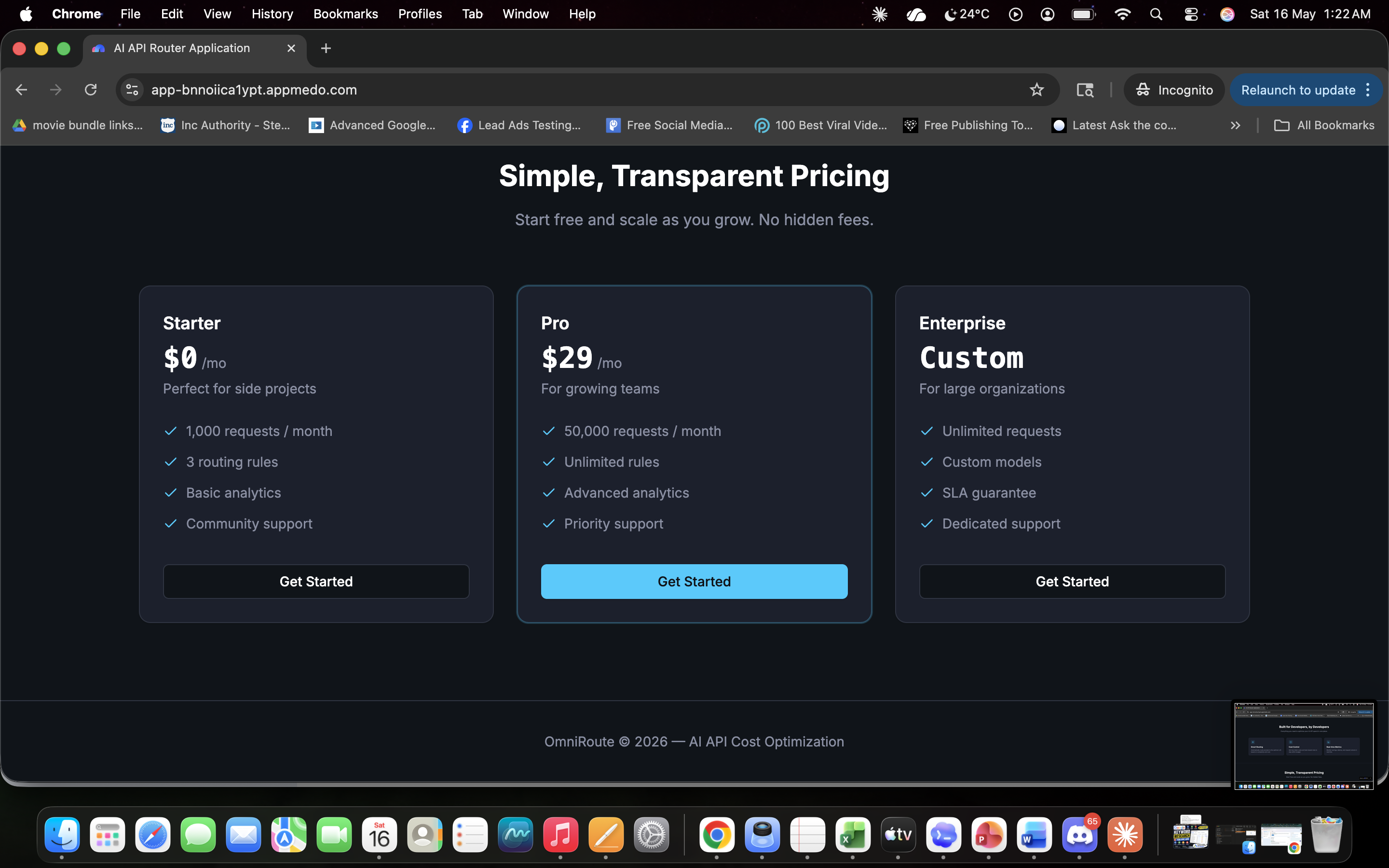
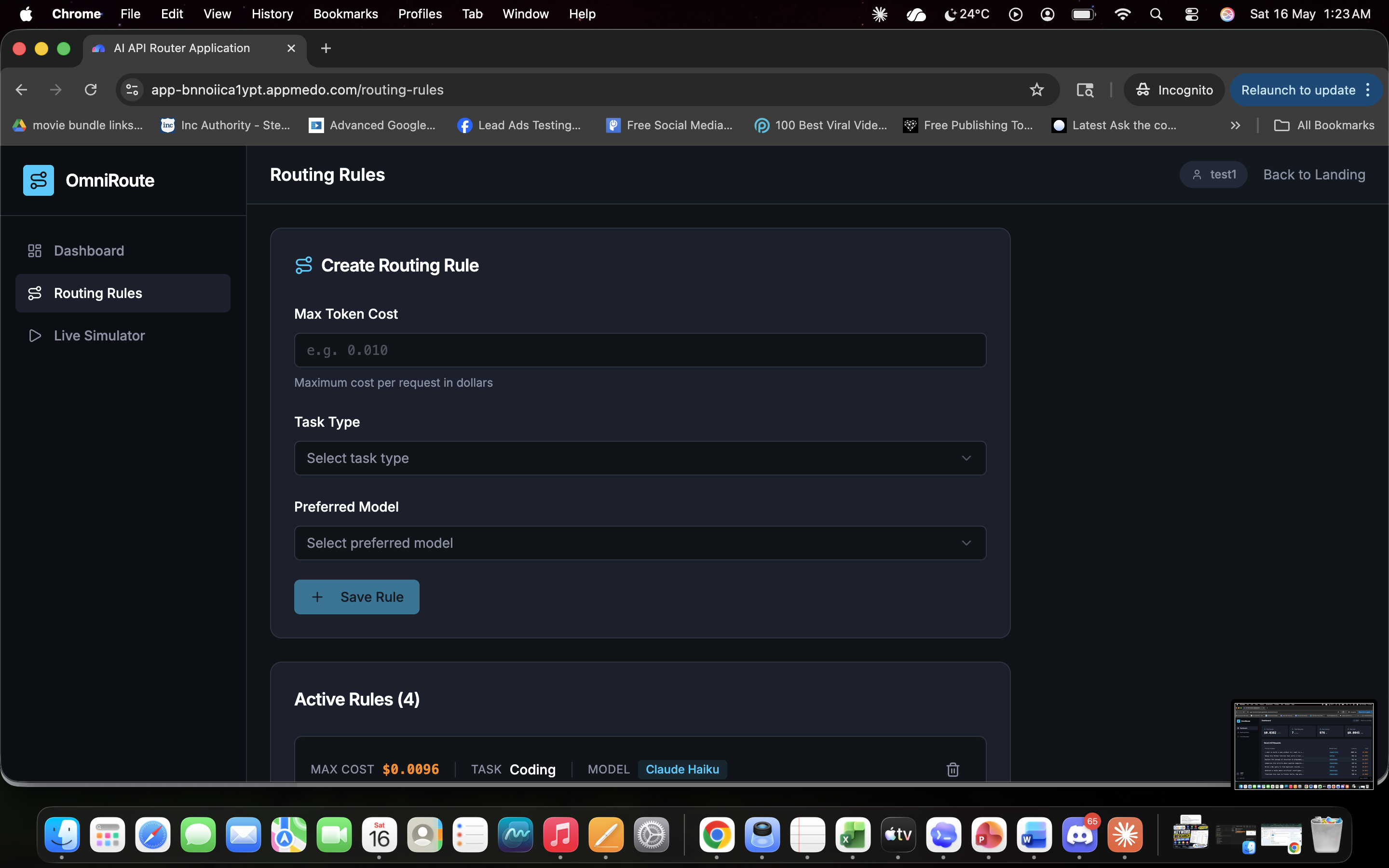
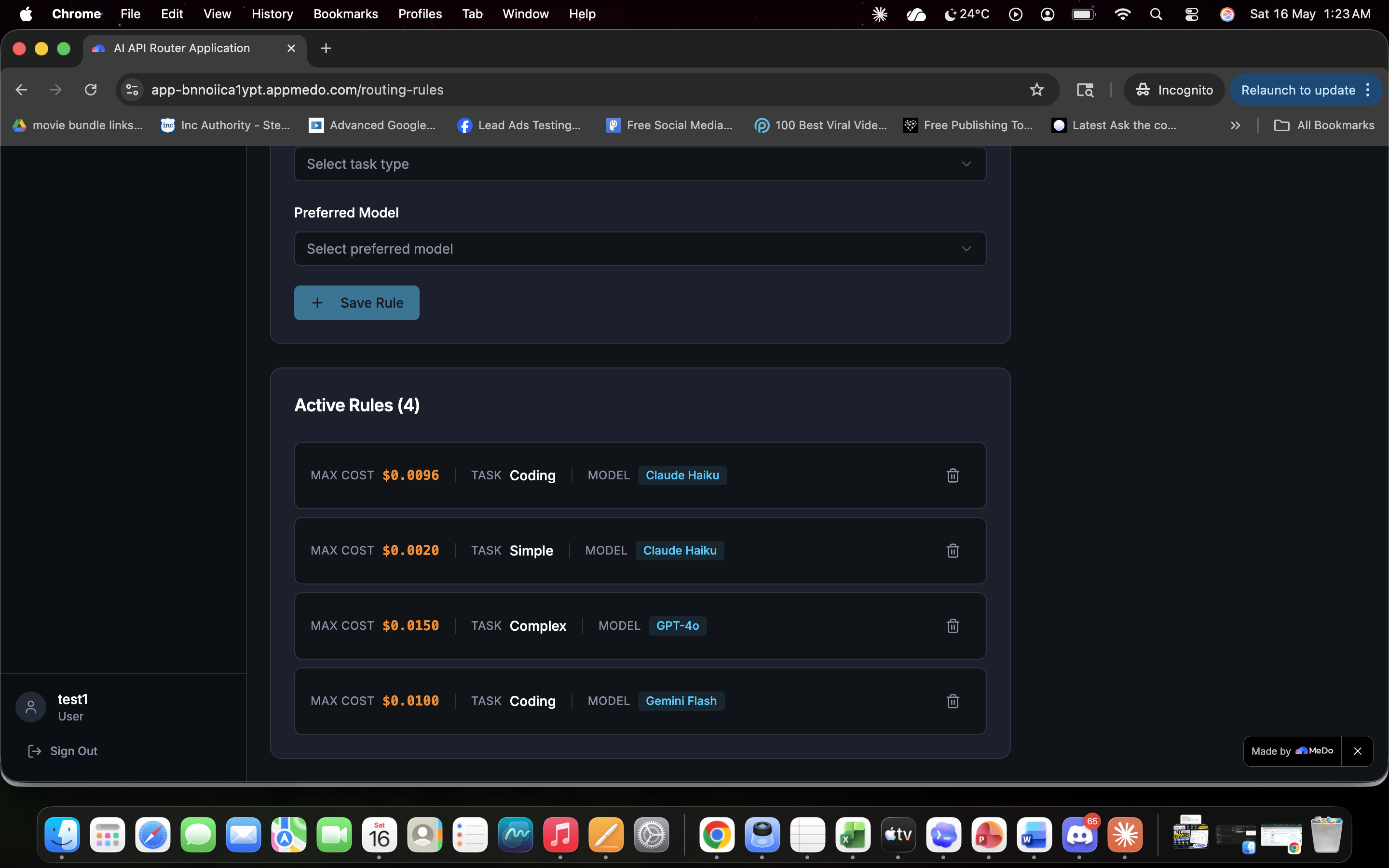
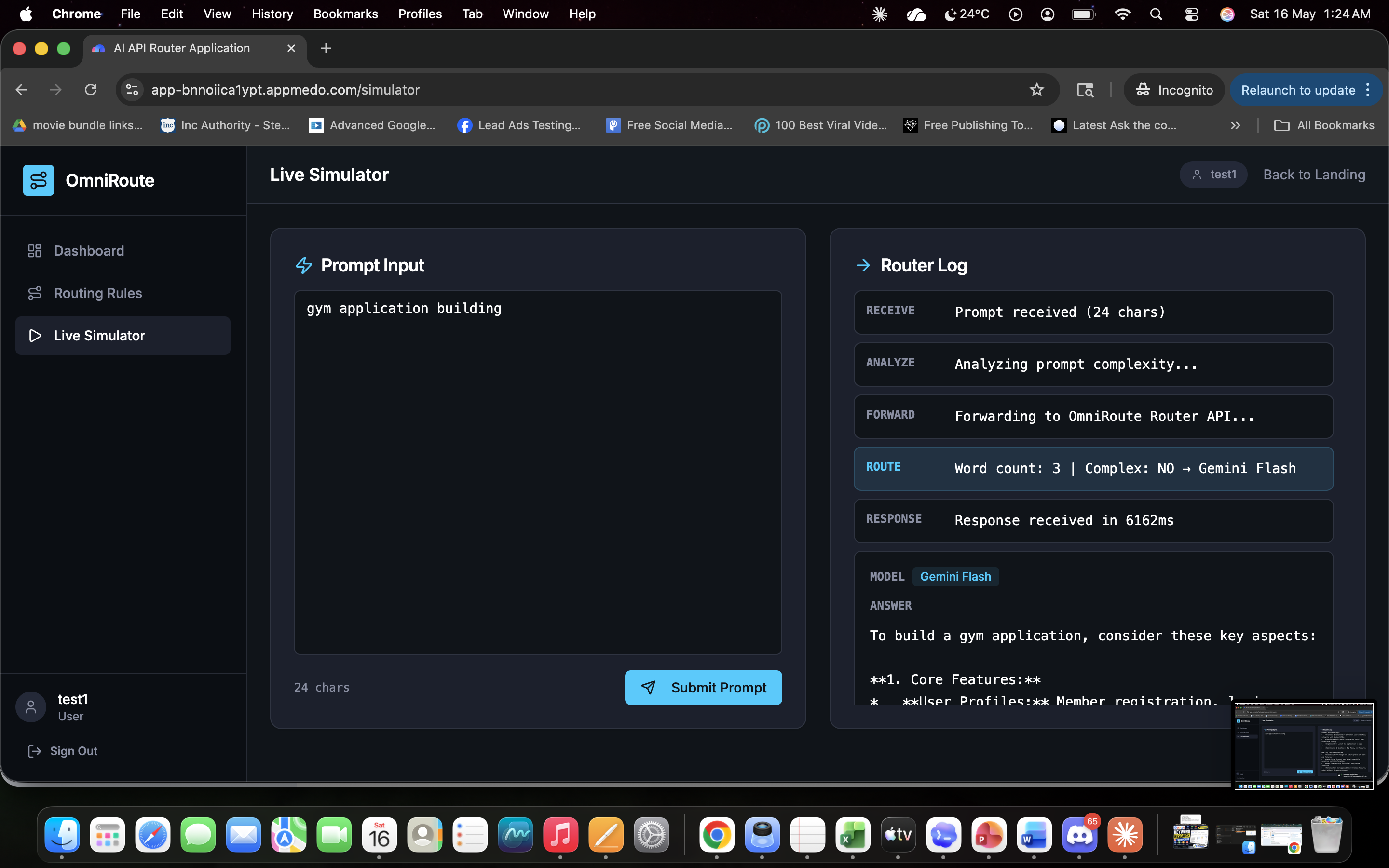
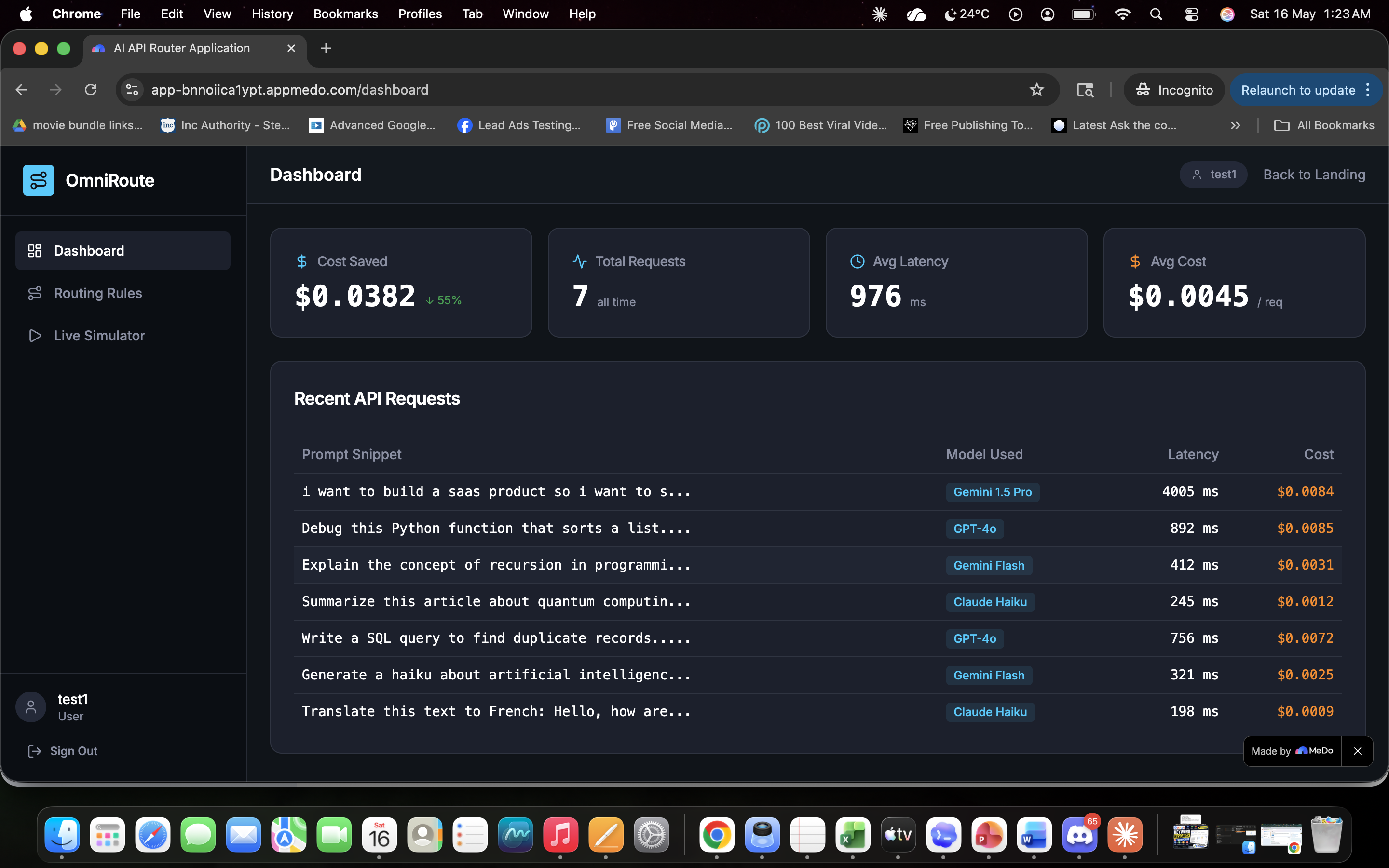
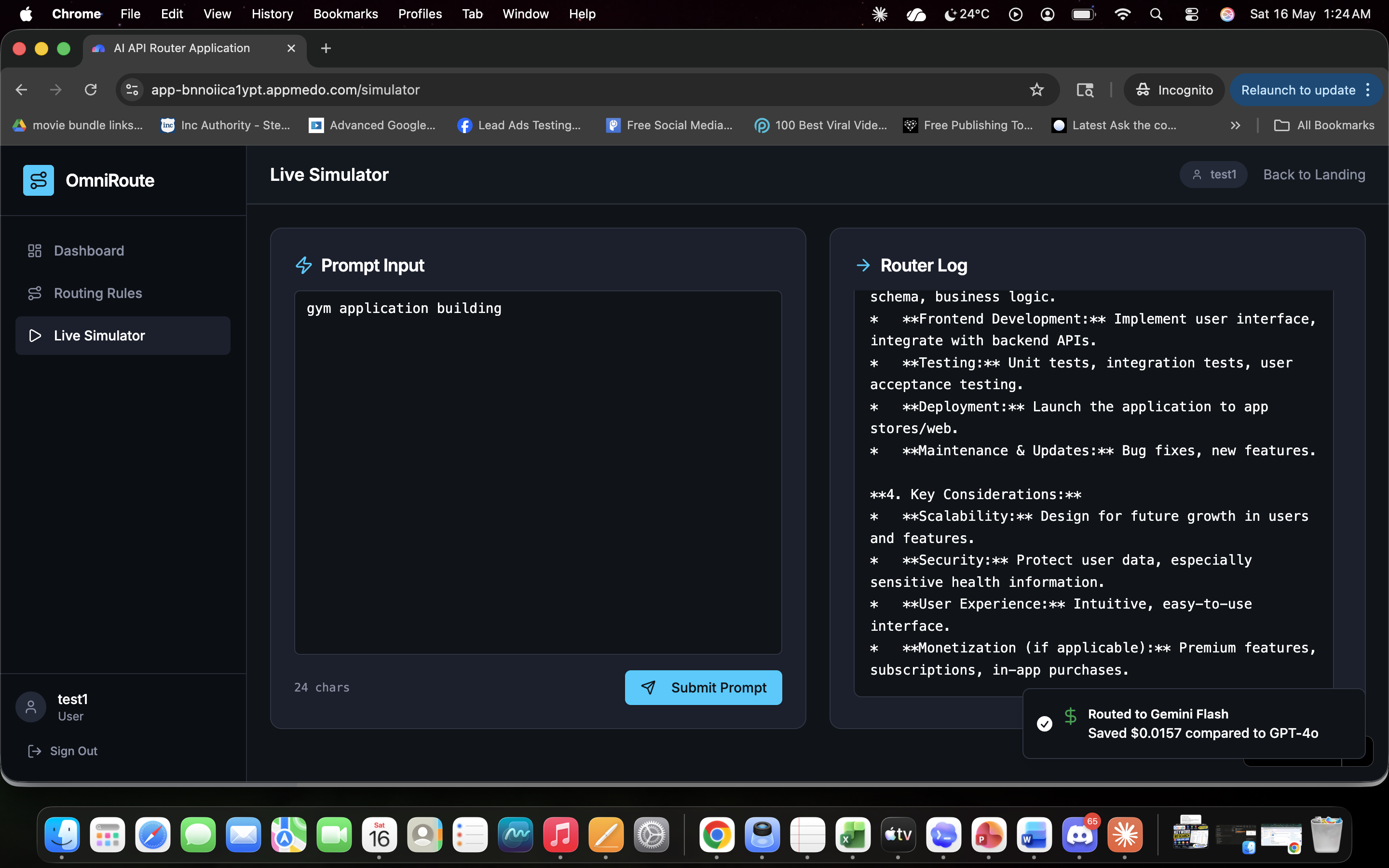
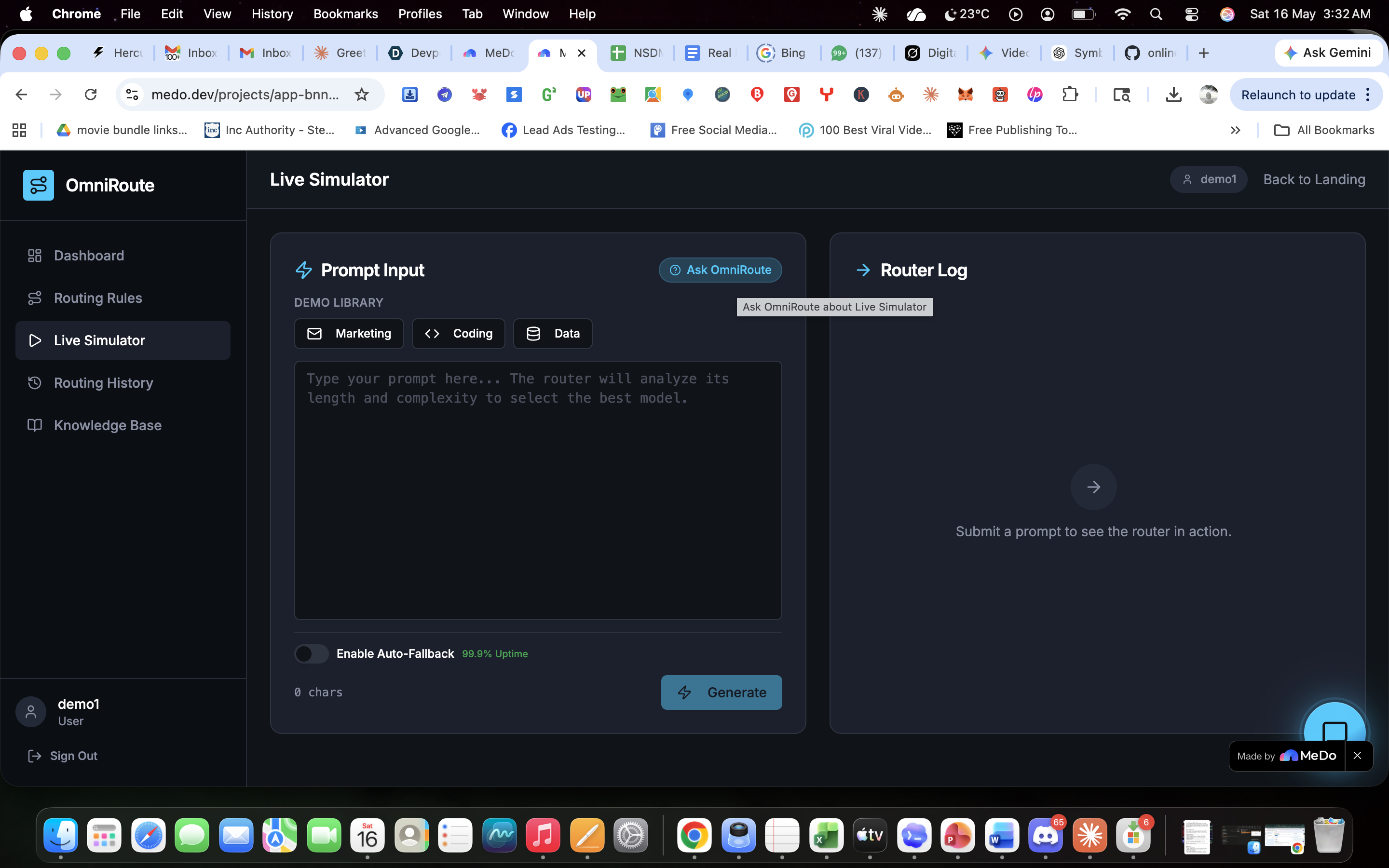
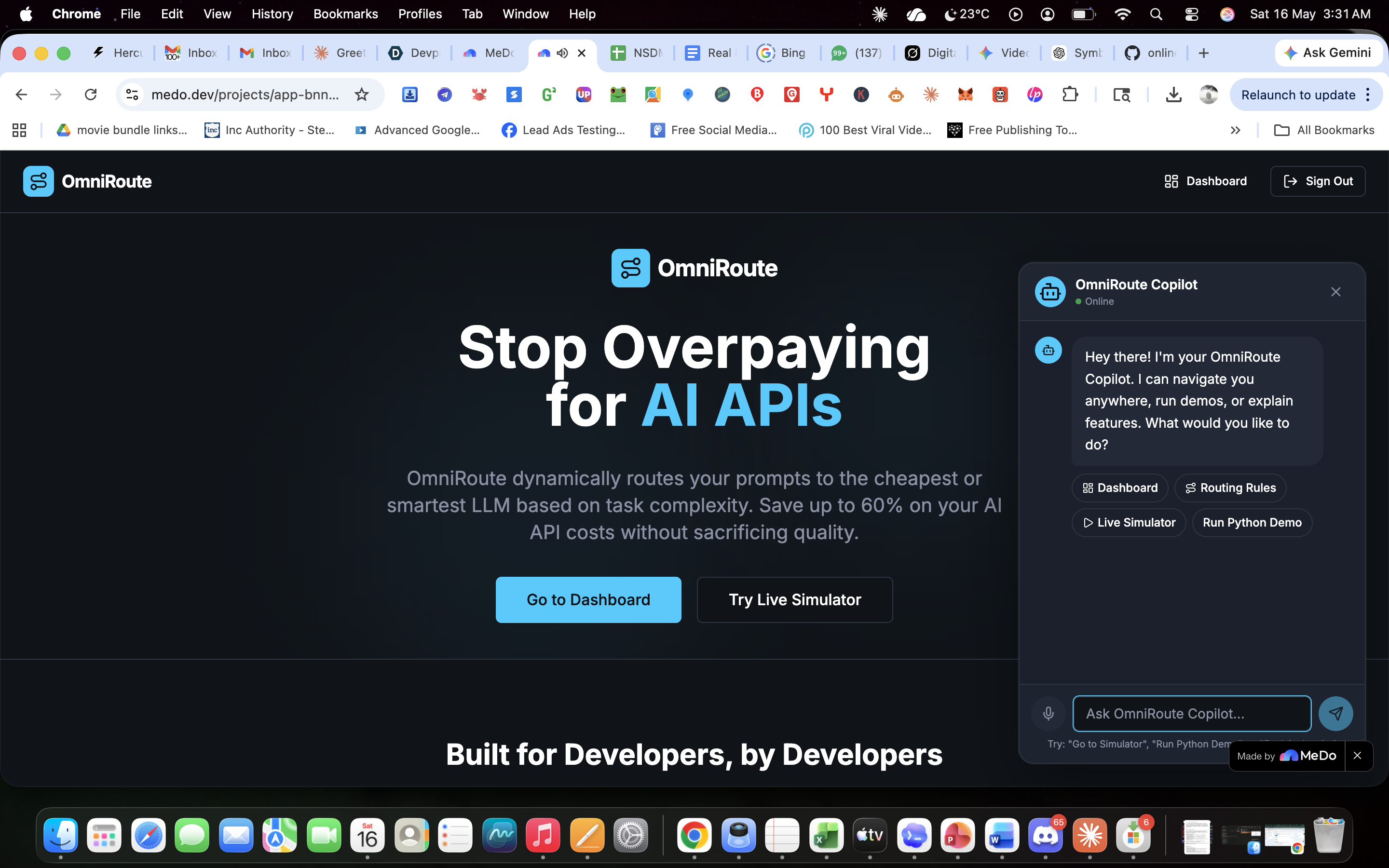
OmniRoute: The Cognitive Load Balancer for AI APIs💡 What Inspired UsAfter a decade of running performance marketing campaigns and developing SEO platforms, a massive bottleneck became obvious: the cost of scaling AI features. When managing multi-LLM architectures, sending every single user query to a heavy, premium model like GPT-4o or Gemini 1.5 Pro is financial suicide.If a user asks a system to format a basic meta description, and the application routes that to a premium reasoning engine, it burns through budget unnecessarily. We needed a cognitive load balancer—a smart gateway that sits between the application and the APIs to analyze the intent and length of a prompt, routing it to the most cost-effective model without sacrificing speed or quality. We built OmniRoute to stop the financial bleed for SaaS founders and agencies.🏗️ How We Built ItOmniRoute was developed entirely on the MeDo platform, allowing for rapid iteration of both the frontend UI and the backend logic.1. The Routing Engine: We utilized Edge Functions to build the core logic layer. The engine intercepts the payload, calculates word counts, and scans for intent. Here is a simplified look at our edge routing logic:JavaScript// OmniRoute Cognitive Logic Gate function determineRoute(prompt, wordCount) { const complexKeywords = ['AEO', 'ROAS', 'architecture', 'python']; const hasComplexIntent = complexKeywords.some(kw => prompt.includes(kw));
if (wordCount > 50 || hasComplexIntent) {
return { model: "Gemini 1.5 Pro", reason: "Deep Reasoning Required" };
}
return { model: "Gemini 1.5 Flash", reason: "Simple Task Optimization" };
}
- The Math Behind the Savings: By dynamically shifting simple queries to lightweight models, we optimize the overall expenditure equation. If $C$ represents the cost per request, the total savings over $n$ queries is calculated as:$$\text{Total Savings} = \sum_{i=1}^{n} (C_{\text{premium}} - C_{\text{optimal}})_i$$3. The Voice Copilot: To elevate the UX, we integrated a native Voice Copilot. Instead of relying on slow, expensive third-party audio APIs, we leveraged the browser's native window.speechSynthesis and webkitSpeechRecognition to enable zero-latency, voice-driven navigation and template execution.4. ROI Analytics & Audit Logging: We tied the Edge Function outputs directly into a database, mapping that data to responsive charts on the dashboard to visualize real-time API cost savings and model distribution.🧗 The Challenges We FacedThe most difficult technical hurdle was simulating the complex routing environment accurately without writing custom fetch wrappers for OpenAI, Google, and Anthropic endpoints right out of the gate. We had to design an architecture that mocked the external API latency and costs for the MVP, while keeping the logic strictly decoupled so the real endpoints can be dropped in for production seamlessly.Additionally, integrating the Web Speech API alongside React's Hot Module Replacement (HMR) caused initial context crashes, requiring us to build safe fallback objects to ensure the Copilot didn't break the application during live testing.🧠 What We LearnedWe proved that infrastructure tools do not have to be visually boring. By wrapping a highly technical backend routing engine in a sleek, dark-mode UI with an interactive voice agent, we learned how to make developer tools accessible to agency owners and executives. We also mastered the translation of raw JSON request logs into tangible, visual ROI metrics—proving that the best way to sell an API tool is to show the user a chart of their savings going up!*** This formatting will render beautifully on their platform. Let me know what the next question on the submission form is!
Built With
- 3
- anthropic
- api
- claude
- google-gemini-1.5-flash
- google-gemini-1.5-pro
- haiku
- javascript-(es6+)
- medo
- medo-app-builder
- medo-edge-functions
- native
- openai-gpt-4o
- react.js
- recharts
- speech
- web

Log in or sign up for Devpost to join the conversation.