-
-
home page
-
-
-
-
Inspiration
We've all been there, watching Bitcoin hit $60k and thinking, "I should have bought it at $1." Or seeing a prediction market show "78% probability" and wondering, "Is that actually accurate, or is this just crowd psychology?"
Prediction markets promised to aggregate collective intelligence into probabilities, but they left users with a critical problem: no one explains the reasoning. You get a number. No context. No analysis. Just trust us, or don't.
We realized there was a massive gap between seeing a probability and understanding whether it's justified. Hedge funds pay analysts six figures to research these questions. Retail users? They're left gambling with extra steps.
What if we could democratize that analysis? What if anyone could get institutional-grade research instantly, transparently, and for free?
That's why we built Omnisense.
What it does
Omnisense transforms prediction market analysis from guesswork into science.
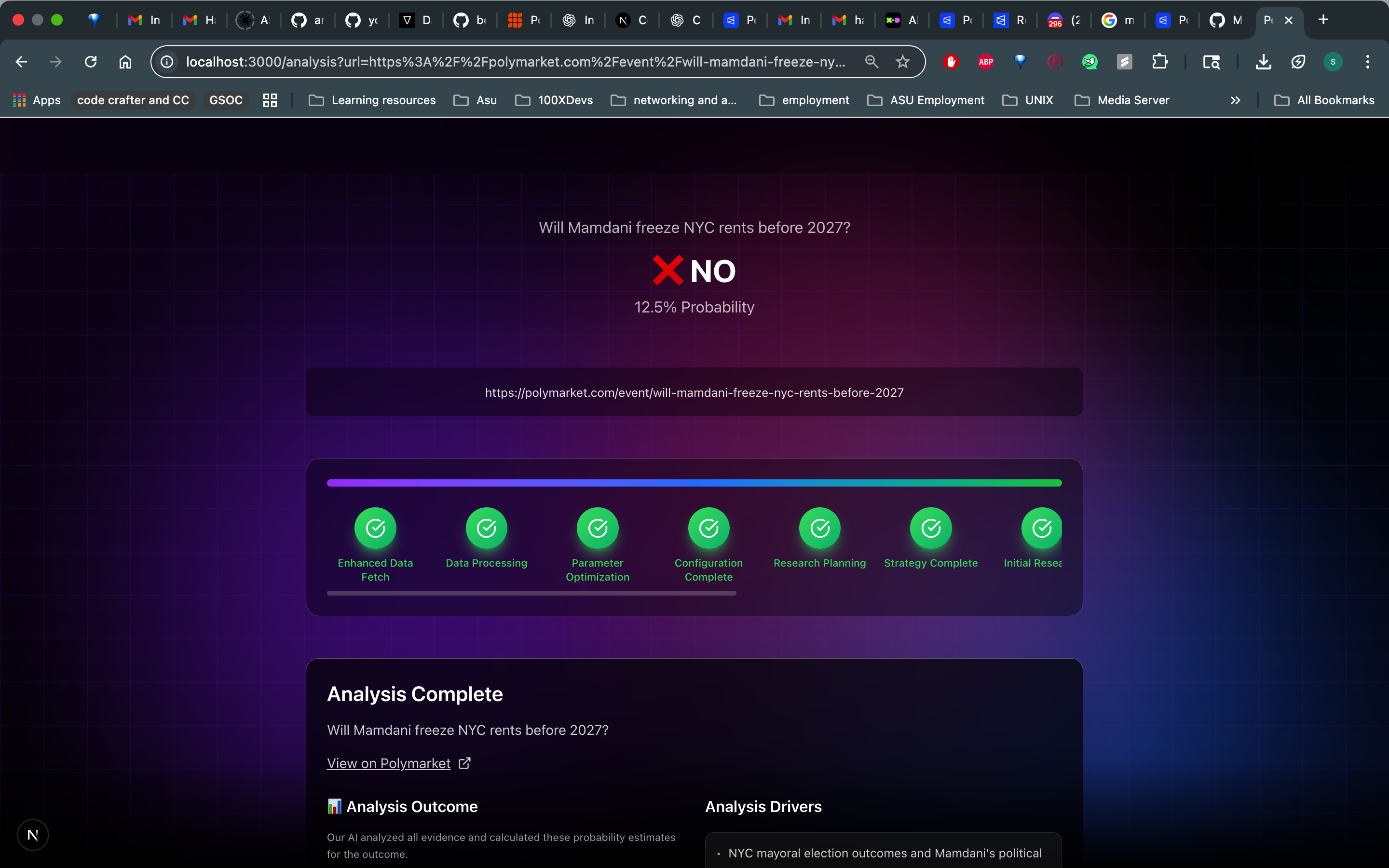
Drop any Polymarket URL into Omnisense, and within 4 minutes, you get:
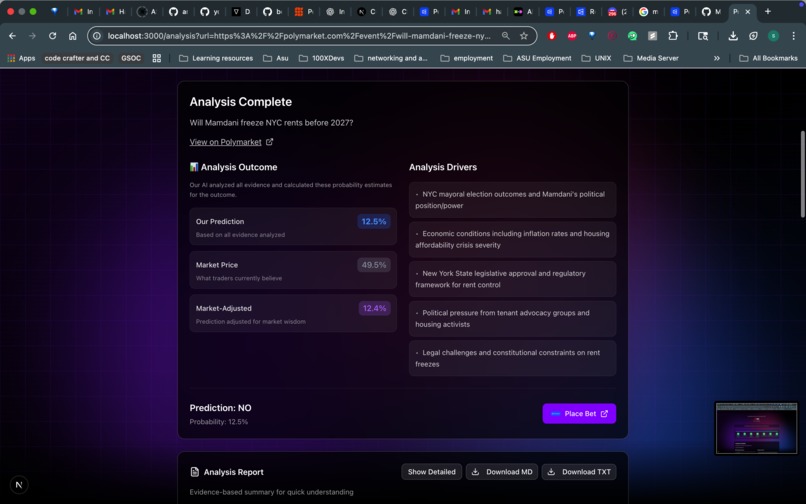
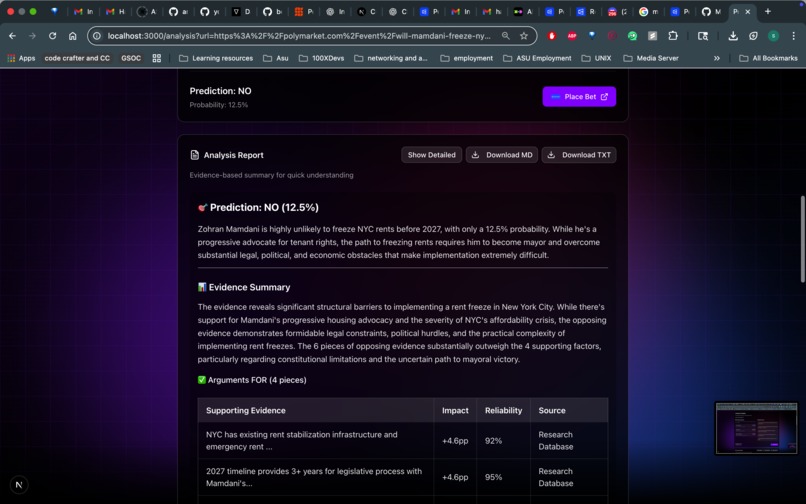
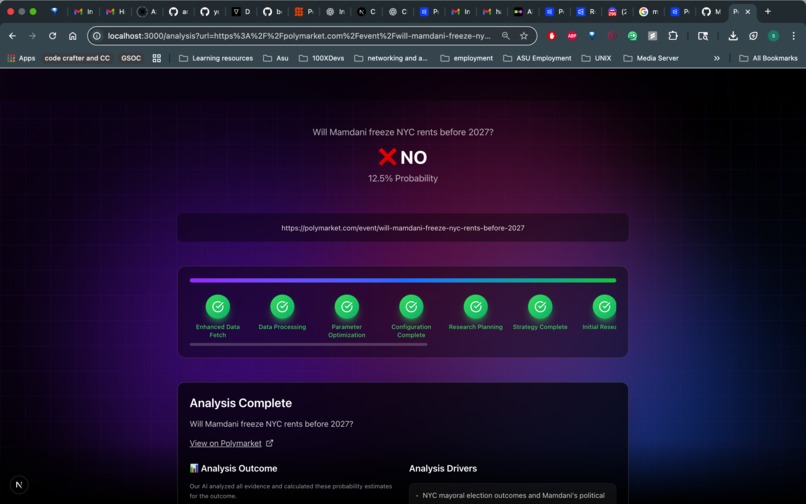
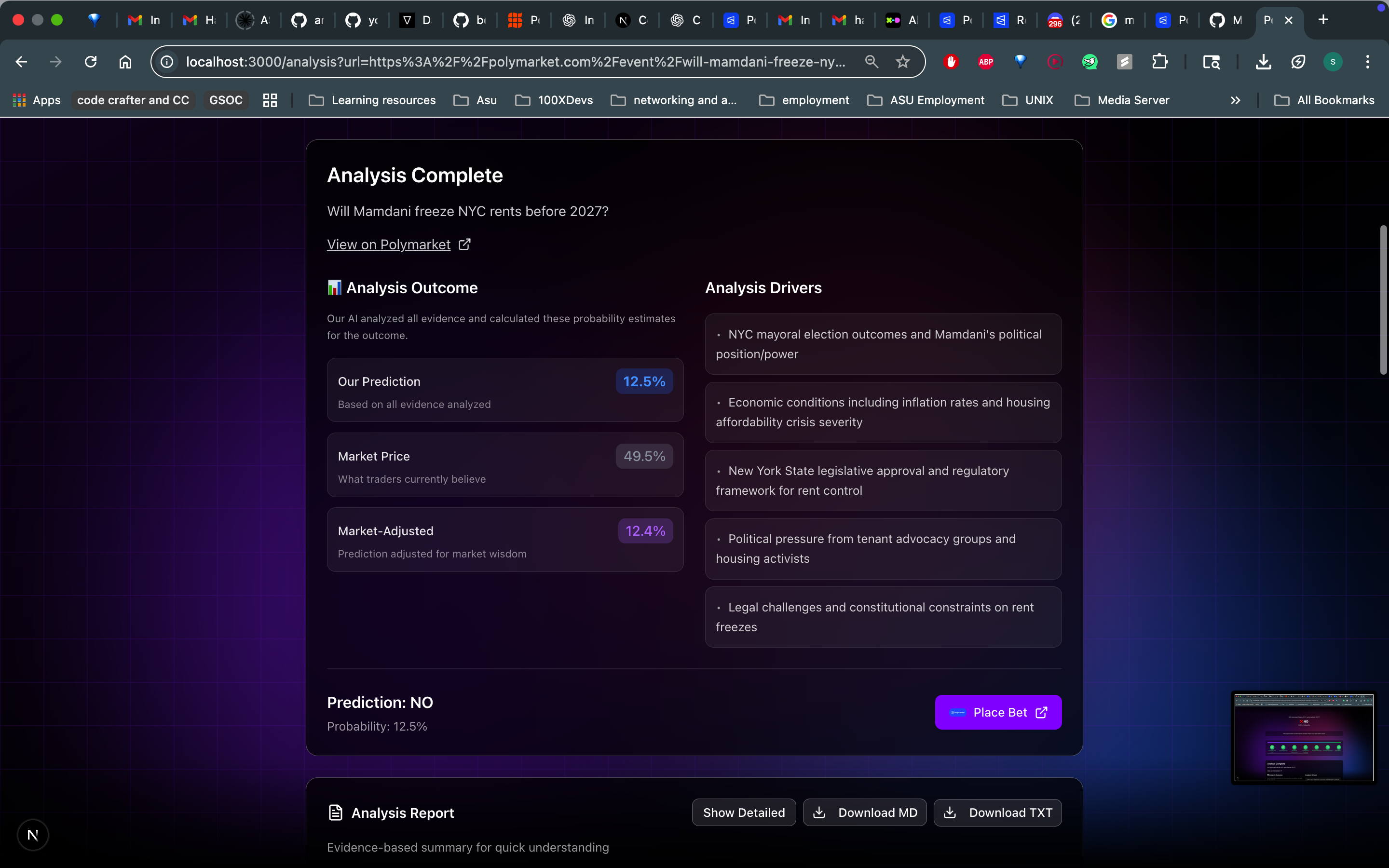
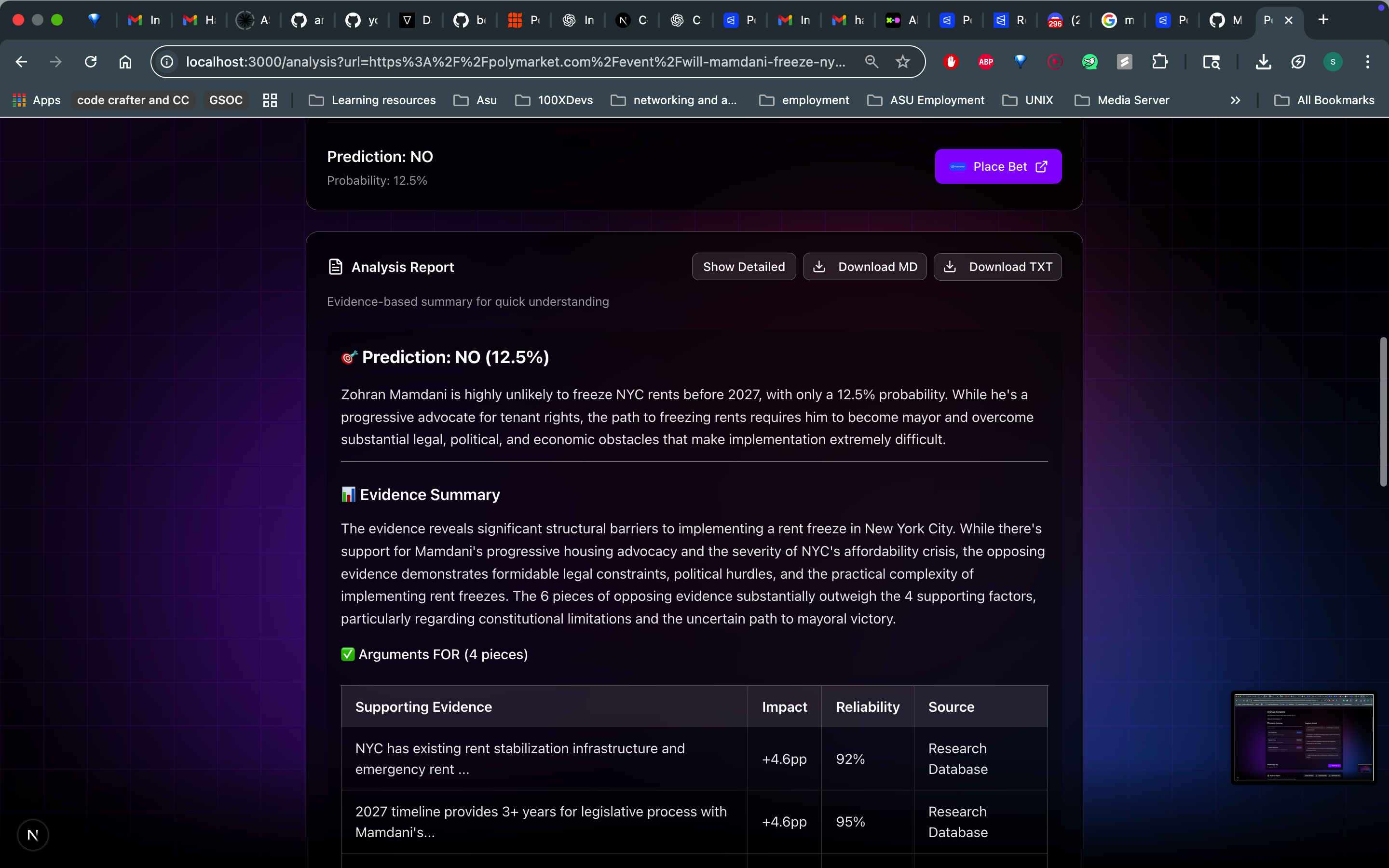
- A clear verdict: YES or NO, with confidence percentage
- Transparent reasoning: Not just "here's a number" here's why, with evidence
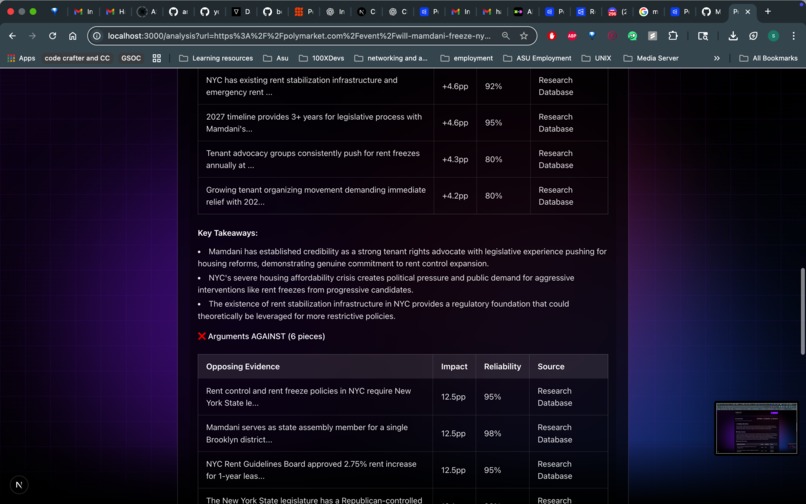
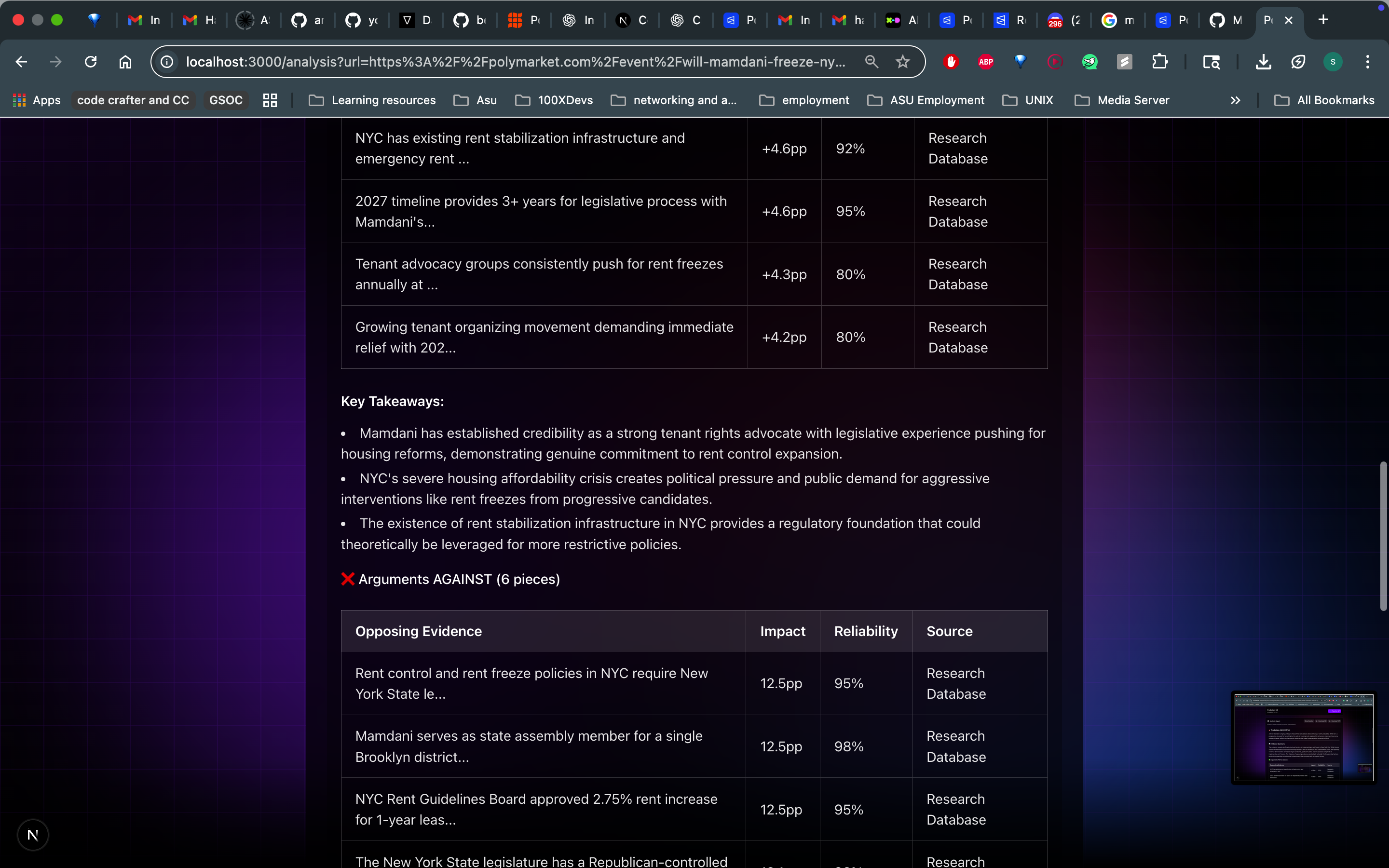
- Multi-source research: AI agents that search dozens of sources, cross-reference claims, and identify key drivers
- Bayesian probability analysis: Mathematical aggregation of evidence using base rates, likelihood ratios, and proper uncertainty quantification
- Structured report cards: Bull/bear cases, evidence quality scores, key factors, and edge analysis
The technical magic:
We built a multi-agent AI orchestration system where specialized agents collaborate like a research team:
- Planner - Breaks down complex questions into researchable sub-questions
- Researcher - Conducts deep web searches using Valyu's distributed search network
- Critic - Challenges assumptions, identifies biases, plays devil's advocate
- Analyst - Performs Bayesian probability updates, calculates confidence intervals
- Reporter - Synthesizes everything into a clear, actionable report
Each agent is powered by Frontier LLM (Claude 4.5), with a strategy pattern that selects the optimal model for each task. Fast models for planning, smart models for analysis, creative models for edge case discovery.
How we built it
Stack:
- Frontend: Next.js 15 (App Router), React 19, Tailwind CSS 4
- AI Orchestration: Anthropic
- Data Layer: Model Context Protocol (MCP) for Polymarket integration
- Search: Valyu network for distributed web search across uncensored sources
- Math: Custom Bayesian aggregation engine with $\text{logit}$ transforms:
$$P(\text{outcome} | E_1, E_2, ..., E_n) = \sigma\left(\text{logit}(P_0) + \sum_{i=1}^n \log\left(\frac{P(E_i|\text{outcome})}{P(E_i|\neg\text{outcome})}\right)\right)$$
Where $\sigma(x) = \frac{1}{1 + e^{-x}}$ is the sigmoid function.
Architecture highlights:
- Agent communication via streaming: Each agent streams thoughts in real-time, allowing the orchestrator to adjust strategy dynamically
- Evidence clustering: Similar evidence points are clustered using semantic embeddings to avoid double-counting
- Confidence calibration: We track our prediction accuracy over time and adjust confidence intervals accordingly
Challenges we ran into
1. The "hallucination in consensus" problem
Early on, we noticed multiple agents would hallucinate similar wrong facts. Why? Because they were all using the same flawed source, or worse, one agent's confident mistake would influence others.
Solution: We implemented a critic agent whose entire job is to challenge consensus. If all agents agree too easily, the critic forcibly searches for counter evidence. We also added source diversity scoring evidence from 10 sources that all cite the same original article, which counts as 1 source, not 10.
2. Bayesian math that doesn't explode
Naive Bayesian updating can lead to absurd confidence levels. Find one piece of strong evidence and suddenly you're "99.9% certain." But the real world has uncertainty we can't measure.
Solution: We work in $\text{logit}$ space (log-odds) and apply dampening factors based on evidence quality. A peer-reviewed study gets higher weight than a tweet. We also cap individual evidence contributions. No single piece of evidence can shift probability more than 20%.
3. Speed vs. depth tradeoff
Users want answers in seconds, but good research takes time. Early versions took 12 minutes.
Solution:
- Parallel agent execution: Researchers work simultaneously on different sub-questions
- Strategic model selection: Efficient models for planning, advanced models (Claude Sonnet 4.5) for complex analysis
- Lazy evaluation: We compute deep analysis on demand rather than up front
- Streaming UX: Show progress in real-time so users see the process before completion
4. Rate limits and cost explosions
Running 5+ AI agents with multiple API calls per analysis gets expensive fast. And hitting rate limits mid-analysis breaks the entire flow.
Solution:
- Intelligent caching: Similar questions reuse research from recent analyses
Accomplishments that we're proud of
We actually developed a useful product. Not a demo. Not a prototype. A tool people can use right now to make better decisions.
The math works. Our Bayesian aggregation produces calibrated probabilities. When we say 70%, we mean it (we track Brier scores to verify).
Sub-4-minute analysis that would take a human analyst hours. The speed-quality tradeoff is real, and we optimized the hell out of it.
Transparency by default. We show our work. Every claim is sourced. Every probability update is explained. No black boxes.
The UX is beautiful. AI tools are often ugly command-line interfaces. We built something that feels magical, animated loading states, smooth transitions, shareable cards.
Multi-agent orchestration that scales. Our agent system is modular and extensible. Adding new agent types (fact-checker, sentiment analyzer, etc.) takes <100 lines of code.
What we learned
1. AI agents are powerful, but stupid without constraints
Giving an LLM "autonomy" doesn't make it smart. It makes it confidently wrong faster. The magic is in the orchestration of how you structure tasks, challenge outputs, and aggregate results.
2. Users don't want AI, they want answers
Nobody cares that we're using Complex LLMs. They care whether the verdict is right. We learned to hide complexity and surface clarity. Simple models perform the best.
3. Prediction markets are tough to analyze
These aren't simple yes/no questions. They're geopolitical puzzles with hidden variables, time dependencies, and adversarial incentives. Respect for the quants who do this for a living went
4. Bayesian reasoning is unintuitive, even for smart people
Most users don't understand base rates. They overweigh vivid evidence. Our job isn't just to calculate probabilities, it's to teach probabilistic thinking through our interface.
What's next for Omnisense
Short term (next 3 months):
- Portfolio mode: Analyze multiple markets at once, get diversification recommendations
- Alert system: Get notified when our analysis shifts significantly (e.g., confidence drops from 80% to 60%)
- Chat interface: Ask follow-up questions, explore specific sub-factors
- Accuracy tracking: Public dashboard showing our historical predictions vs. outcomes
Medium term (6-12 months):
- Custom agent marketplace: Let users add specialized agents (sports stats analyzer, crypto on-chain data, etc.)
- Scenario simulation: "What if Trump drops out?" and see how probabilities shift
- Trading integration: Connect wallet, get analysis + one-click trade execution
Long term (the vision):
We want Omnisense to become the layer that makes prediction markets trustworthy.
Right now, prediction markets are a niche. Why? Because most people don't trust them. The probabilities feel arbitrary. The reasoning is hidden. The incentives are murky.
Omnisense adds the missing layer: transparent, AI-powered analysis that anyone can verify.
Imagine a world where:
- News articles cite Omnisense analysis for probability claims
- Businesses use Omnisense for risk assessment and scenario planning
- Researchers use our API to study forecasting accuracy at scale
- Governments consult prediction markets because the reasoning is auditable
Prediction markets + AI analysis = A more informed world.
That's what we're building toward. One market at a time.
Built with love and a concerning amount of caffeine
Built With
- anthropic
- api
- claude
- mcp
- next.js
- polymarket
- react
- smithery
- typescript
- valyusearch
- wagmi



Log in or sign up for Devpost to join the conversation.