I wanted to build something that feels like real production engineering, not just a demo endpoint. The goal was to design a service that stays stable during failures, scales under load, and gives operators clear visibility during incidents.
What it does
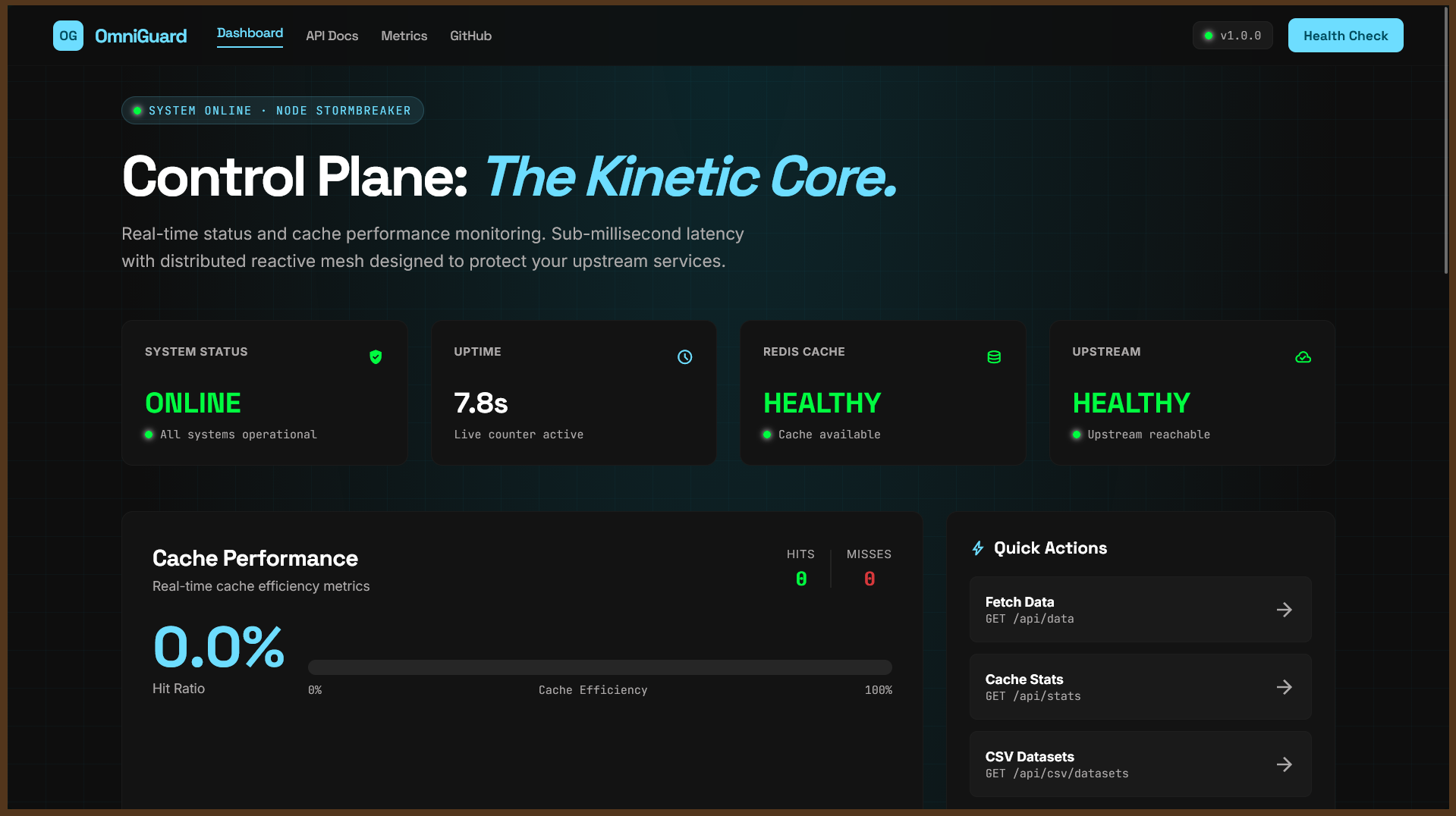
OmniGuard provides:
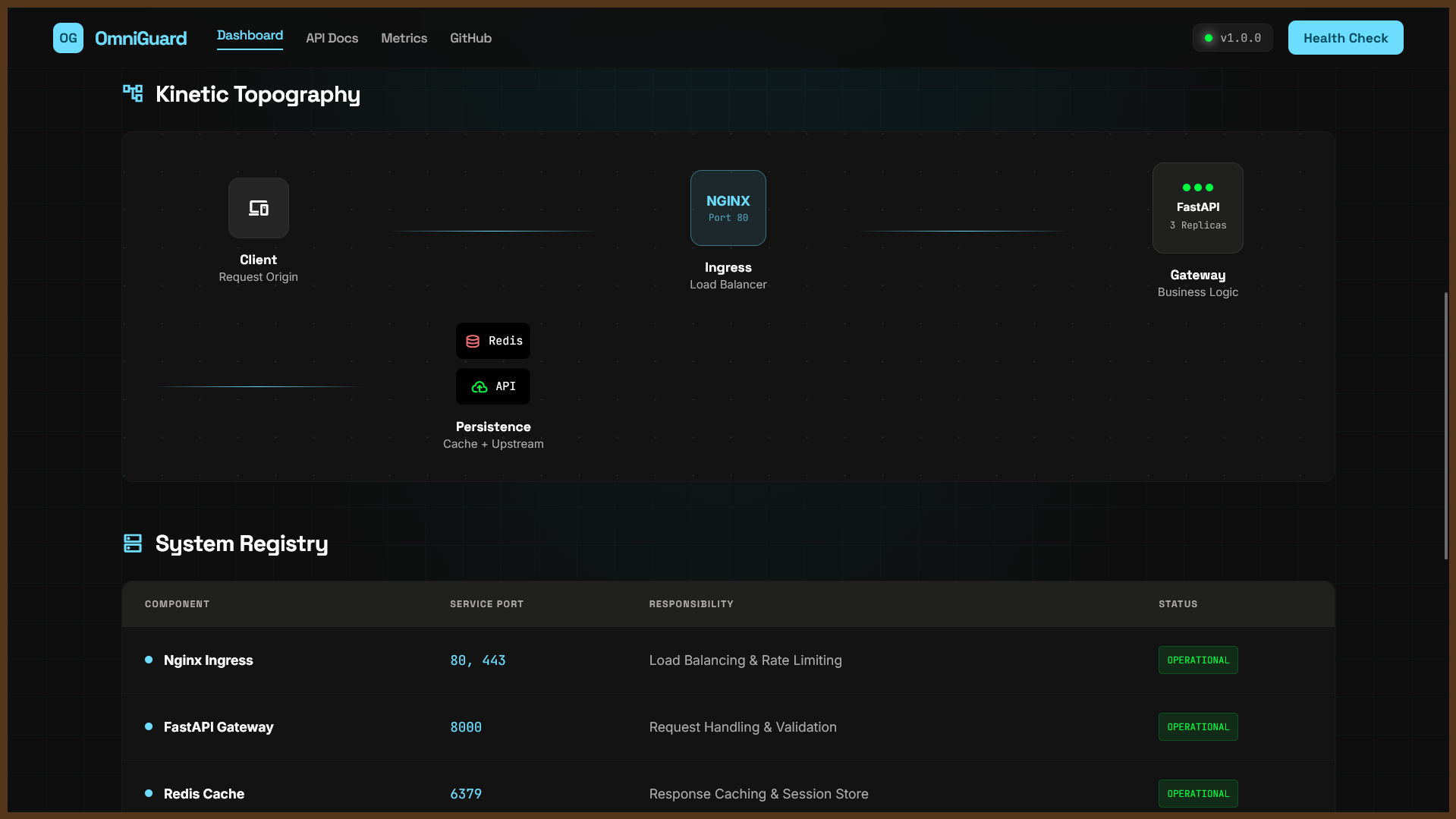
Health and metrics endpoints for observability User, URL, and event APIs Bulk CSV ingestion for seeded data URL short-code redirect support Cache-aware API behavior and compatibility endpoints Monitoring dashboards and alert routing
How I built it
I built the app in Python using Flask, then added a full operations stack around it:
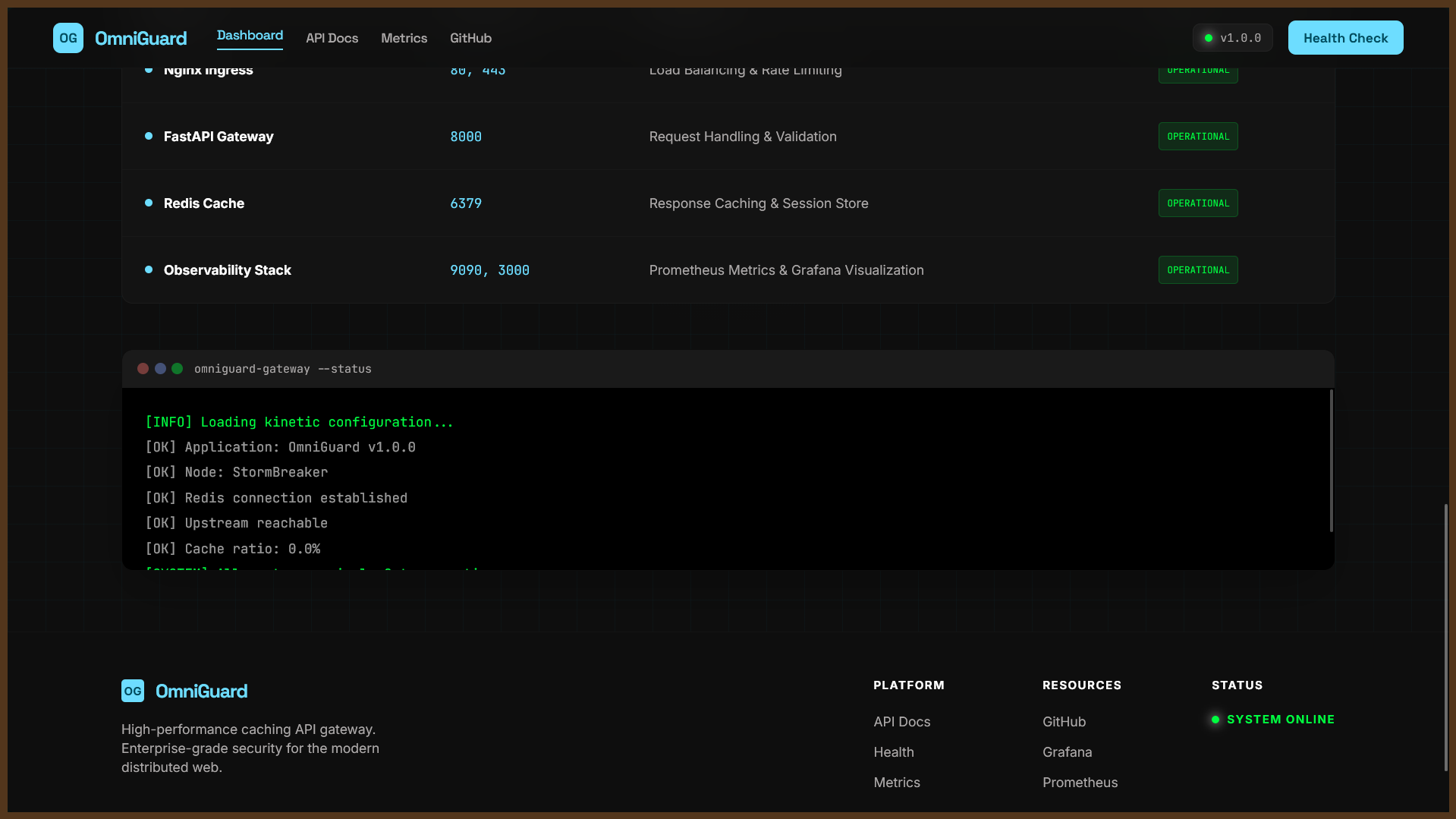
API layer with structured responses and error handling Data workflows with CSV-backed entities and API-driven CRUD Nginx for ingress/load distribution Redis-backed caching patterns Prometheus + Grafana + Alertmanager for monitoring/alerts k6 load testing for scalability evidence Pytest + GitHub Actions for automated quality checks
Challenges I ran into
Balancing framework migration with backward-compatible API behavior Aligning endpoint contracts to strict external grader expectations Handling hidden edge cases in bulk import and entity workflows Keeping observability and resilience artifacts consistent with implementation
What I learned
I learned how important contract-driven development is, especially when tests are external and strict. I also got hands-on experience with operational reliability: failure modes, runbooks, load testing, and alert validation.
What I are proud of
I am proud that OmniGuard is not only feature-complete but also operationally grounded, with health checks, dashboards, alerting, and documented recovery procedures.

Log in or sign up for Devpost to join the conversation.