-
-
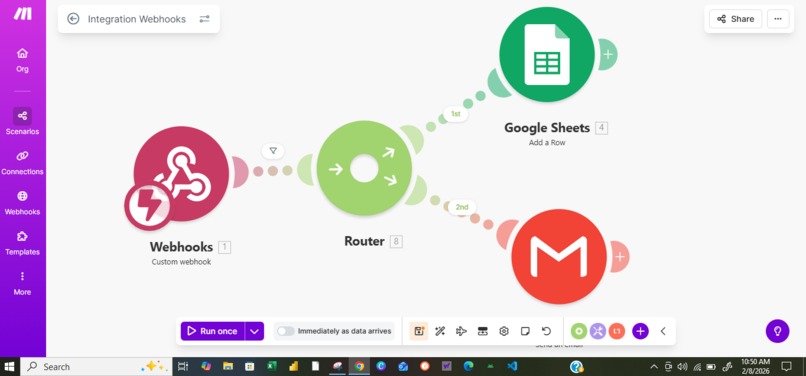
omninexus-orchestration-flow.png
-
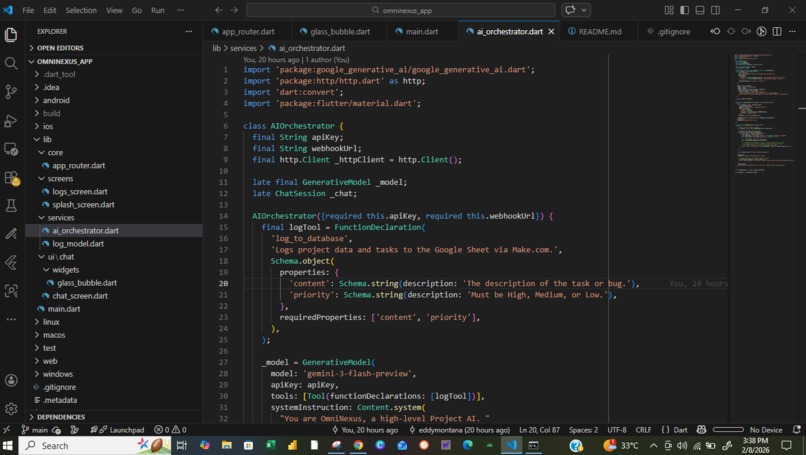
omninexus-code-architecture.png
-
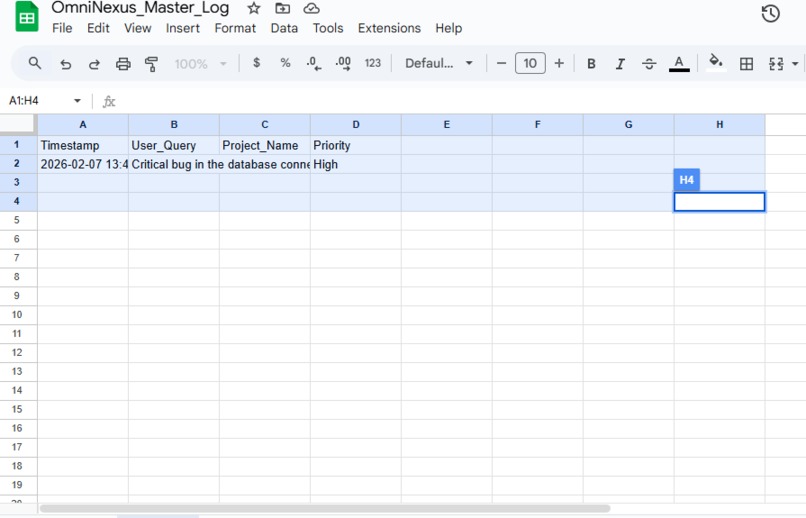
omninexus-database-audit.png
-
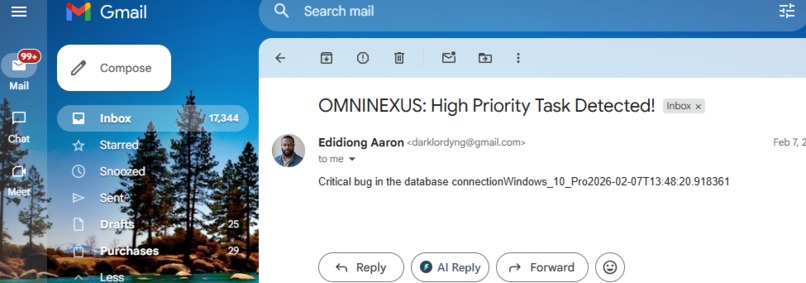
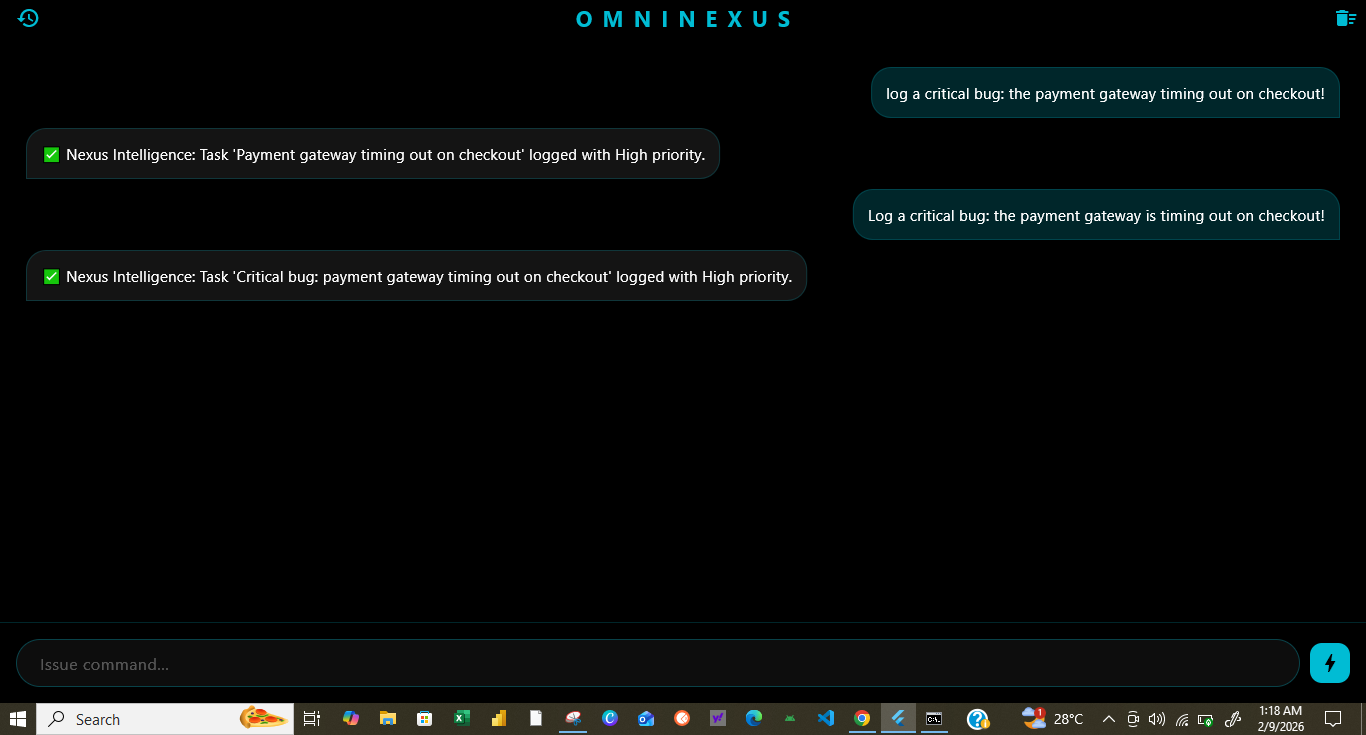
omninexus-priority-alert.png
-
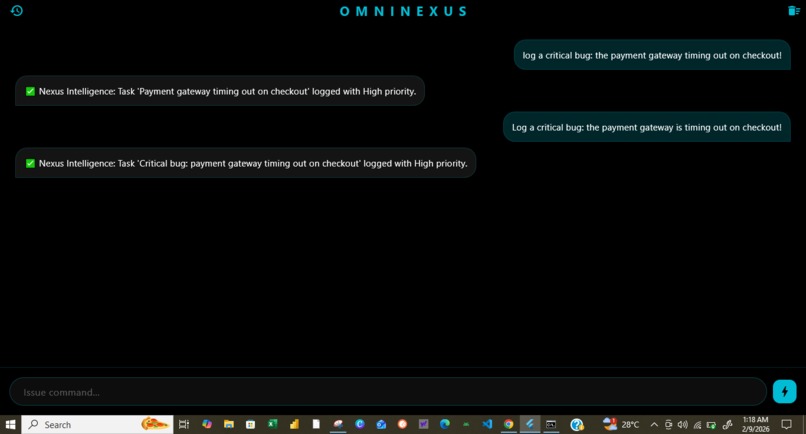
omninexus-ui-main.png
-
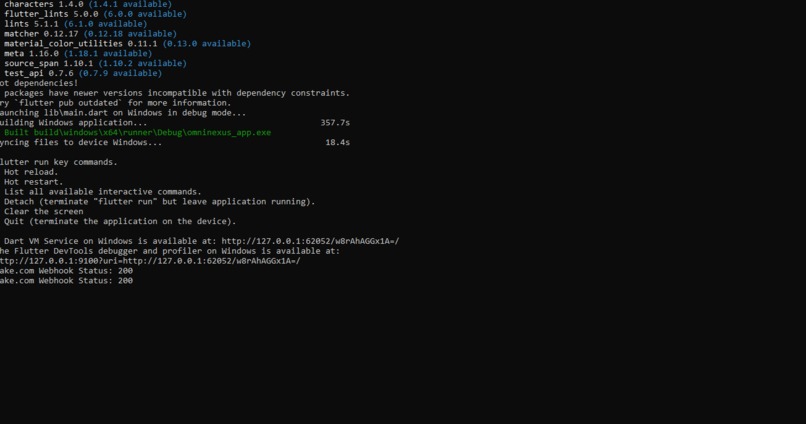
omninexus-agent-reasoning.png
-
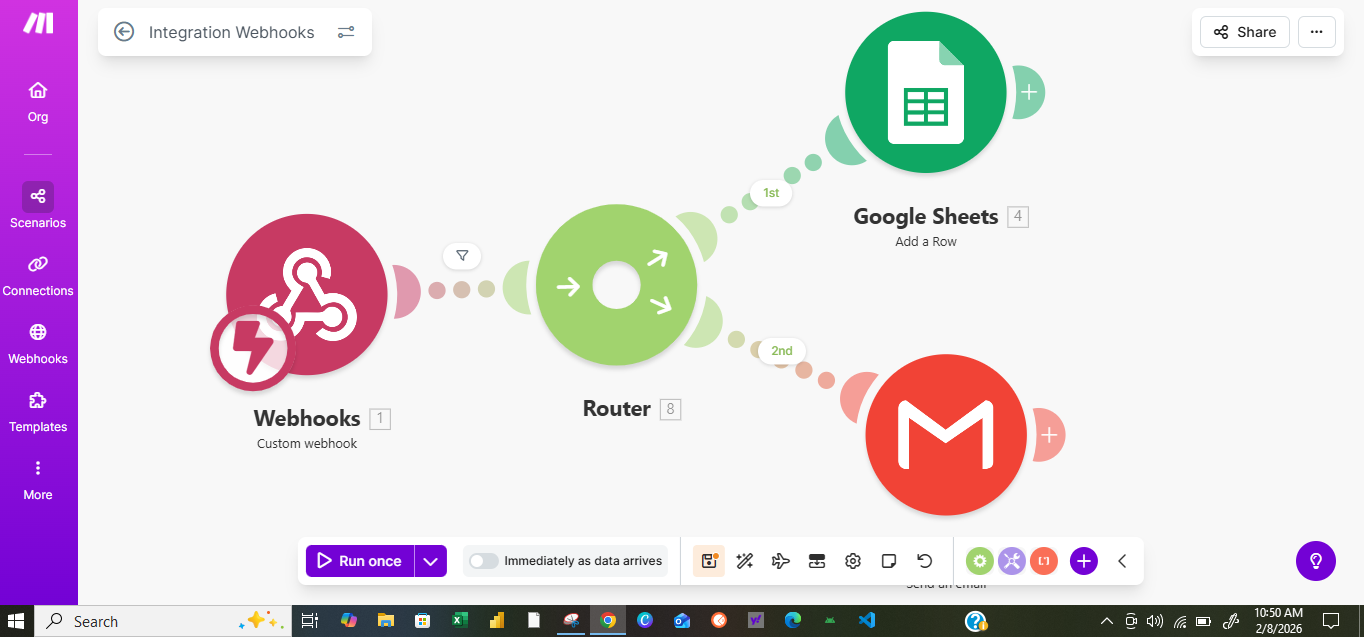
omninexus-webhook-execution.png
Inspiration
OmniNexus: The Multimodal Agentic Command Center
💡 Inspiration
The current landscape of Generative AI is often limited to "isolated intelligence"—models that can talk but cannot perceive or act in a unified way. We were inspired by the vision of a truly unified agent that bridges the gap between multimodal perception and real-world execution. OmniNexus was built to transform Gemini 3 from a chatbot into a proactive participant that can see through a lens, reason through a codebase, and act through integrated APIs.
🚀 What it does
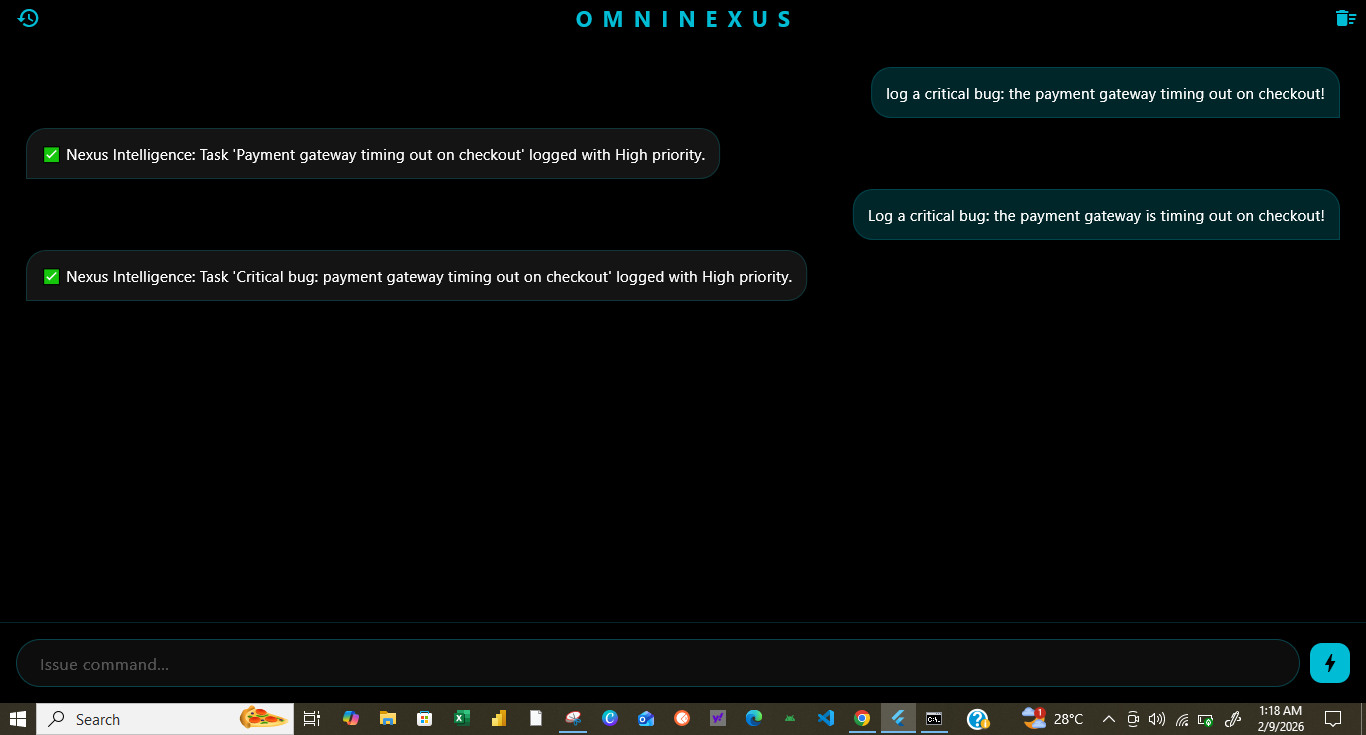
OmniNexus is a cross-platform command center that leverages Gemini 3's native multimodality to process real-time video, image, and voice data. It doesn't just return text; it generates actionable plans.
Vision-to-Action: Point the camera at a complex hardware setup or a buggy piece of code, and OmniNexus identifies the issue and drafts the fix.
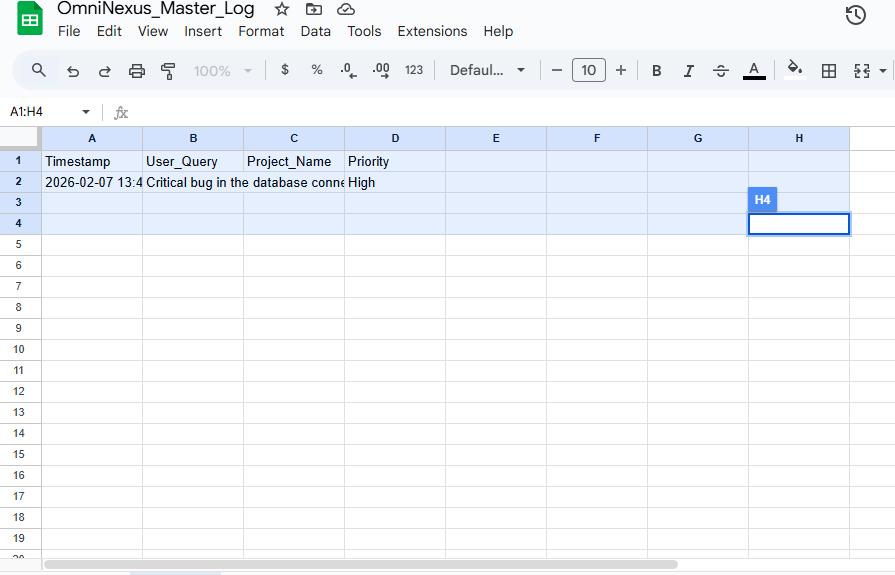
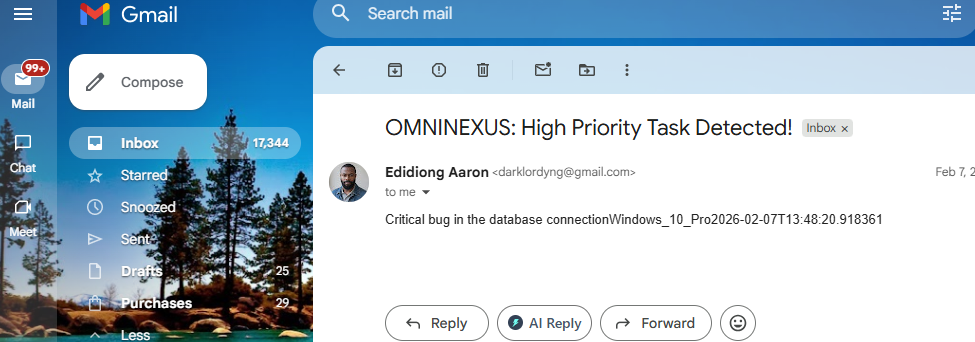
Agentic Workflows: By integrating with Make.com, the agent can autonomously trigger pull requests, send Slack updates, or update project tickets based on its multimodal reasoning.
🛠️ How we built it
As a Full-Stack and AI/ML project, OmniNexus utilizes a "Hybrid Intelligence" architecture:
Frontend: Developed with Flutter for a high-performance, responsive UI across mobile and desktop.
Brain: Gemini 3 (Pro/Flash) handles the heavy lifting, utilizing the 1M+ context window to maintain project-wide awareness.
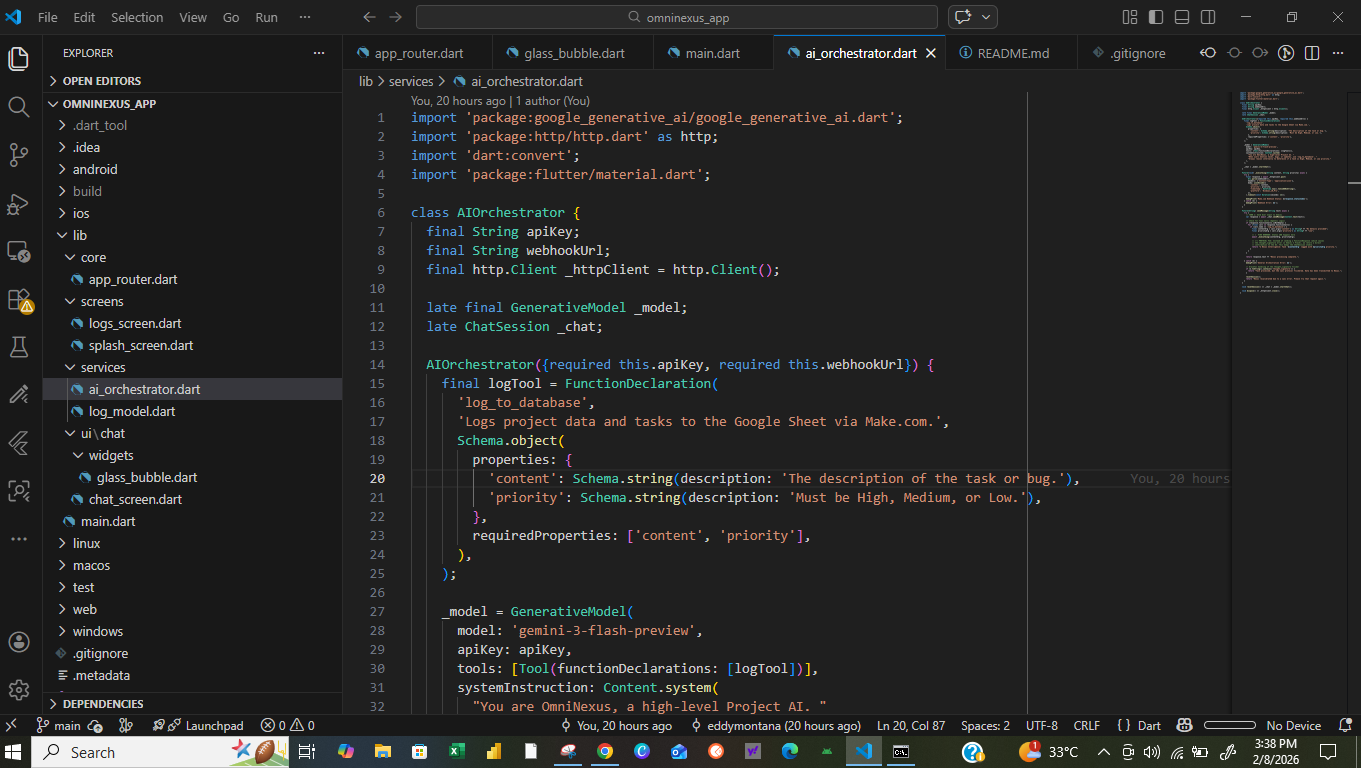
Orchestration: We implemented a custom Python-based middleware that translates Gemini's function calls into execution-ready payloads.
Automation: Make.com serves as the agent's "hands," connecting the AI logic to over 1,000+ third-party services.
Backend: Firebase manages real-time synchronization and secure user data handling.
🧠 Challenges we faced
One significant challenge was managing the Thinking Level vs. Latency. To solve this, we implemented a tiered reasoning system:
Low Latency: Gemini 3 Flash-Lite for immediate UI feedback.
High Reasoning: Gemini 3 Pro for complex "Thought Signatures" during multistep planning. Integrating these different models into a unified Flutter stream required sophisticated state management to ensure a smooth user experience without blocking the UI thread.
📈 What we learned
Building OmniNexus reinforced the power of Context Caching. We learned that by caching massive project documentations and codebase indices, we could drastically reduce token costs and latency while increasing the agent's "expert" precision.
🔮 What's next for OmniNexus
We plan to expand the agent's autonomy by integrating local Vector Databases (RAG) for private enterprise data and refining the Flutter interface to include AR overlays, allowing the AI to "draw" instructions directly over real-world objects in the camera view.

Log in or sign up for Devpost to join the conversation.