Omnimemory
Inspiration
We live roughly 30,000 days in a lifetime.
Yet when I look back, I realize how many meaningful moments have already slipped away—not because they weren’t important, but because human memory is fragile. I personally struggle to remember many details that matter deeply: which restaurant we visited, what food we ordered, or even what my wife was wearing when we first met (a detail she has reminded me of again and again 😅).
What struck me is that memory doesn’t fade evenly. We remember life as short flashes—often 5–10 second moments—rather than long continuous streams. These flashes already exist around us in the form of photos, videos, and audio recordings, but they are scattered, unsearchable, and disconnected.
At the same time, multimodal AI and embodied AI are rapidly becoming part of daily life: smart glasses, robots, toys, and devices with cameras and microphones. Our lives are being captured more than ever—but without a system to organize, understand, and retrieve those memories.
Omnimemory started from a simple question:
What if there were a private, intelligent system that could help me remember my life?
What it does
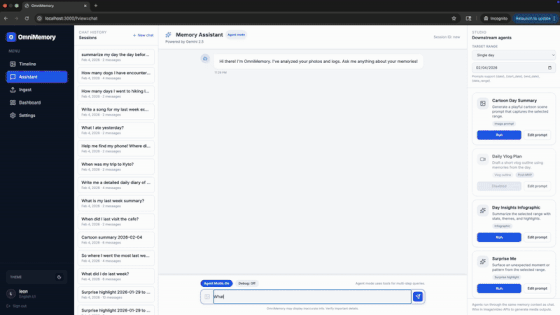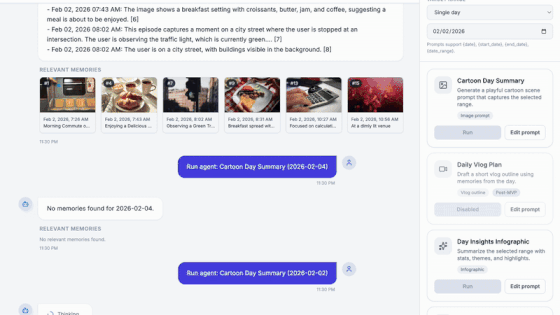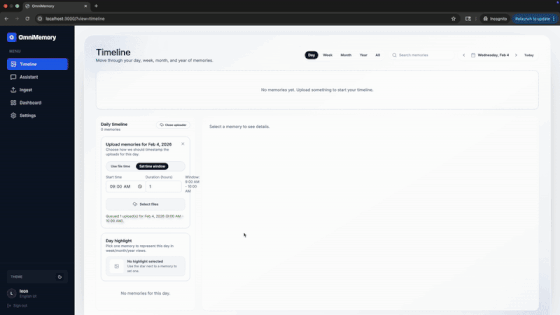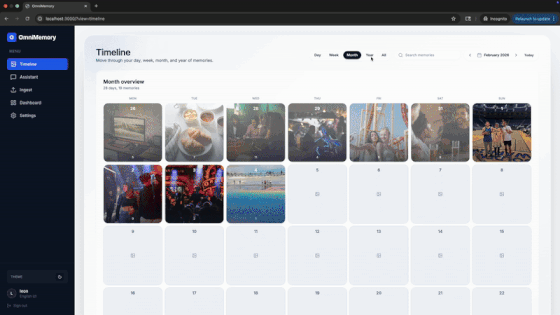
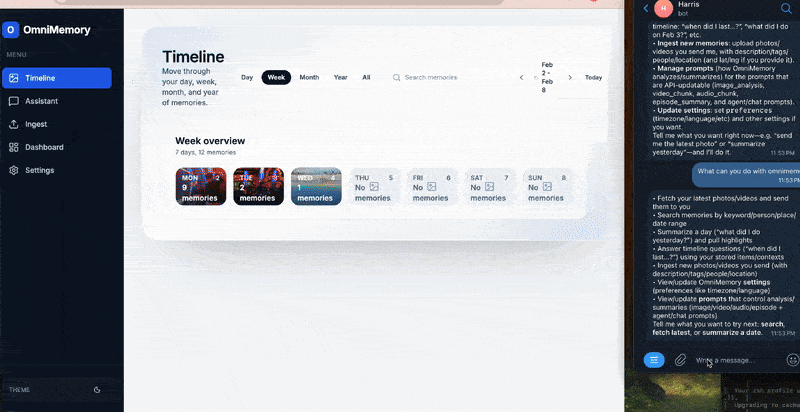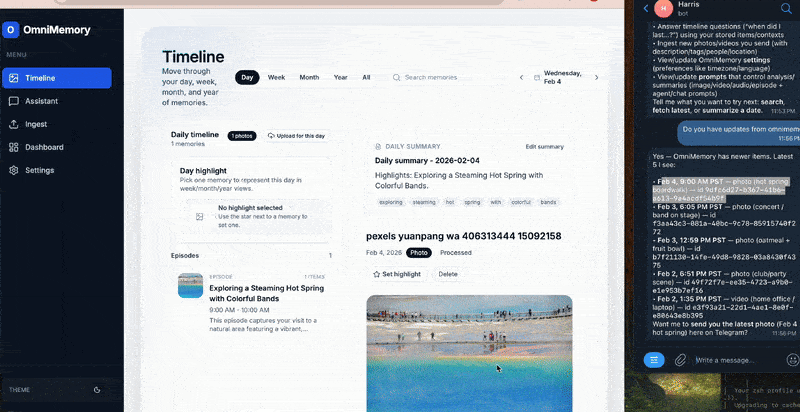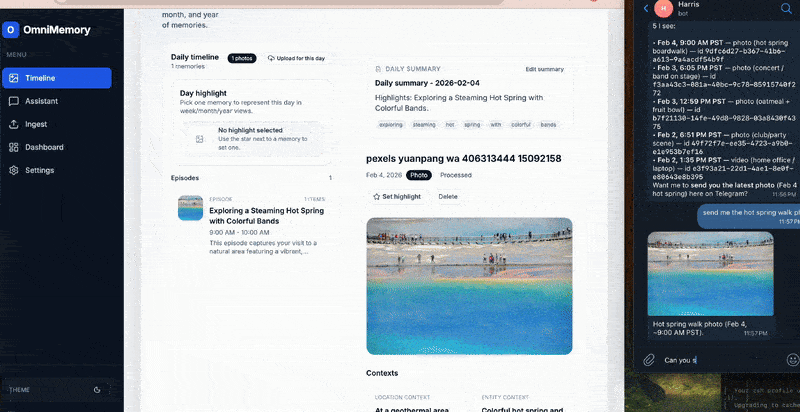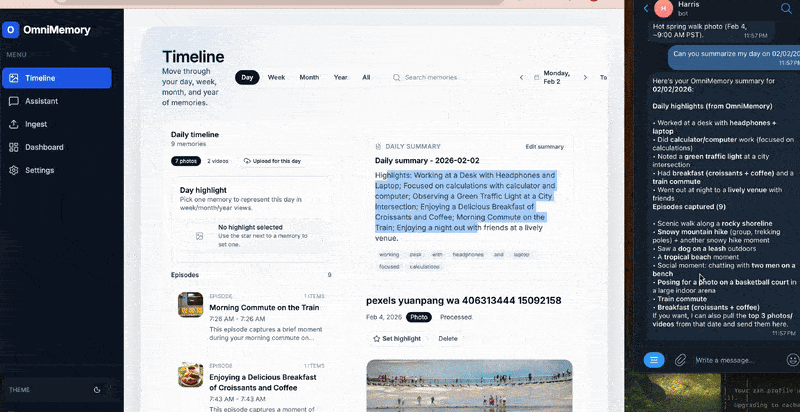
Omnimemory is a local-first personal memory management system that ingests photos, videos, and audio from daily life and turns them into searchable, meaningful memories.
It will automatically analyze and summarize all your memories. Instead of manually browsing folders or timelines, users can ask natural questions like:
- "Where did we eat last month?"
- "What did I do last Wednesday afternoon?"
- "Show me moments with my family during winter."
Omnimemory encourages users to casually capture more moments throughout their day. The more photos and records a user collects, the better Omnimemory can understand their life context and become more helpful over time. By centralizing these everyday memories, Omnimemory acts as a single system that helps users manage their life history, almost like gaining a personal memory superpower.
For example, if a user regularly takes photos of their refrigerator or dining receipts, Omnimemory can answer practical questions such as:
- “What do I currently have in the fridge?” while grocery shopping
- “How much did I spend on dining this month?”
The system is also designed to integrate easily with embodied AI devices such as smart glasses, robots, or other camera-equipped agents. As long as these devices capture photos or videos, Omnimemory can ingest and organize the data, making it a natural hub for future memory-driven AI experiences.
The system indexes multimodal memories, enriches them with semantic understanding using vision-language models, and retrieves relevant moments using a Retrieval-Augmented Generation (RAG) pipeline powered by an intelligent chat agent.
Privacy is a first-class principle: Omnimemory runs locally by default, keeping personal memories under the user’s control.
How I Built It
Omnimemory is a production-level, full-stack system, not a prototype or demo. At its core, it is designed as a memory operating system: ingesting raw life data, transforming it into structured memories, and enabling intelligent retrieval through an agent-driven interface.
AI Core
The Gemini multimodal models act as the central reasoning engine of Omnimemory. They power nearly every stage of the memory lifecycle:
Multimodal understanding
Photos, audio, and videos are analyzed to extract semantic meaning, context, and key moments.Automatic transcription
Audio and video memories are transcribed into text, enabling search, indexing, and reasoning over spoken content.Memory summarization
Raw data is condensed into short, human-readable memory summaries that reflect how people naturally remember events.Voice-based memory editing
Users can rewrite or refine memory summaries using their own voice via speech-to-text, keeping memories personal and natural.Chat agent reasoning loop
Gemini models drive an agent-based chat loop that handles intent detection, temporal reasoning, memory filtering, RAG orchestration, and answer synthesis.Embedding generation
All memory contents—raw data, transcripts, and summaries—are embedded into a unified vector space for efficient retrieval.
System Architecture
Beyond the AI layer, Omnimemory includes the full infrastructure required for a real-world application:
- Memory ingestion pipelines for photos, audio, and video
- Indexed storage combining structured databases and vector search
- Custom RAG pipeline tuned for personal memory retrieval rather than generic QA
- Authentication and user management, configurable for local development
- Frontend UI for browsing, searching, and chatting with memories
- Dockerized services enabling local-first execution and easy cloud deployment
It includes:
- Backend: FastAPI, Celery, SQLAlchemy (asyncpg), Pydantic, Python 3.11+
- AI: Gemini (via google-genai), Google ADK (agent framework)
- Storage: Postgres, Redis, Qdrant, S3 (RustFS) or Supabase
- Frontend: React 19, Vite, Framer Motion, Recharts, Lucide React
- Monitoring: Flower, Prometheus, Grafana
- Media: FFmpeg, Pillow (HEIF support)
- Hardware: ESP32 firmware (PlatformIO)
- Integrations: OpenClaw (agent memory sync)
- Auth: Authentik OIDC (optional)
- Testing: Pytest, Playwright
Challenges we ran into
- Similarity vs. relevance: vector search alone often returns the wrong memories
- Temporal reasoning: natural language time references are hard to model correctly
- Incorrect answers despite correct retrieval: reasoning matters as much as retrieval
- Multilingual support: rule-based heuristics quickly become unmaintainable
- System complexity: ingestion, indexing, retrieval, and chat orchestration must work together seamlessly
At a high level, memory answering can be described as:
$$ \text{Answer} = f(\text{User Query}, \text{Relevant Memories}) $$
Initially, the system relied on standard RAG with vector similarity search. However, real-world usage quickly exposed limitations. Vector similarity often retrieves memories that are similar, but not necessarily relevant. Temporal expressions like “last Wednesday” or “two weeks ago” were especially problematic.
To solve this, I moved from a simple RAG setup to a custom chat agent, built using Google ADK. The agent explicitly handles:
- Intent identification
- Time normalization
- Memory filtering
- RAG orchestration
- Answer synthesis
This agent-based approach proved far more robust, scalable, and easier to extend across different languages and use cases.
Accomplishments that we're proud of
- Built a fully working end-to-end MVP
- Designed and deployed a custom chat agent that outperforms naïve RAG
- Achieved a local-first architecture with strong privacy guarantees
- Integrated multimodal understanding via vision-language models
- Dockerized the entire system for reproducibility and cloud readiness
One notable innovation is the integration with OpenClaw. By exposing Omnimemory’s backend endpoints and chat history to OpenClaw and enabling the right skills, users can manage memories via Telegram, WhatsApp, and other agent interfaces.
Both systems run locally:
- Omnimemory gives OpenClaw access to personal life memories
- OpenClaw contributes structured, high-quality memories back into Omnimemory
What we learned
- Memory systems require retrieval + reasoning, not storage alone
- RAG without agents breaks down in real-world scenarios
- Temporal understanding is a core problem, not an edge case
- AI coding tools dramatically reduce the barrier to building complex systems
- Local-first AI systems are viable even for advanced multimodal workloads
I also learned that building the “unexciting” parts—authentication, migrations, UI—are just as important (and surprisingly enjoyable) as the AI itself.
What's next for Omnimemory
Next steps include:
- Improving the memory layer using open-source tools like mem0 and PageIndex
- Enhancing long-term memory consolidation and retrieval accuracy
- Expanding embodied-AI integrations (glasses, wearables, cameras)
- Deploying to cloud platforms like GCP for optional paid offerings
- Continuing to refine privacy-preserving, local-first workflows
Omnimemory is built around a simple belief:
Our lives deserve to be remembered—before those memories quietly fade.
Built With
- celery
- docker
- fastapi
- platformio
- postgresql
- python
- qdrant
- react
- redis
- rustfs
- typescript
- vite

Log in or sign up for Devpost to join the conversation.