Once Upon a Dataset — Devpost Submission
Inspiration
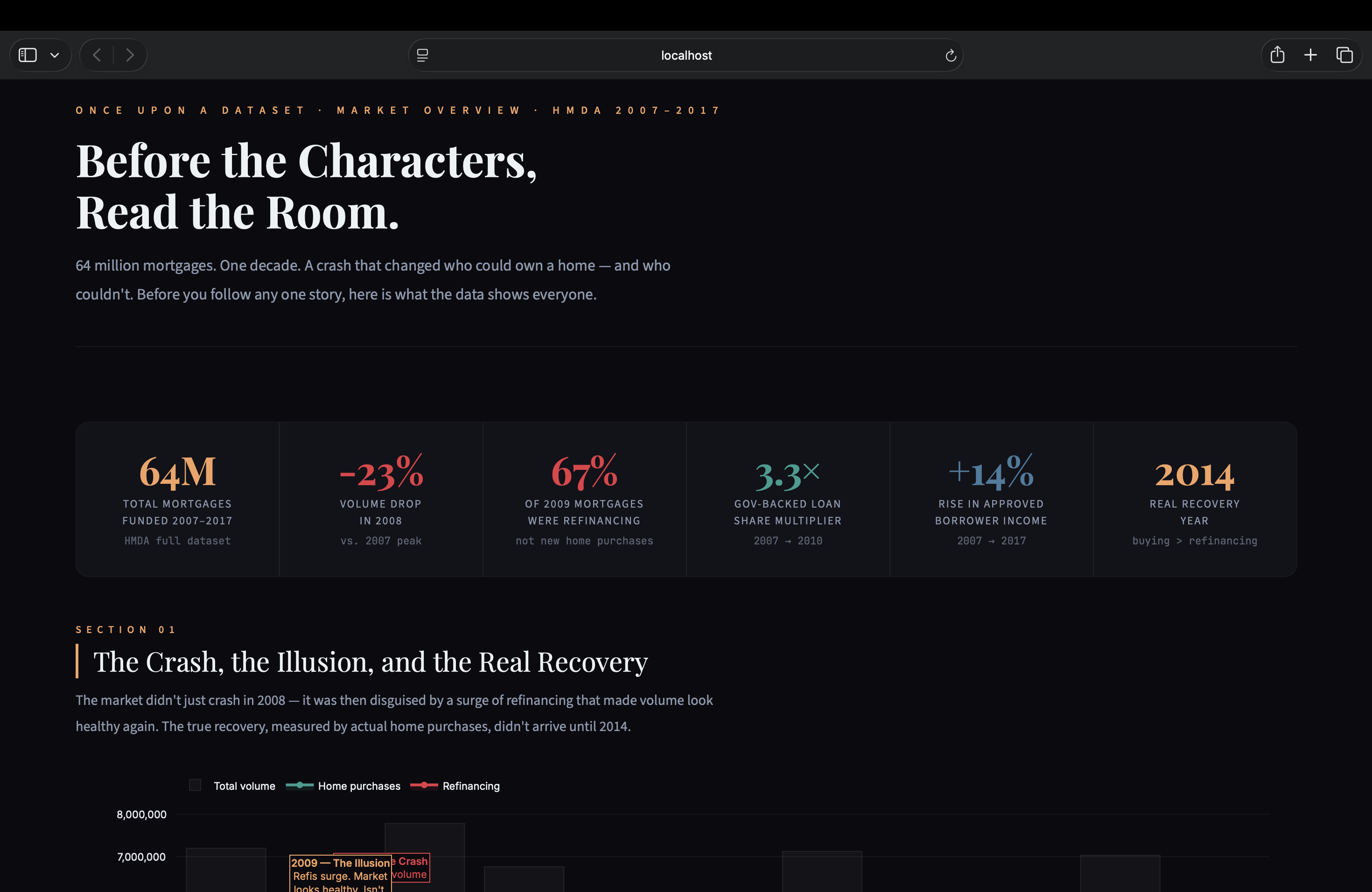
64 million mortgage records. Almost no one understands what they actually show. The same crisis hit five different groups in five completely different ways — we wanted to show that.
What It Does
Turns HMDA mortgage data (2007–2017) into five human stories — a veteran, a first-time buyer, an FHA borrower, an established buyer, and an existing homeowner. Four pages: market overview, character stories, side-by-side comparison, and a raw data explorer.
How We Built It
- Python · Streamlit · Plotly · Pandas · Parquet
- 64M rows pre-aggregated and cached for instant load
- Shared
utils.pyfor design tokens, data, and character definitions across all pages
Challenges We Ran Into
- 2012 missing from CFPB bulk release — documented transparently instead of patching
- Keeping every story claim traceable to a real number in the data
- Custom choropleth maps that tell a different story per character
Accomplishments That We're Proud Of
- The 2009 refinancing illusion chart — visual proof the recovery wasn't real
- Per-character maps with unique color scales and state highlights
- Surfacing the gender gap — female borrowers lost 5pp of market share and never recovered
What We Learned
- Story structure makes data stick — statistics alone don't
- Transparency about data gaps builds credibility, not doubt
- The same decade looks completely different depending on who you are
What's Next for Once Upon a Dataset
- Extend to 2018–2023 data
- Add denial rate analysis
- Public deployment with shareable character links
Built With
- python
- streamlit

Log in or sign up for Devpost to join the conversation.