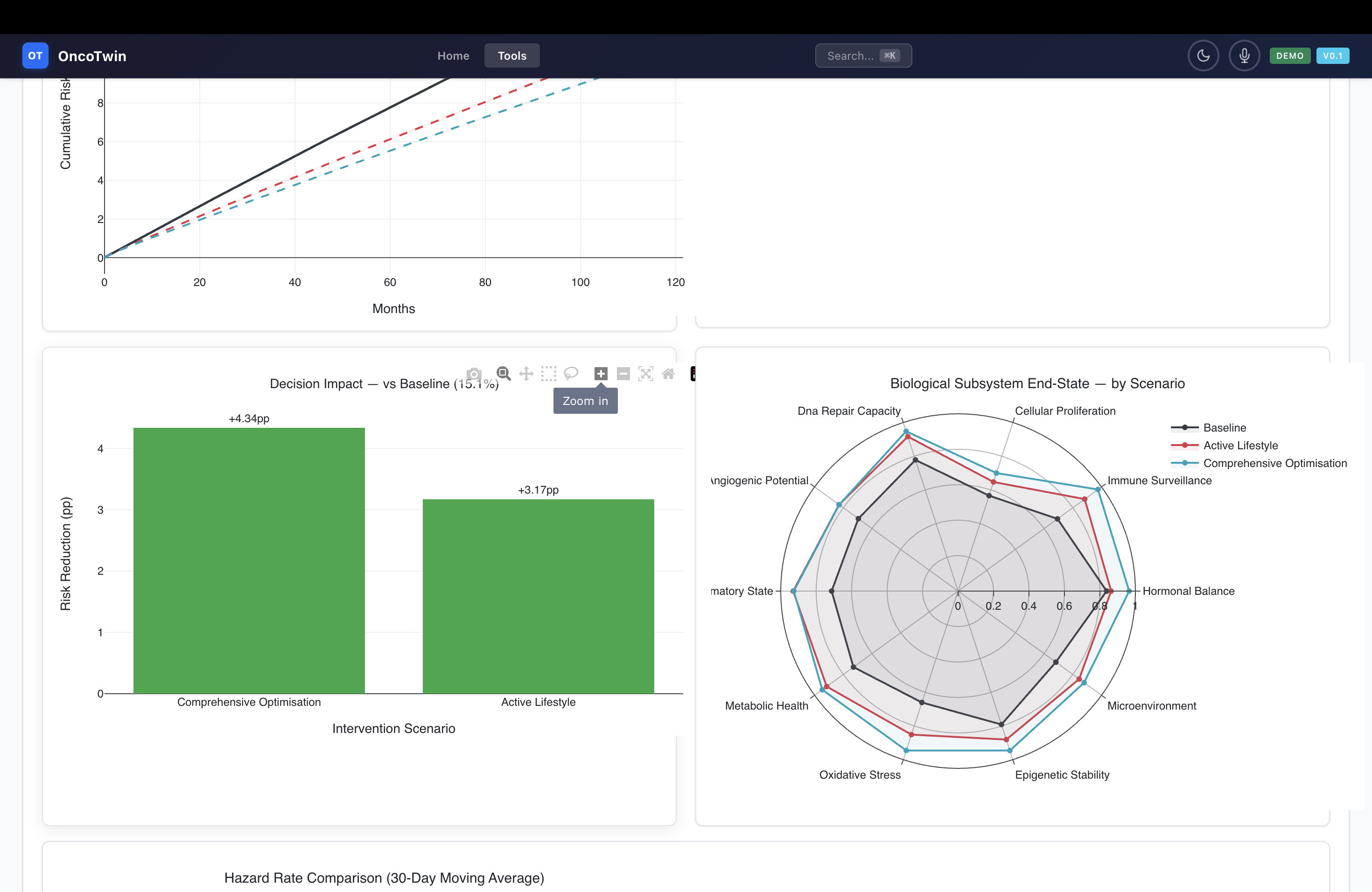
The third layer, the Recurrence Twin, treats the patient as a temporal dynamical system. A latent representation of the patient is decomposed into nine subspaces, including imaging phenotype, tumor biology, proliferation, immune context, metabolism, hormonal state, genetic risk, environmental exposure, and treatment response. A Neural ODE or Neural CDE then evolves that state over time, producing uncertainty-aware forecasts for 1-year, 3-year, 5-year, and 10-year recurrence-free survival. This is where the platform becomes more than a diagnostic model; it becomes a trajectory model.
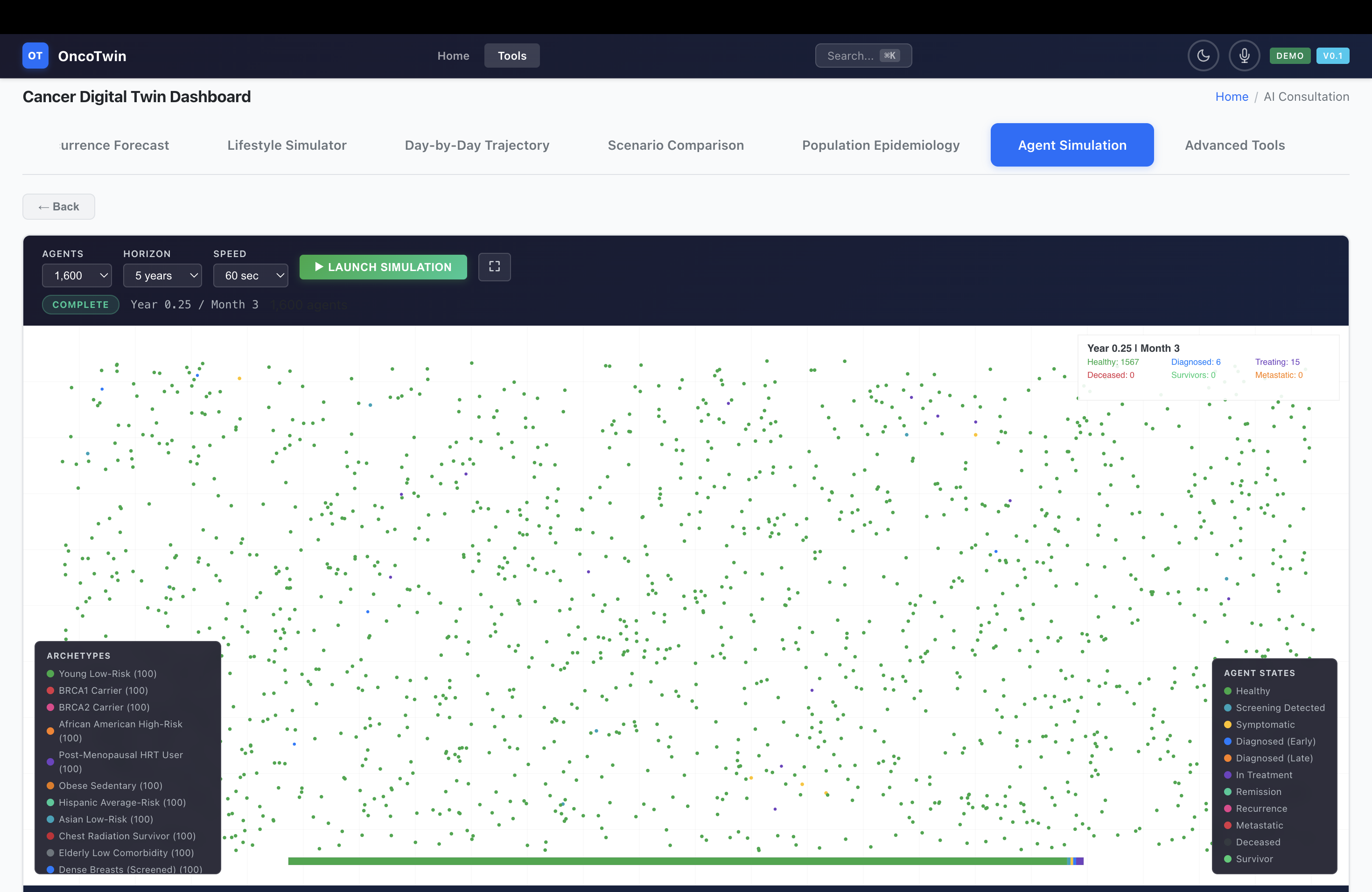
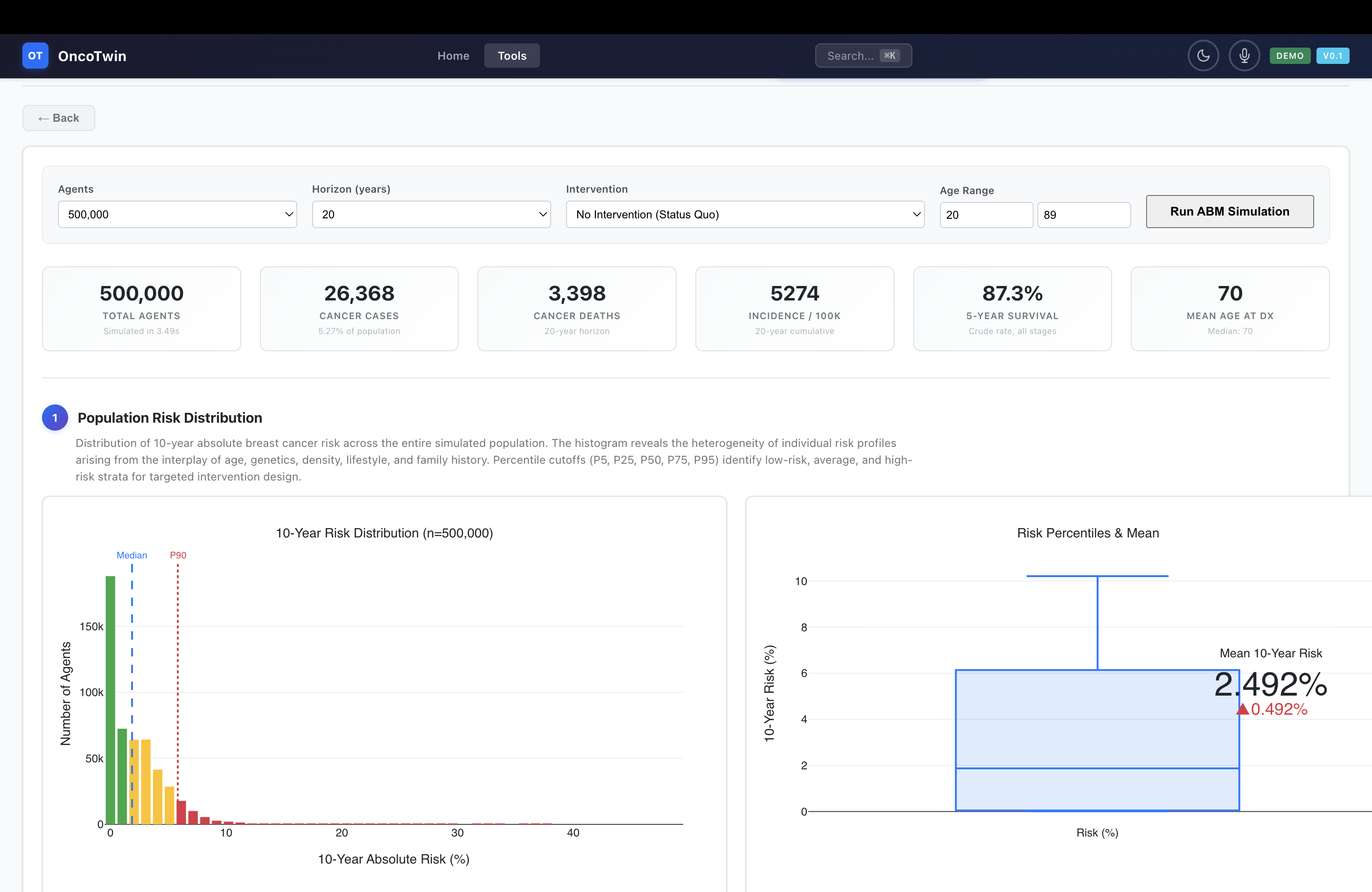
On top of the core prediction stack, OncoTwin-BRCA includes four simulation engines that make the twin interactive. The Monte Carlo Risk Engine simulates individual risk under changing exposures and modifiers, running 200 trajectories per scenario and incorporating interpretable effects such as BRCA1, BRCA2, family history, HRT, and tamoxifen. The OmniScan Engine computes a six-dimensional composite risk signature across clinical, genomic, imaging, lifestyle, family, and biomarker axes. The Population ABM scales this idea to 100,000 to 2 million synthetic agents and models disparities, screening adherence, interventions, and outcomes at the epidemiologic level. The TinyTroupe Simulation turns the science into patient-journey storytelling by animating 16 archetypal paths through diagnosis, treatment, and recurrence risk.
The user experience is equally important. The platform includes a 12-tab dashboard with modules such as OmniScan, Population Explorer, Patient Twin, Imaging Console, Pathology & Biology, Recurrence Forecast, Lifestyle Simulator, Scenario Comparison, Population Epidemiology, AI Consultation, and Advanced Tools. The system also supports PDF export, dark mode, command palette navigation, voice input, progressive web app installation, and Slack/Teams style alerting. That combination makes the project feel like a serious translational interface rather than a disconnected notebook demo.
Why this matters
A major weakness of many medical AI systems is that they provide predictions without context. They can output a probability, but not a patient narrative. They can detect a pattern, but not explain how that pattern relates to subtype, pathway activity, likely recurrence, or what additional evidence could reduce uncertainty. OncoTwin-BRCA tries to solve that by linking prediction, explanation, and simulation inside one platform.
The emphasis on detection opportunity is especially important. Many models predict future cancer risk; fewer models try to estimate when cancer is likely to become visible, suspicious, or meaningfully actionable. That timing dimension matters because the clinical cost of missed opportunity is not just a lower score on a benchmark; it is delayed detection, worse stage at diagnosis, and narrower treatment windows. Reframing screening support around opportunity and uncertainty makes the project more clinically aligned and more memorable.
The project also matters from an open science perspective. Public multimodal oncology resources exist, but they are fragmented. Researchers often use them one at a time, one modality at a time, or one task at a time. OncoTwin-BRCA’s deeper contribution is to organize them into a single coherent stack with shared representation learning, multimodal fusion, temporal forecasting, and evidence-grounded output. Even as a prototype, that framing raises the standard for what a public cancer AI platform can look like.
Codebase anatomy
From the structure you described, the repository is organized in a way that mirrors the conceptual design of the system. The app/api layer exposes the serving interface through FastAPI routes, schemas, dashboards, and bot integrations. This is the contract between the models and the interface, translating patient inputs, model predictions, simulation outputs, and report generation into deployable endpoints.
The app/simulation directory contains the engines that make OncoTwin-BRCA feel like a digital twin rather than a static predictor. This is where Monte Carlo risk evolution, population-scale agent-based epidemiology, OmniScan composite scoring, and TinyTroupe patient-journey simulation live. That separation is smart because it keeps world-modeling and scenario analysis modular and extensible.
The app/evidence layer handles interpretability and grounding. Modules for molecular evidence, similar-case retrieval, literature context, and feature attribution make predictions inspectable rather than opaque. In a medical setting, that is not just a nice-to-have; it is central to user trust.
The models directory is the scientific core of the repo. It is subdivided into encoders, fusion layers, prediction heads, losses, and world-model components, which suggests a serious attempt at architectural modularity. Rather than building one monolithic model, the repo treats each modality and task head as a composable research object. That is the right pattern for experimentation, ablation, and future extension.
The training and configs layers formalize the training system through stage-wise scripts and Hydra/OmegaConf configuration. That helps the project look reproducible rather than improvised. Meanwhile, the frontend stack—app/static/js, app/static/css, app/templates, app/ui, and app/assets—makes clear that this is not just a backend research repo. It is a genuine interactive product layer. Supporting directories such as datasets, scripts, evaluation, docker, vercel.json, pyproject.toml, and requirements.txt round out the infrastructure story with ingestion, benchmarking, packaging, and deployment.
How I built it
I built OncoTwin-BRCA as a layered full-stack research platform, not as a single model. The architecture begins with modality-specific encoders. Mammography is handled through a ConvNeXt-style backbone that projects screening images into a compact embedding space. Tomosynthesis extends that logic into 3D with a DBT encoder. MRI contributes lesion and enhancement context through a dedicated imaging pathway. Pathology uses tile-based whole-slide embeddings aggregated into slide-level biological signals. Omics are tokenized into interpretable genomic and pathway representations rather than treated as an undifferentiated vector. Clinical variables are encoded through a structured MLP-style branch, and knowledge signals are captured through a graph-informed encoder.
These representations are then passed into a BottleneckFusion mechanism built around latent tokens and cross-attention. Instead of late-fusing separate task models at the very end, OncoTwin-BRCA tries to learn a shared patient state first. The fusion layer uses 64 latent tokens and modality dropout so that the system can remain functional under missing-data conditions, which is essential for multimodal medicine where every patient does not have every assay or imaging modality available.
Above this fused state sit several prediction heads. There are heads for screening risk, detection opportunity, subtype and biomarker inference, metastasis and nodal spread, and recurrence. The recurrence component is the most ambitious: a 512-dimensional patient state is decomposed into nine biological subspaces and passed through a continuous-time dynamics model using a Neural ODE or Neural CDE approach. This allows the project to forecast a curve rather than emit a static label. In effect, it tries to model where the patient is now, where they are likely to go next, and how uncertain the system is about that path.
The training pipeline is staged in five parts. First, each modality is pretrained through self-supervised or representation-learning techniques such as MAE, InfoNCE, or VICReg-style objectives. Second, the modalities are aligned through cross-modal contrastive training so that imaging, pathology, and molecular signals can occupy a compatible space. Third, the world model is trained to learn state transitions over time. Fourth, the system is fine-tuned on supervised downstream tasks across screening, subtype, spread, and recurrence. Fifth, the outputs are calibrated with methods such as temperature scaling or Platt-style calibration so the probabilities are more meaningful and clinically usable.
The simulation layer was built to complement the neural model rather than duplicate it. The Monte Carlo engine lets users perturb lifestyle and genetic factors and observe risk evolution under multiple trajectories. The OmniScan engine produces a six-axis composite risk portrait with visual analytics. The population agent-based model makes it possible to move from the individual twin to population policy questions such as adherence, disparities, and intervention impact. TinyTroupe adds narrative realism by representing different epidemiologic archetypes and their longitudinal journeys. Together, these modules make the system more interactive, more interpretable, and more product-like.
On the frontend, I built a large vanilla-JS dashboard rather than hiding the model behind a minimalist form. The goal was to make the patient twin explorable. The interface includes imaging views, 3D anatomy, pathway charts, Kaplan-Meier curves, radar plots, scenario comparison panels, population UMAPs, consultation modules, and report export. Technologies such as Plotly, Three.js, jsPDF, and html2canvas make the interface feel dynamic and presentation-ready. Features like a command palette, voice input, PWA installation, service-worker caching, and team alerting push the project beyond a research prototype and toward a usable tool.
Under the hood, the stack is served through FastAPI and Uvicorn, configured through Hydra and OmegaConf, trained in PyTorch Lightning, logged with WandB, and packaged for both Vercel deployment and Dockerized training. That combination matters because sophisticated science alone is not enough; a strong project also needs reproducibility, deployment, and demonstration quality.
Datasets and statistical scope
A major strength of OncoTwin-BRCA is the breadth of its public-data stack. The screening module can be grounded in VinDr-Mammo, with roughly 16,000 mammography exams, and CBIS-DDSM, with about 1,300 screening mammograms, while DBT support adds a more advanced volumetric modality to the screening layer. The diagnostic and recurrence modeling pipeline is anchored by the Duke Breast MRI dataset, which includes 922 biopsy-confirmed invasive breast cancer patients with linked clinical and outcome information. Pathology is supported by CAMELYON17, with about 500 whole-slide images focused on lymph node metastasis, and can be broadened with TCGA slide assets.
For molecular context, the project uses resources such as TCGA-BRCA, CPTAC, HTAN, DepMap, and the Human Protein Atlas. Those datasets support transcriptomic, mutational, copy-number, proteomic, pathway, and vulnerability analyses. External validation thinking is also built into the design through public-access clinicogenomic ecosystems such as AACR Project GENIE, which provides on the order of 271,837 samples from 227,696 patients in its public releases. The point is not that all of these sources are trivially harmonized—they are not—but that OncoTwin-BRCA is scoped around a realistic public multimodal stack rather than a hypothetical one.
Statistically, this breadth is important for two reasons. First, it lets the project address multiple linked tasks instead of overfitting to a single benchmark. Second, it supports a stronger argument for latent-state learning: if the same patient representation can support screening, biology, spread, and recurrence across heterogeneous cohorts, then the project is doing something more meaningful than memorizing a dataset-specific label structure.
The core technical idea
The most important technical idea in OncoTwin-BRCA is the move from late fusion of isolated predictors to a shared patient-state model. Many multimodal projects concatenate features near the end and then attach a head. OncoTwin-BRCA instead tries to learn an internal patient state that is rich enough to support multiple tasks. That state is then interpreted biologically and evolved temporally.
The second core idea is hierarchy. A screening image alone does not tell the whole story, but it does define the first layer of suspicion and detectability. Tumor-state inference expands the view with pathology, MRI, and molecular evidence. Recurrence modeling adds time. This hierarchical decomposition makes the system more understandable and more extensible. It also lets the project express different types of uncertainty at different levels.
The third core idea is detection opportunity. This is what makes the project memorable. Many AI systems say “high risk” or “low risk.” OncoTwin-BRCA tries to estimate when disease is most likely to become actionably visible, given density, lesion phenotype, biological aggressiveness, missing information, and expected information gain from follow-up. That transforms the system from a probability engine into a timing engine.
Challenges I ran into
The hardest challenge was multimodal fragmentation. Public cancer data are rich, but they are not naturally aligned. Imaging cohorts, pathology cohorts, omics cohorts, and survival cohorts often have different patient populations, different label conventions, different preprocessing standards, and different missingness patterns. Building a coherent twin out of these resources is not just a modeling challenge; it is a data ontology challenge.
A second major challenge was deciding how ambitious the project should be without making it scientifically incoherent. A pan-cancer claim sounds impressive, but public multimodal depth is uneven across diseases. That is why the breast-first strategy matters. It creates a flagship implementation that is deep enough to feel real, while still leaving room for a broader architecture later. Learning where to narrow scope without shrinking the vision was one of the most important design decisions in the entire project.
Another challenge was calibration and interpretability. In oncology, a flashy model is less useful than a reliable one. A system that predicts recurrence risk but cannot explain which modalities drove that prediction, how uncertain it is, or what similar public cases look like will not feel trustworthy. That is why evidence modules, saliency, nearest-neighbor retrieval, pathway attribution, and literature grounding became essential rather than optional.
The frontend itself was also a serious challenge. Building a large interactive dashboard with multiple scientific views, scenario controls, simulation panels, and export features in vanilla JavaScript required balancing sophistication with maintainability. The product needed to feel polished enough for demo use without collapsing under its own complexity. Integrating simulation, visualization, and backend inference into a single coherent interface was easily one of the most demanding parts of the build.
Finally, there was a narrative challenge: how to present a project like this honestly. It would be easy to oversell a system like OncoTwin-BRCA as “solving cancer prediction.” That would weaken it. The stronger framing is more disciplined: an open, multimodal digital twin research platform for early detection opportunity and recurrence forecasting, grounded in public data and built to demonstrate how patient-state modeling could be done more coherently.
Accomplishments that I’m proud of
What I am most proud of is that OncoTwin-BRCA feels like a platform, not a patchwork. It combines modeling, simulation, evidence, deployment, interface, and product narrative into one system. That coherence matters. A lot of strong technical projects still feel fragmented when presented; this one has a clear scientific story and a clear user story.
I am also proud of the three-tier architecture. Structuring the model into Screening Twin, Tumor State Twin, and Recurrence Twin makes the project much more legible than a monolithic multimodal network. It gives each layer a clinical meaning while still allowing them to connect through a shared latent patient state. That architectural decision is a major part of what makes the project feel like a true digital twin.
The Detection Opportunity Score is another accomplishment I am proud of because it creates a memorable identity for the project. It is not just a technical flourish; it changes the framing of the entire system from passive risk scoring to active opportunity estimation. That makes the project both more interesting scientifically and more compelling as a demo.
I am proud of the breadth of the public-data integration. Bringing together screening mammography, DBT, MRI, pathology, omics, clinical context, and epidemiologic simulation into one open stack is a meaningful achievement on its own. So is building a five-stage training pipeline, four simulation engines, and a large interactive interface that can actually communicate the science.
Finally, I am proud that the platform includes product-level features such as PDF export, PWA support, command palette navigation, voice input, and team alerts. Those details matter because they signal that the project was built not only to run experiments, but also to be shown, understood, and used.
What I learned
The biggest lesson I learned is that in biomedical AI, architecture is not only about performance; it is about framing. A system becomes more powerful when its outputs correspond to meaningful clinical questions. Predicting a label is useful. Modeling a patient state is more useful. Modeling a patient state and then asking when detection becomes actionable is more powerful still.
I also learned that public data can support surprisingly ambitious work, but only if the scope is carefully chosen. The dream of a universal multimodal oncology twin is attractive, but the path to that goal starts with a disease area where the public evidence chain is deep enough to support real end-to-end modeling. Breast cancer offers that chain in a way that few other domains currently do.
Another lesson was that interpretability cannot be bolted on at the end. If a model is going to make recurrence forecasts or biological assertions, explanation pathways need to be present from the start. That includes feature attribution, similar-case retrieval, molecular evidence layers, pathway summaries, and honest uncertainty handling. In medicine, explanation is part of the product, not a side module.
I also learned that simulation dramatically strengthens a project. Static dashboards are informative, but simulation makes a system feel alive. Once users can perturb a patient profile, compare trajectories, examine population interventions, and walk through archetypal journeys, the project becomes much more intuitive and much more compelling.
Most of all, I learned the value of disciplined ambition. The strongest version of a big idea is not the version that claims everything. It is the version that chooses one domain, defines one real innovation, executes deeply, and presents it with clarity.
Limitations and responsible framing
OncoTwin-BRCA is ambitious, but it is important to state what it is and what it is not. It is not a clinically validated diagnostic device. It is not a substitute for radiologists, pathologists, oncologists, or real-world longitudinal care. It is a research and product prototype built to explore how multimodal patient-state modeling can support early detection reasoning and recurrence forecasting.
The largest technical limitation is data harmonization. Public multimodal datasets are powerful, but they differ in label design, cohort composition, imaging protocols, survival definitions, and data completeness. That means representation learning and evaluation must be handled carefully, especially when crossing between modalities or institutions.
Another limitation is that “digital twin” can easily become a vague term if it is not operationalized. In OncoTwin-BRCA, the twin is concretized as a shared latent patient state with hierarchical heads and temporal dynamics. That is useful, but it is still a modeling abstraction, not a mechanistic simulator of tumor biology in the fullest sense.
These limitations do not weaken the project; they strengthen its credibility. A sophisticated platform should make strong claims where justified and modest claims where validation is still needed.
What’s next for OncoTwin-BRCA
The next step is rigorous validation. The architecture is strong, but the strongest future version of OncoTwin-BRCA will be the one that proves its value through benchmark comparisons, ablations, calibration curves, and external transfer testing. That means evaluating the screening layer on mammography and DBT cohorts, the tumor-state layer on subtype and biomarker tasks, and the recurrence layer on MRI-linked and molecularly anchored outcome datasets.
A second major direction is deeper evidence grounding. I want the next version to make every major output more inspectable: clearer cross-modal attribution, stronger case retrieval, richer literature alignment, and better explanation of how pathway activity or receptor context influences predictions. The goal is for the twin not only to predict, but to justify.
A third direction is improving temporal realism. The current recurrence framing is already trajectory-based, but future versions could model treatment interventions, longitudinal imaging checkpoints, evolving biomarker states, and disease progression under different counterfactual scenarios. That would make the “world model” aspect much stronger.
I also want to expand the product side. The current dashboard is already broad, but future versions could support clinician-oriented summaries, trial matching, biomarker timelines, more realistic report generation, and more robust collaborative workflows. The best version of the platform should feel equally strong as a research environment, a demo experience, and a translational decision-support prototype.
Longer term, the architecture is designed to become pan-cancer. The breast-first strategy is not a retreat from ambition; it is the foundation for it. Once the representation, fusion, temporal modeling, and evidence stack are proven in a data-rich flagship domain, the same architecture can be adapted to other cancers with the right modality mix and cohort support.
Closing
OncoTwin-BRCA is an attempt to rethink what an open cancer AI project can look like. It is not just a model, not just a dashboard, and not just a simulation. It is a multimodal patient-state platform built around the idea that cancer AI should reason across evidence, across time, and across uncertainty. By combining screening, biology, recurrence, and simulation into a single coherent system, OncoTwin-BRCA aims to feel less like a benchmark demo and more like the early version of a true oncology digital twin.

Log in or sign up for Devpost to join the conversation.