Inspiration
Cancer screening isn’t just “is this cancer or not?” — the real bottleneck is triage. Clinicians have to prioritize follow-ups with limited time, lots of images, and incomplete patient context. Meanwhile, patients generate useful longitudinal signals every day from wearables (sleep, HRV, resting heart rate, symptoms), but that data rarely lands in the same place screening decisions get made.
OncoLens started from that gap: images without longitudinal context on one side, and longitudinal signals without workflow on the other. We wanted something a clinician could realistically use: What’s the risk, how confident are we, and what should we do next?
What it does
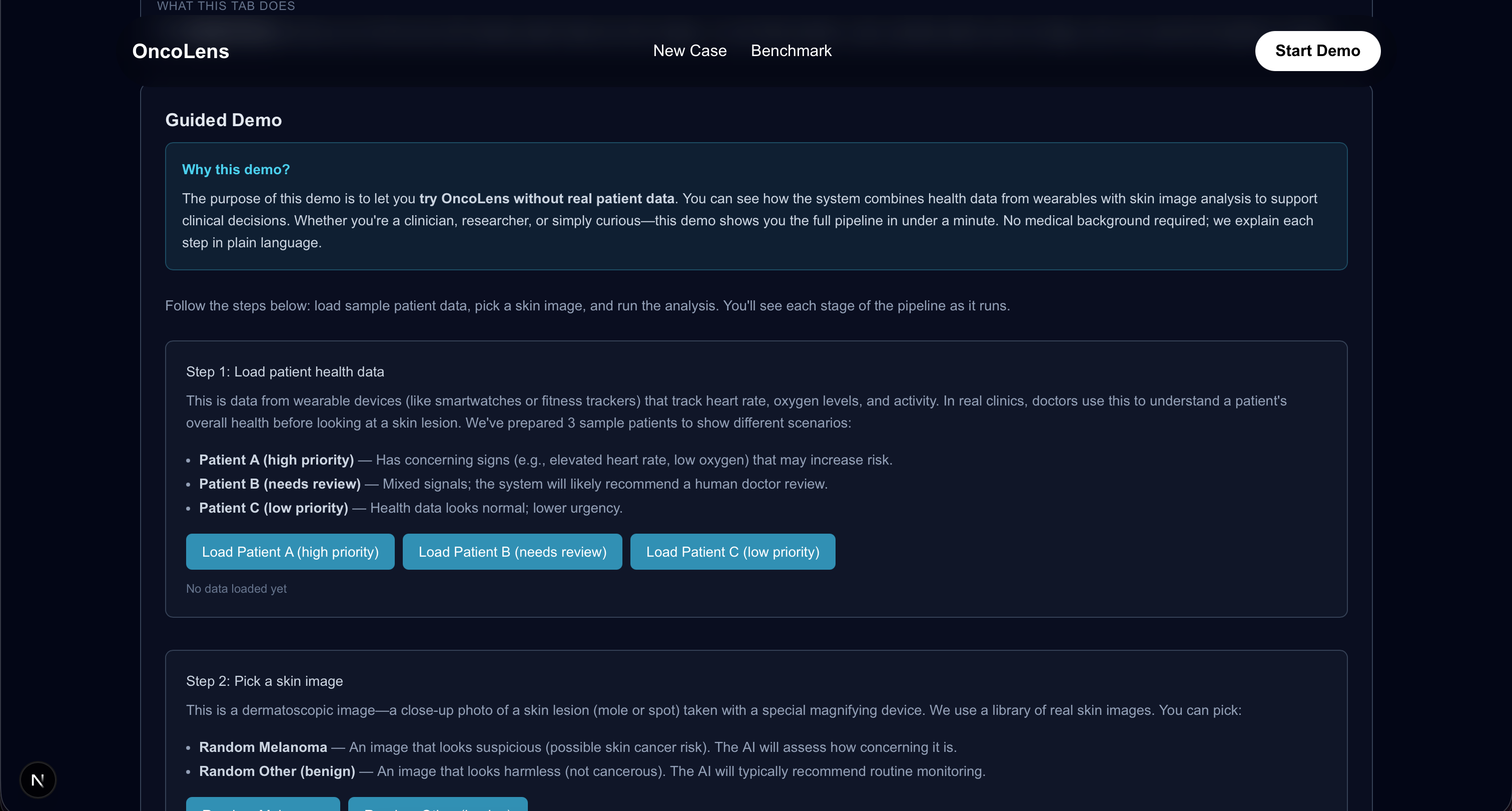
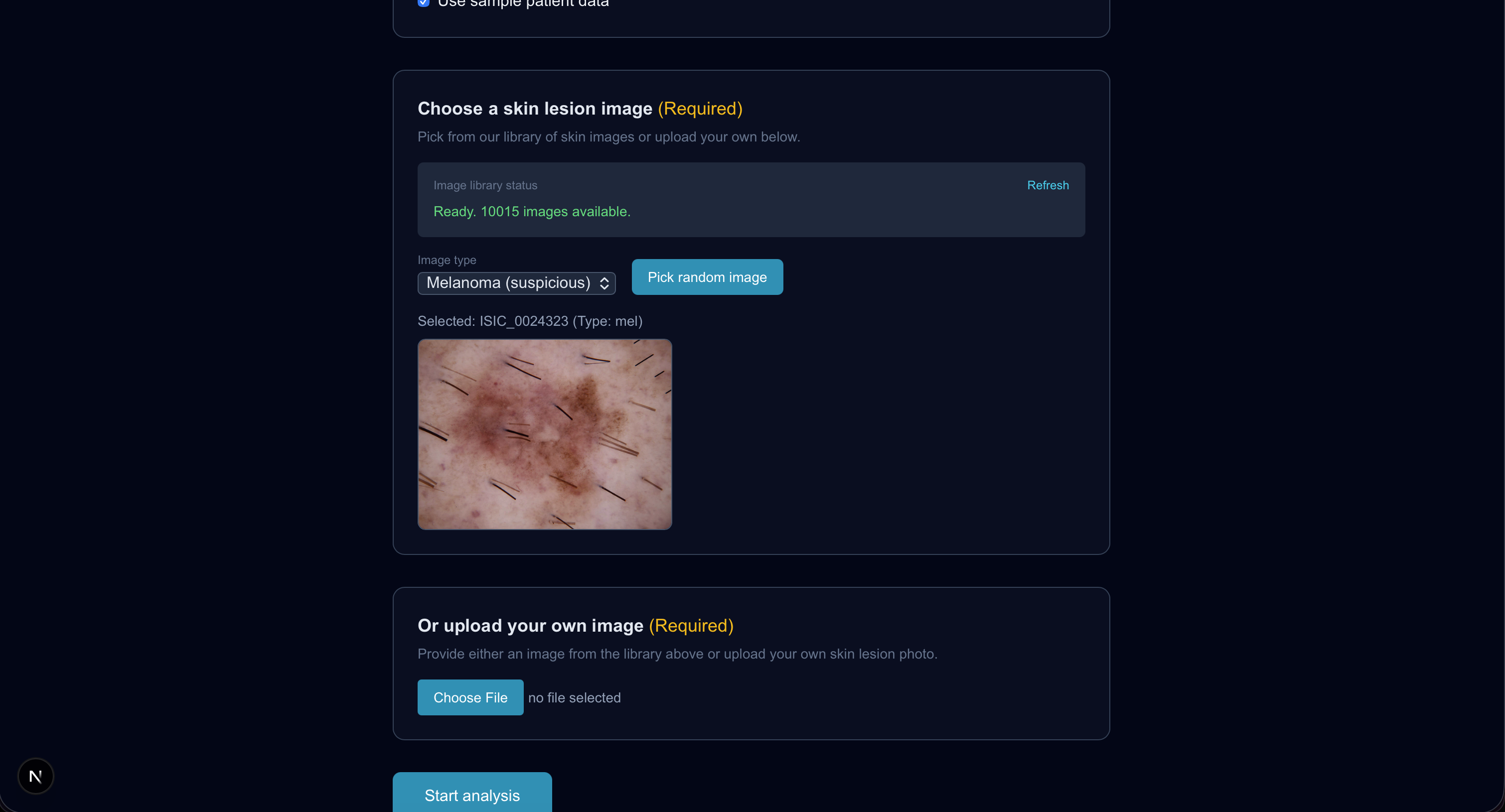
OncoLens is a research prototype for screening triage (not diagnosis). It takes:
- a skin lesion image (we used HAM10000 locally via Kaggle), and
- a 30-day wearable CSV (or a mock patient month),
and produces:
- an image suspicion score with a heatmap,
- a wearable-context risk score from trends over time,
- a fused screening score with uncertainty and guardrails,
- and a ranked set of next clinical steps (monitor, repeat imaging, refer specialist, biopsy consideration).
We use Gemini as the communication layer: it generates a clinician-friendly rationale and a patient-safe summary anchored to our computed outputs.
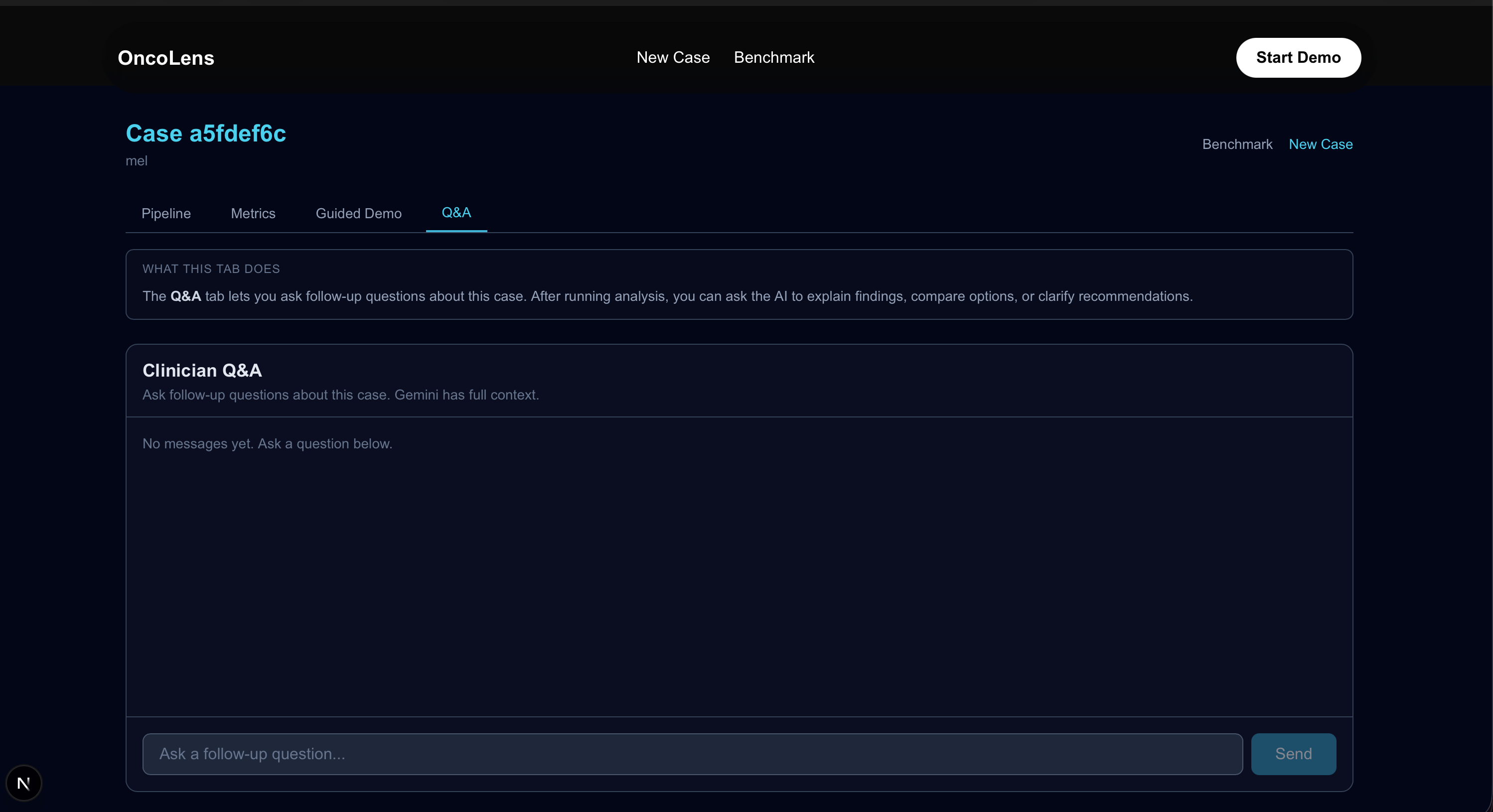
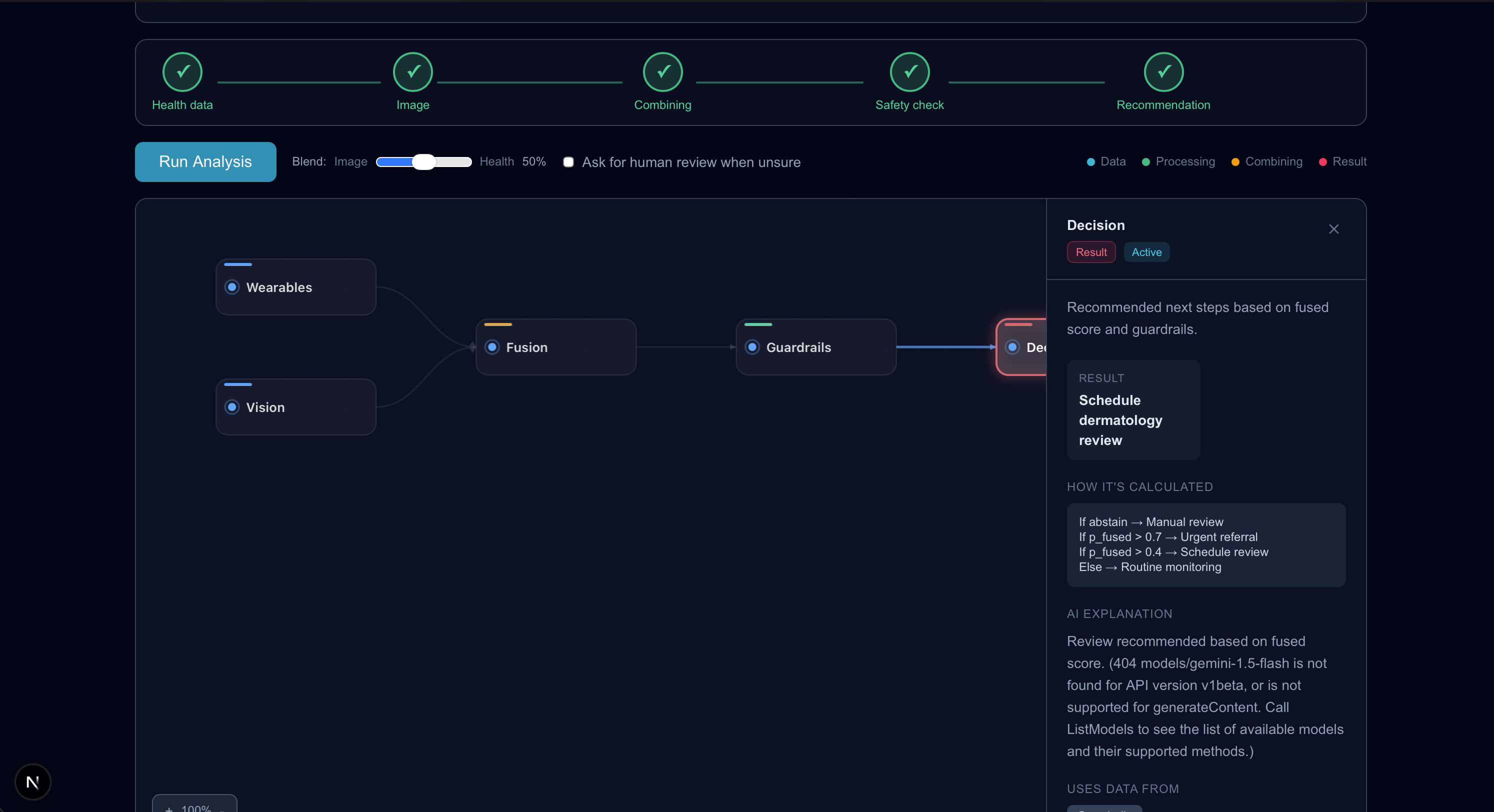
The UI centers around a clickable DAG (pipeline graph). Clicking any node shows the outputs and Gemini’s explanation for that step, so the system feels transparent instead of a black box.
How we built it
Frontend: Next.js + Tailwind
We built a tabbed interface:
- DAG tab: interactive pipeline nodes + right-side reasoning panel (Gemini + outputs per node)
- Graphs tab: time-series trends (HRV, resting HR, sleep, weight, symptoms)
- Doctor Workflow tab: a guided “how this fits into real clinical triage”
- Impact tab: efficiency comparisons (time-to-triage, throughput, safe deferrals)
Backend: FastAPI (modular pipeline)
1) ingest CSV + image
2) compute time-series features
3) compute risk + uncertainty
4) fuse signals
5) apply guardrails (abstain/defer)
6) decision engine (next steps ranking)
7) Gemini narrative report (structured)
Gemini does not decide numeric scores — it explains them.
Challenges we ran into
- Not overclaiming: we had to be strict about “screening triage” language and avoid “diagnosis” claims.
- Data quality: wearables can be messy (missing days, noise, inconsistent formats). We needed reliable quality checks and guardrails.
- Explainability that feels real: we didn’t want “AI says so.” We wanted uncertainty, evidence, and a clear defer policy.
- UX: making a complex pipeline understandable in under a minute is hard — the DAG ended up being the cleanest way to communicate reasoning.
Accomplishments that we're proud of
- Built an uncertainty-aware pipeline that can defer safely instead of hallucinating confidence.
- Turned scores into ranked next steps using a decision engine (more realistic than just outputting a probability).
- Shipped a polished UI with a DAG and node-level explanations.
- Used Gemini in a responsible way: communication + rationale, not the source of truth.
What we learned
- In health AI, the most important capability is knowing when not to answer.
- “Advanced” isn’t a bigger model — it’s uncertainty, guardrails, and decision logic that maps to workflow.
- If you can’t explain why a recommendation was made (and when to defer), clinicians won’t trust it.
What's next for OncoLens
- Replace baseline image scoring with a trained lesion classifier, plus calibration and subgroup evaluation.
- Add real wearables ingestion (Apple Health/Fitbit) instead of CSV.
- Run a pilot-style evaluation with workflow metrics: time-to-triage, deferral rates, and follow-up outcomes.
- Expand the evidence layer (retrieval of prior patient history + citations in reports).
The math behind the pipeline (Devpost LaTeX)
Wearable featureization
For each daily signal \(s_t\) over \(T\) days, we compute mean and variance:
$$ \mu = \frac{1}{T}\sum_{t=1}^{T} s_t \qquad \sigma^2 = \frac{1}{T-1}\sum_{t=1}^{T}(s_t-\mu)^2 $$
We also compare early vs late behavior using weekly deltas:
$$ \Delta_{7d} = \overline{s}{\text{last 7}} - \overline{s}{\text{first 7}} $$
And we compute a least-squares trend slope:
$$ \hat{\beta}= \frac{\sum_{t=1}^{T}(t-\bar{t})(s_t-\mu)}{\sum_{t=1}^{T}(t-\bar{t})^2} \qquad \bar{t}=\frac{T+1}{2} $$
Wearable risk score + uncertainty (ensemble)
We model wearable-context risk with a logistic score:
$$ p_{\text{health}} = \sigma\!\left(b+\sum_k w_k x_k\right) $$
To estimate uncertainty, we run an ensemble of \(M\) slightly perturbed models and compute mean/variance of the predicted probabilities:
$$ \bar{p}{\text{health}}=\frac{1}{M}\sum{m=1}^M p_{\text{health}}^{(m)} \qquad \mathrm{Var}{\text{health}}=\frac{1}{M-1}\sum{m=1}^M\left(p_{\text{health}}^{(m)}-\bar{p}_{\text{health}}\right)^2 $$
We form a simple confidence interval:
$$ \mathrm{CI}(p)=\left[p - z\sqrt{\mathrm{Var}},\ p + z\sqrt{\mathrm{Var}}\right]\cap[0,1] $$
Image suspicion + heatmap
We compute an image suspicion score:
$$ p_{\text{vision}}=\sigma\!\left(a(\mathrm{quality}-b)\right) $$
And make uncertainty higher when image quality is poor:
$$ \mathrm{Var}_{\text{vision}} = v_0 + \frac{v_1}{\mathrm{quality}+\varepsilon} $$
Fusion
We fuse wearable and image signals via logits:
$$ \mathrm{logit}(p)=\log\left(\frac{p}{1-p}\right) $$
$$ \mathrm{logit}(p_{\text{fused}})=w_0+w_1\,\mathrm{logit}(p_{\text{vision}})+w_2\,\mathrm{logit}(p_{\text{health}}) $$
$$ p_{\text{fused}}=\sigma\!\left(\mathrm{logit}(p_{\text{fused}})\right) $$
We combine uncertainty conservatively:
$$ \mathrm{Var}{\text{fused}}=\mathrm{Var}{\text{health}}+\mathrm{Var}_{\text{vision}} $$
Guardrails / abstention
We defer when uncertainty or quality is too low:
$$ \text{abstain} = \mathbb{1}\{\mathrm{Var}_{\text{fused}}>\tau_v\ \lor\ \mathrm{quality}<\tau_q\ \lor\ \mathrm{gaps}>\tau_g\} $$
Decision engine (expected utility)
Instead of only outputting risk, we rank next steps using expected utility:
$$ EU(a)=p_{\text{fused}}U(a,1)+(1-p_{\text{fused}})U(a,0)-\lambda\cdot\frac{C(a)}{1000} $$
This yields a practical top-ranked “next step,” and if we abstain we return “defer to clinician.”
Built With
- fastapi
- react

Log in or sign up for Devpost to join the conversation.