
OmniSight, AI Visual Companion
Inspiration
Most AI assistants live inside a text box. You type, they respond. That works for writing emails. It doesn't work for the real world.
One of our team members' parents received a medical bill with a charge for a routine bandage application. They had no way to know if that was fair. No tool to scan the bill, no way to check market rates, no one to explain the medical jargon. They just paid it.
That moment stuck with us. The world is full of situations where people need an intelligent second opinion, not in a chat window, but in the moment, looking at the actual thing in front of them. A contract they're about to sign. A medication bottle they can't read clearly. A street sign in a language they don't speak. A product they want to buy but don't know if they're getting a fair price.
Google's Project Astra showed us the potential, a real-time visual agent that sees, understands, and remembers. But Astra was a research prototype. We wanted to build the practical version: a production-ready agent equipped with specialized tools for real-world, high-stakes situations. That's OmniSight.
What It Does
OmniSight is a real-time AI visual companion. You point your camera at the world, speak naturally, and OmniSight sees, understands, and responds, instantly, conversationally, and accurately.
It adapts to 7 specialized modes:
- General :- All-purpose visual companion for everyday use
- Accessibility :- Eyes for the visually impaired. Spatial descriptions, hazard warnings, proactive scene narration
- Education :- Patient tutor that sees your homework, diagrams, and textbooks
- Healthcare :- Scans medication bottles, reads food labels, detects allergens, analyzes medical documents
- Shopping :- Identifies products, compares prices across retailers, spots deals, flags misleading packaging
- Travel :- Translates text in 200+ languages, identifies landmarks, finds nearby places, gives directions
- Professional :- Analyzes contracts, extracts invoice data, flags risky clauses, checks fair pricing
Beyond identification, OmniSight has cross-session memory, it remembers products, prices, documents, and preferences across sessions. Ask "what was that TV we looked at last week?" and it knows. It also has a smart watchlist: set alerts like "notify me if you see Nike shoes under $50" or "watch for peanut ingredients," and OmniSight proactively tells you when it spots a match.
Every session ends with a structured HTML report of all findings, accessible from the History page.
How We Built It
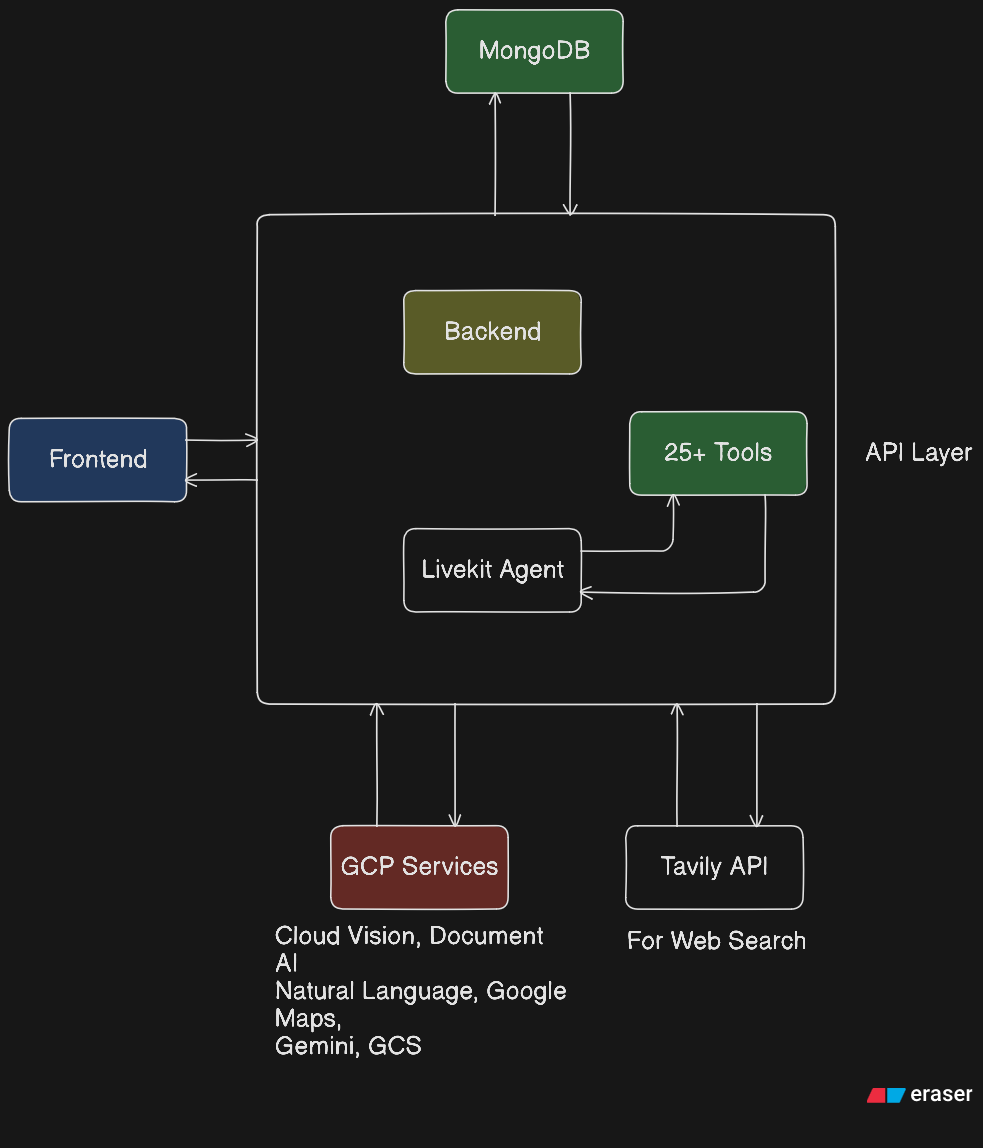
OmniSight has three layers working together:
1. React Client (Frontend)
Built with React 19, Vite, TypeScript, and @livekit/components-react. The client publishes the user's camera and microphone as WebRTC tracks to a LiveKit room. It handles mode selection, session controls (mute, flip camera, disconnect), and the History/SessionDetail views for reviewing past sessions and reports.
2. FastAPI Server (Backend) Handles JWT authentication, session lifecycle, and LiveKit room creation. When a user starts a session, FastAPI creates a LiveKit room, persists a session record to MongoDB, and returns a participant token. On session end, it stores the full transcript, tool logs, observations, and a signed GCS URL for the session recording.
3. LiveKit Agent Worker (The Brain)
A Python livekit.agents.Agent that joins the room, receives the real-time audio/video stream, and runs Gemini Live API (gemini-2.5-flash-native-audio-preview) for natural, interruptible voice conversation. The agent is equipped with 13 specialized tools across 7 categories.
*The Grounding Strategy *
We don't just route images to Gemini and hope for the best. Every analysis is grounded in specialized GCP services:
capture_and_analyzeruns Gemini Vision + Cloud Vision in parallel viaasyncio.gather. Gemini provides rich natural language understanding; Cloud Vision provides structured, high-confidence detections with confidence scores.scan_documentruns Document AI + Gemini in parallel. Document AI extracts structured data (tables, form fields, key-value pairs) with accuracy that generic vision can't match. Gemini reasons on top of that structure.extract_entitiesruns the extracted text through Cloud Natural Language API for reliable entity detection (people, organizations, dates, monetary amounts).
We also built a confidence module (tools/grounding.py) that checks confidence scores from every analysis. When confidence is low, the agent asks the user for more context rather than guessing. It knows when it doesn't know.
The Full Google Cloud Stack:
| Service | Role |
|---|---|
Gemini Live API (gemini-2.5-flash-native-audio-preview) |
Real-time voice conversation with natural interruption handling |
Gemini Vision (gemini-2.5-flash) |
Image analysis, document understanding, clause analysis, post-session reports |
| Cloud Vision API | OCR (200+ languages), landmark detection, logo detection, reverse image search |
| Document AI | Structured extraction from contracts, receipts, bills, forms |
| Natural Language API | Entity extraction with salience scores and entity-level sentiment |
| Google Cloud Storage | Session recording archives via LiveKit Egress |
| Google Maps Places API | Nearby place search with real-time open/closed status |
| Google Maps Routes API | Multi-modal directions (walking, driving, transit, cycling) |
| Google Maps Geocoding API | Address to coordinates conversion |
Voice Stack:
Silero VAD for voice activity detection, LiveKit's English Turn Detector for natural turn-taking, LiveKit Noise Cancellation (BVC) for clean audio, and allow_interruptions=True so users can barge in naturally mid-sentence.
Session Lifecycle: At session start, the agent loads the user's last 20 memories and active watchlist from MongoDB, personalizing the greeting. At session end, Gemini generates a structured post-session analysis (summary, score, sections) from the full transcript and tool logs. Everything is persisted to MongoDB.
Challenges We Ran Into
Hallucination in high-stakes contexts. Early versions routed every image to Gemini vision alone. It was fast, but the hallucination rate was unacceptable for healthcare and legal use cases. The fix was the grounding strategy — using Document AI and Cloud Vision as structured validators, with Gemini reasoning on top. The confidence module was a late addition that made a significant difference.
Real-time latency with multiple APIs. Capturing a frame, running it through Cloud Vision and Gemini in parallel, and returning a spoken response — all while maintaining a live voice conversation — required careful async architecture. Every blocking GCP call is wrapped in asyncio.get_running_loop().run_in_executor() to avoid blocking the event loop. Parallel asyncio.gather calls cut latency roughly in half for the most common tool calls.
Multi-frame consistency. When capturing multiple frames for document scanning or multi-angle analysis, frames can diverge (camera movement, lighting changes). We built a Jaccard similarity-based consistency checker that compares entity sets across frames and warns the agent when results are inconsistent, prompting it to ask for a steadier shot.
Tuning proactive behavior. The agent is designed to speak up without being asked — noticing products, landmarks, documents, hazards. Getting the balance right between "helpful and proactive" and "annoying and intrusive" took many iterations of the system prompt. The mode system helped significantly — each mode has different thresholds for when to speak up.
Cross-session memory design. A memory system that's useful without being noisy is harder than it sounds. We settled on a category-based approach (product, document, price, landmark, translation, preference) with keyword search, loading the 20 most recent memories at session start as context for the greeting.
Accomplishments That We're Proud Of
The grounding pipeline. Running Document AI, Cloud Vision, and Gemini in parallel — then combining their outputs intelligently; is genuinely novel. Most real-time visual agents are just "camera → LLM → response." OmniSight routes to the right specialized service for every task.
Natural interruption handling. Thanks to Gemini Live API, Silero VAD, and LiveKit's turn detection, users can interrupt mid-sentence and the agent recovers naturally. It feels like talking to a person, not a chatbot.
Cross-session memory that actually works. The agent remembers what it's seen across sessions and references those memories naturally in conversation. "Last time we looked at this product, the best price was $749 at Amazon." That's a fundamentally different experience from a stateless assistant.
7 specialized modes with distinct behavior. The same 13 tools, but the agent's priorities, communication style, and proactive behavior adapt completely to the context. Healthcare mode warns about expired medications. Accessibility mode uses spatial language. Professional mode is concise and flags compliance issues.
A complete, production-ready stack. JWT auth, MongoDB persistence, GCS recording archives, signed URLs, post-session analysis, HTML report generation, session history — this isn't a demo. It's a full application.
What We Learned
Grounding matters more than model quality. A well-grounded Gemini Flash response is more reliable than an ungrounded Gemini Pro response for structured tasks. Specialized APIs exist for a reason — use them.
The voice experience changes everything. When users can interrupt naturally and the agent recovers seamlessly, the interaction feels fundamentally different from a chat interface. This isn't a UX improvement; it's a category shift. Gemini Live API makes this possible in a way that turn-based systems simply can't replicate.
Proactive AI is hard to tune but worth it. Most AI assistants are reactive — they wait for a question. Building an agent that proactively notices things (a product, a hazard, a document being held up) and speaks up at the right moment is genuinely difficult. But when it works, it feels like having a knowledgeable friend with you, not a tool you have to operate.
Cross-session memory transforms a tool into a companion. Stateless assistants are useful. Stateful companions are valuable. The difference is memory, and users notice it immediately.
Google Cloud's ecosystem is genuinely cohesive. The integration between Gemini, Cloud Vision, Document AI, Natural Language API, and GCS is seamless in a way that mixing services from different providers isn't. The shared credential model, consistent async patterns, and complementary capabilities made building OmniSight significantly faster than it would have been otherwise.
What's Next for OmniSight
Wearable integration. OmniSight is designed for a phone camera today, but the architecture maps directly to smart glasses. The LiveKit WebRTC layer is hardware-agnostic — connecting a glasses camera feed is a configuration change, not a rewrite.
Richer watchlist intelligence. The current watchlist uses keyword matching. The next version will use semantic similarity ;so "alert me if you see a good deal on running shoes" matches "Nike Air Zoom 40% off" without needing exact keyword overlap.
Offline memory summarization. Right now, memories are stored as raw key-value pairs. We want to periodically summarize them with Gemini to build a richer user profile :- preferences, habits, frequently seen items, that makes the agent more personalized over time.
Multi-agent collaboration. The long-term vision is a unified agent ecosystem where OmniSight can hand off tasks to specialized agents, "I found this product, let me hand you to the shopping agent for a deeper price analysis."
Expanded language support. The architecture supports 200+ languages for OCR, but the agent's conversational layer is currently English-first. Adding multilingual conversation support is the next step for global accessibility.
Built With
- fastapi
- gcp
- gemini
- livekit
- mongodb
- python
- react
- tailwindcss
- tavily
- typescript

Log in or sign up for Devpost to join the conversation.