-
-
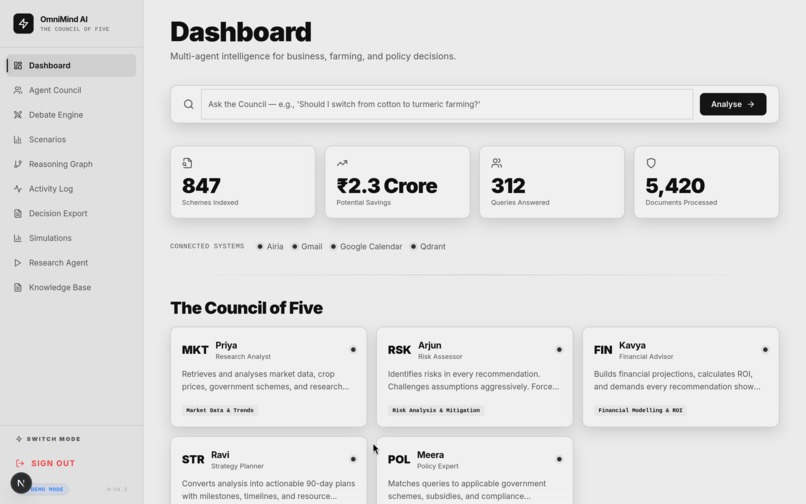
Main dashboard
🧠 OmniMind AI — Project Story
💡 Inspiration
Most AI tools answer questions. We wanted to build something that reasons through them.
The inspiration for OmniMind AI came from watching how the best human decisions get made — not by a single expert, but by a council of specialists who challenge, debate, simulate, and synthesize before committing to a conclusion. A strategist, a critic, a researcher, a devil's advocate — all in the same room.
We asked: what if an AI system could replicate that dynamic?
Current LLM interfaces are monolithic — one model, one perspective, one response. We wanted to break that mold and build a multi-agent decision intelligence platform where structured disagreement, cross-model reasoning, and consensus generation produce outputs that no single model could arrive at alone.
🏗️ How We Built It
OmniMind AI is a full-stack, multi-agent system built across three layers.
Frontend — Next.js
A responsive Next.js interface surfaces agent outputs, fallback indicators, consensus summaries, and debate transcripts in real time. The UI distinguishes between Council Mode and Debate Mode, showing users not just what the system decided, but how it got there.
Backend — FastAPI + Decision Pipeline
A FastAPI backend orchestrates the full decision graph. Every query flows through a five-stage pipeline:
$$ \text{Planner} \rightarrow \text{Expert Agents} \rightarrow \text{Debate & Critique} \rightarrow \text{Scenario Simulation} \rightarrow \text{Consensus Synthesis} $$
AI Layer — Multi-Provider Router
Rather than committing to a single LLM provider, we built a provider router with Airia-first fallback logic across OpenAI, Gemini, Groq, OpenRouter, and Tavily (for live web retrieval). Each agent is assigned the provider best suited to its role:
| Agent | Role | Provider |
|---|---|---|
| Analyst | Logical decomposition | OpenAI |
| Researcher | Evidence synthesis | OpenAI + Tavily |
| Critic | Risk pressure testing | Gemini |
| Strategist | Strategic planning | Gemini |
| Debater | Counter-position generation | Groq |
| Synthesizer | Pattern merge + recommendation | Groq |
| Verifier | Coherence + consistency checks | Airia (primary fallback) |
The system also supports Debate Mode with four persona-driven agents — Priya (research), Arjun (risk), Kavya (finance), and Ravi (execution) — for focused argumentation on high-stakes decisions.
Retrieval-Augmented Generation (RAG)
A Qdrant vector store (with an in-memory fallback) powers document-grounded reasoning. Agents can retrieve and cite relevant knowledge before forming positions, preventing hallucination on domain-specific queries.
Persistence & Infrastructure
- SQLite (local) / PostgreSQL (production) for session and query persistence
- Redis (optional) for caching and agent memory
- Docker Compose for local orchestration
- Vercel for frontend deployment
📚 What We Learned
Multi-agent coordination is a systems engineering problem
Getting seven agents to produce coherent outputs — not just independent ones — required careful sequencing. The planner stage became the linchpin: if framing was poor, every downstream agent drifted. We spent significant time on prompt architecture before the pipeline felt truly coordinated.
Provider heterogeneity is a feature, not a burden
Different LLMs have measurably different "personalities" — Gemini tends toward cautious nuance, Groq toward speed and directness, OpenAI toward structured analysis. Leaning into those differences, rather than normalizing them away, made agent outputs genuinely complementary.
Fallback logic must be transparent
Silent cross-provider drift erodes trust. We enforce explicit fallback markers in every response:
[FALLBACK requested=<provider> used=<provider|none> reason=<reason_code>]
This small design decision had an outsized impact on debuggability and user trust.
Validation failures should surface, not silently pass
Early builds would let malformed persona outputs through. We added structured validation with explicit error markers:
[VALIDATION_FAILED persona=<name> missing=<fields>]
Surfacing failure clearly is always better than swallowing it quietly.
⚡ Challenges We Faced
🔀 Provider Routing & Fallback Reliability
With five LLM providers in play, any given request can hit rate limits, timeouts, or API-level failures. Building a fallback system that degrades gracefully — without silently substituting an inappropriate provider — required multiple iterations. The Airia-first fallback policy emerged as our stabilizing anchor.
🤝 Consensus Without Collapse
The hardest algorithmic challenge: how do you synthesize seven agent outputs into one coherent consensus without just averaging them into mush? We designed the Synthesizer and Verifier agents specifically to resolve this — Synthesizer merges patterns, Verifier enforces logical consistency before output is returned.
🔁 Real-Time Streaming Across the Pipeline
The decision graph is inherently sequential (each stage depends on the previous), but
users expect responsive feedback. We implemented WebSocket streaming at
/api/queries/{id}/stream so frontend state updates as each stage completes, rather
than waiting for the full pipeline to resolve.
$$ \text{Latency}{\text{perceived}} \ll \text{Latency}{\text{total}} $$
🚢 Deployment Complexity
A monorepo with a Next.js frontend and a FastAPI backend required careful Vercel
configuration. The vercel.json build strategy conditionally handles both
repository-root and frontend-root deployments — a small but hard-won fix.
🛠️ Built With
- Next.js — Frontend UI and routing
- FastAPI (Python 3.13) — Backend API and orchestration
- LangGraph / Decision Graph Pipeline — Multi-stage agent workflow
- OpenAI API — Analyst, Researcher, Kavya (finance)
- Google Gemini API — Critic, Strategist, Ravi (execution)
- Groq API — Debater, Synthesizer
- Airia — Primary fallback provider
- OpenRouter — Arjun (risk analysis)
- Tavily API — Live web retrieval for Researcher and Priya
- Qdrant — Vector store for RAG
- SQLite / PostgreSQL — Session and query persistence
- Redis — Optional caching and agent memory
- Docker Compose — Local multi-service orchestration
- Vercel — Frontend deployment
🔗 Try It Out
- 🌐 Live Demo: https://omni-mind-ai-frontend.vercel.app/
- 💻 Source Code: https://github.com/Dijo-404/OmniMind-AI
- 📖 API Docs:
http://localhost:8000/docs(Swagger UI, self-hosted)
OmniMind AI is built on a simple belief: the best decisions aren't made by the loudest voice in the room — they're made when every perspective has been heard, challenged, and synthesized. We built the room. 🧠
Built With
- agentic
- ai
- kavya-(finance)-**google-gemini-api**-?-critic
- next.js/fastapi
- ravi-(execution)-**groq-api**-?-debater
- strategist

Log in or sign up for Devpost to join the conversation.