-
-

Omni, never lose a thought again.
-
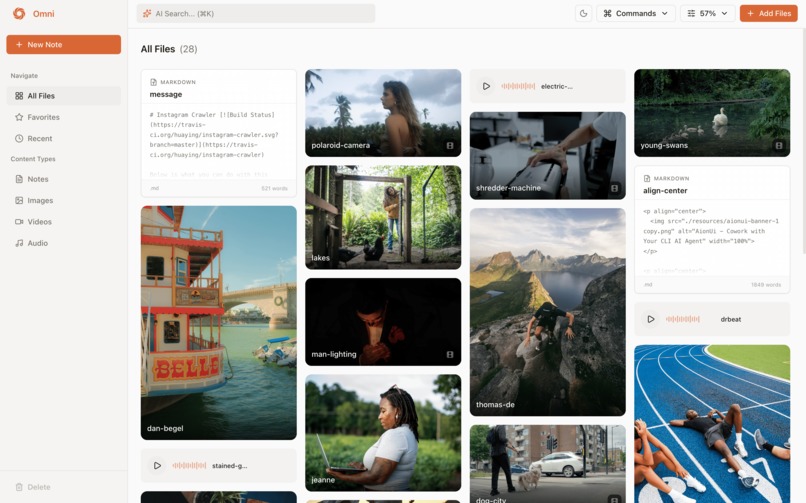
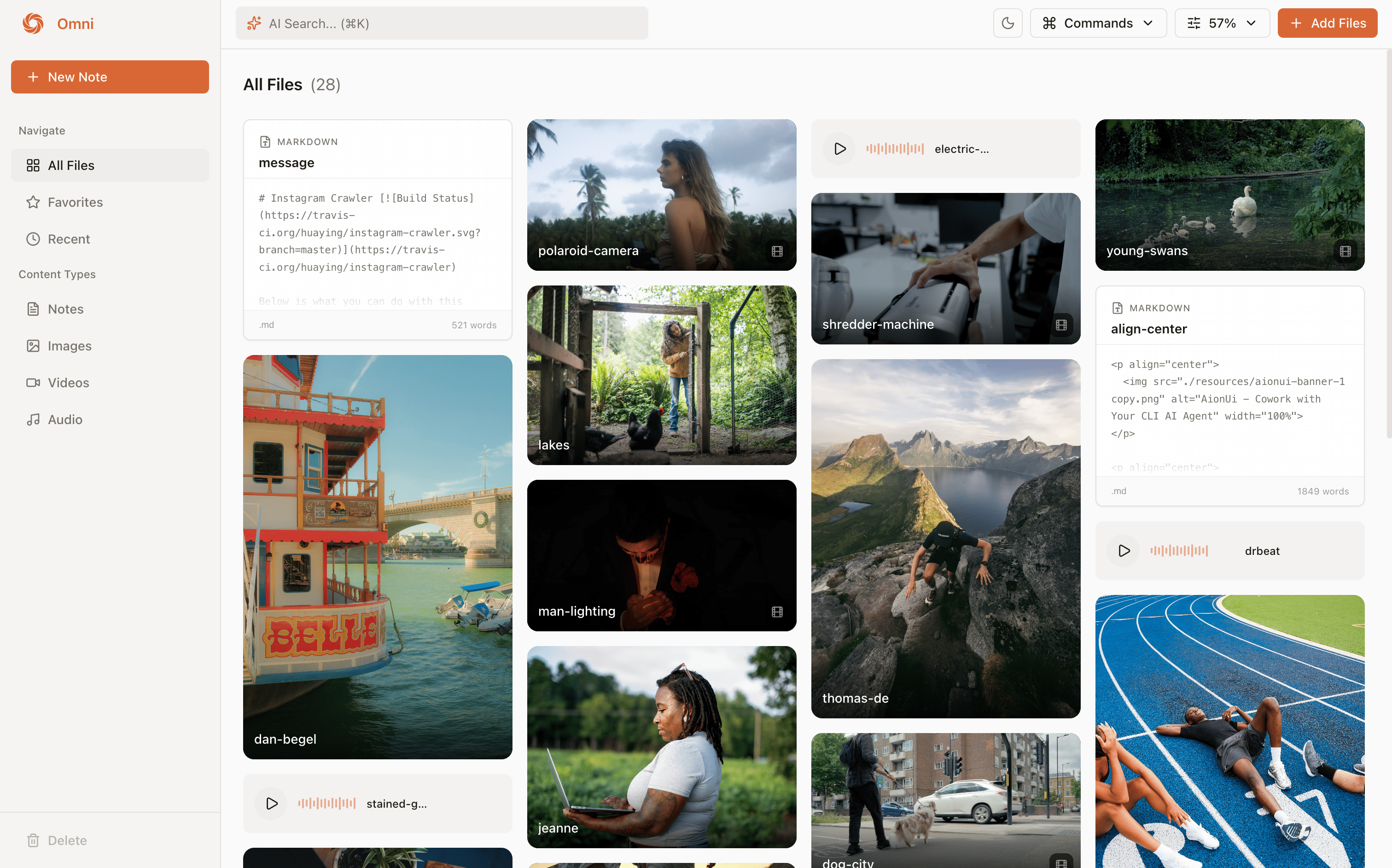
Omni in light mode
-
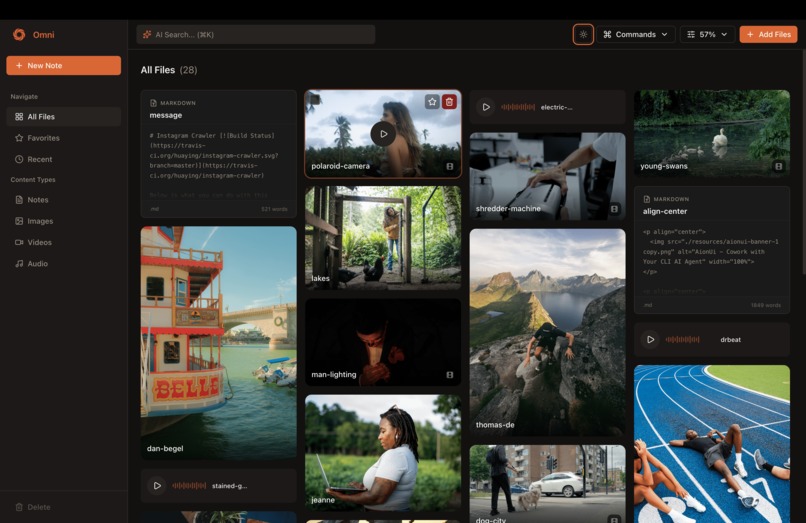
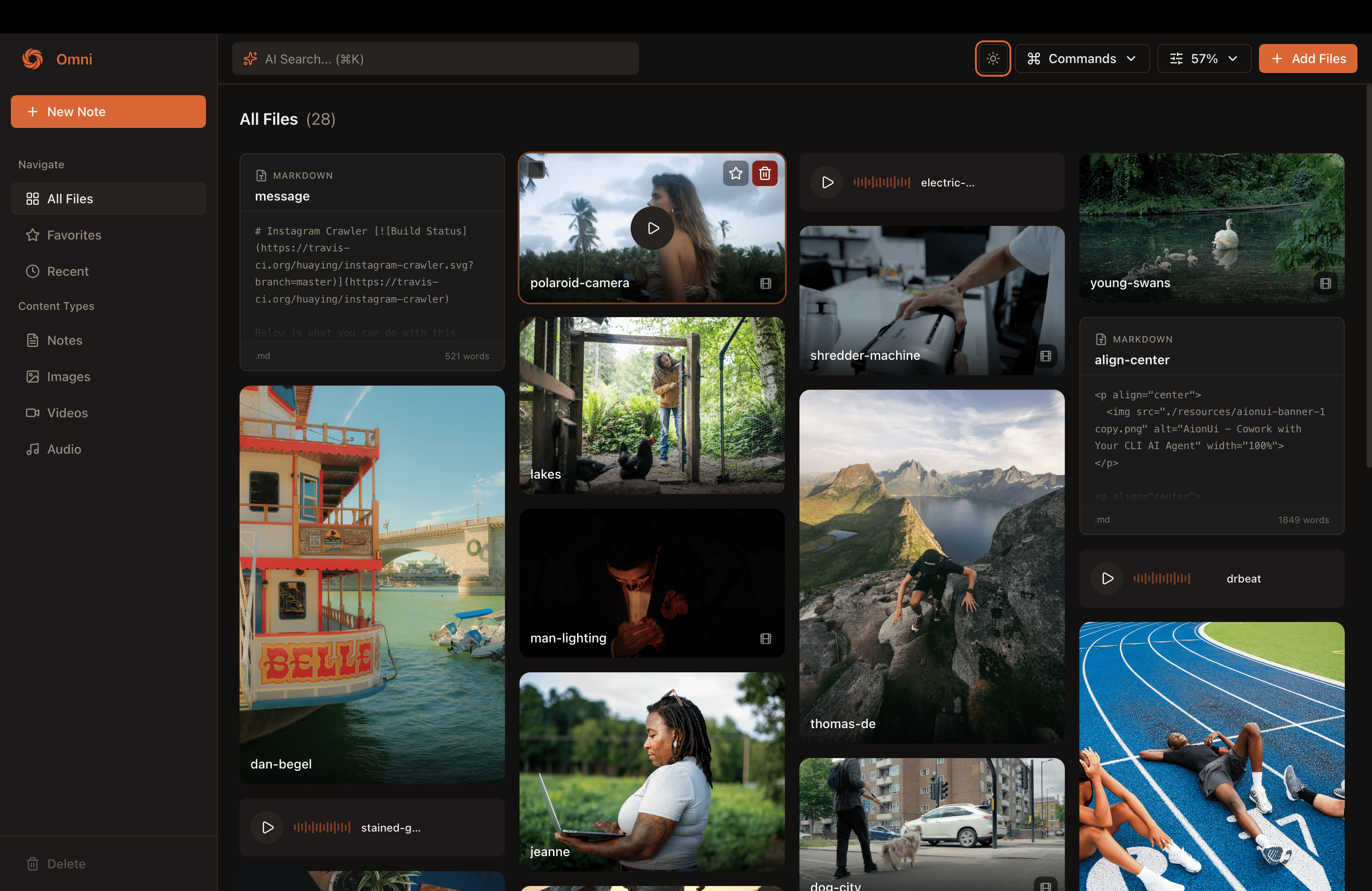
Omni in dark mode
-
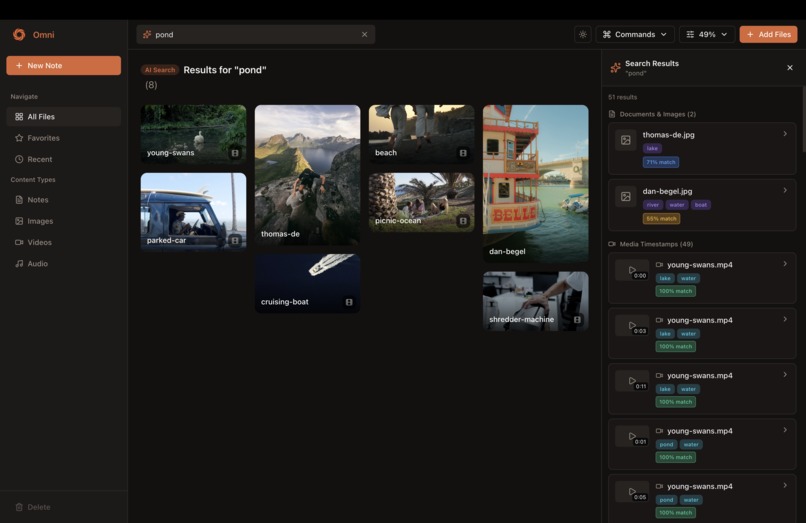
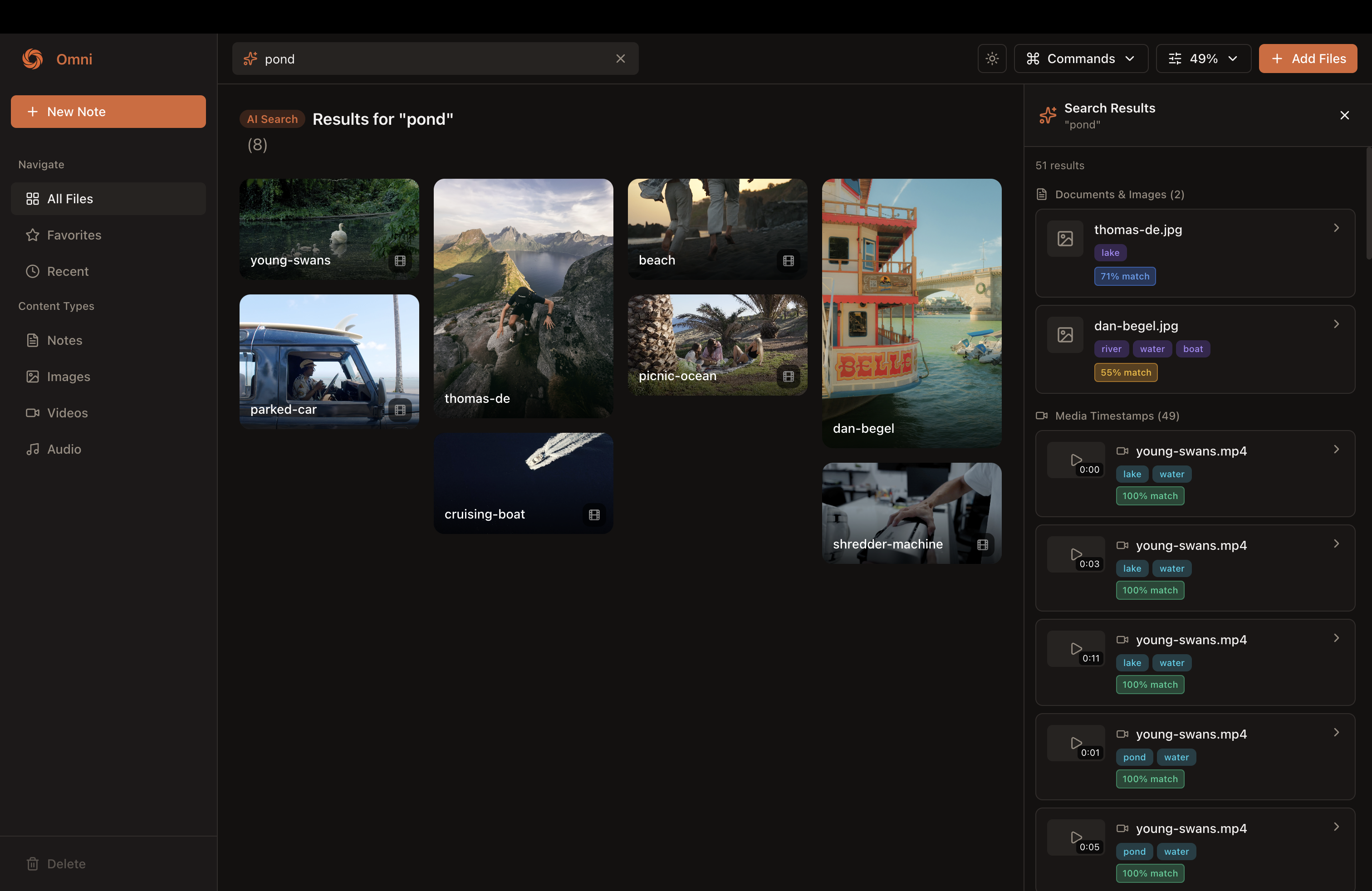
Omni's search engine in action
-
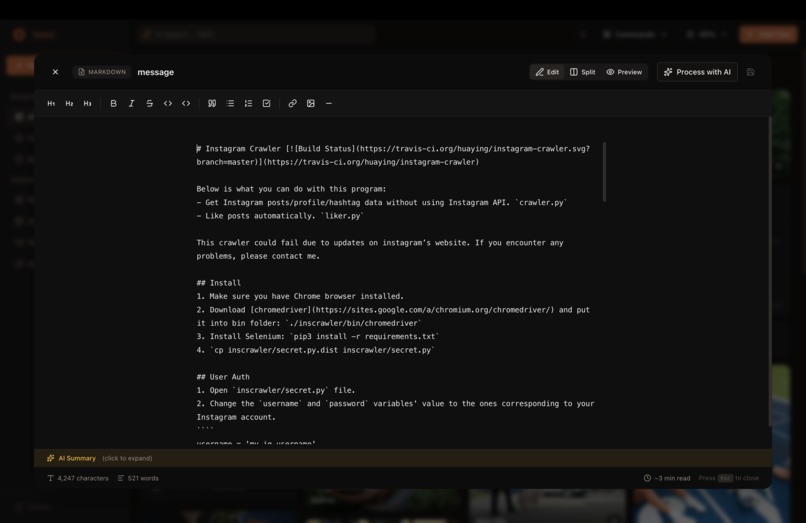
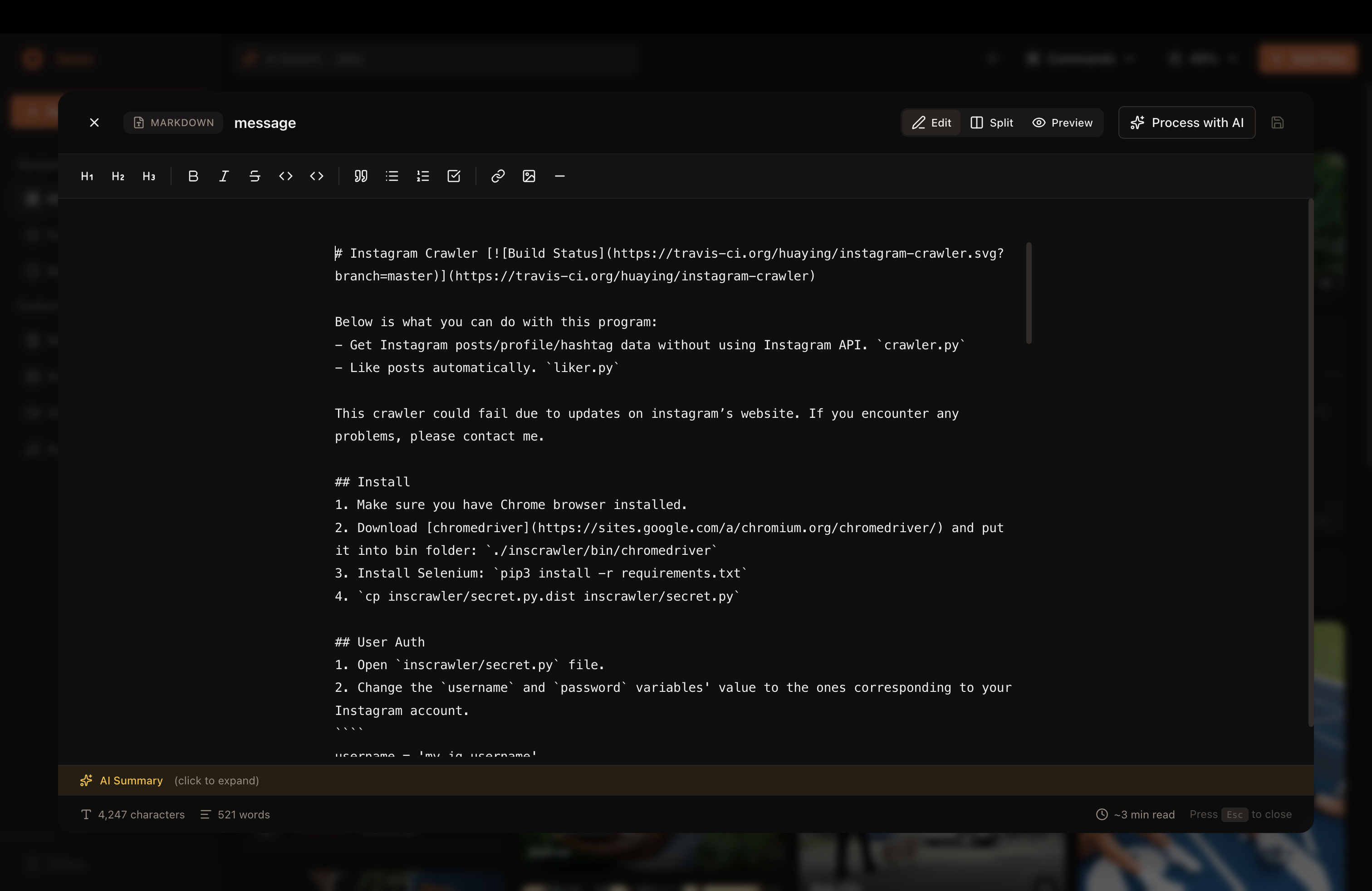
Built in note taker in Omni

Inspiration
We've all been there: waiting for OneNote to sync, watching Notion spin, or desperately trying to remember if that important information was in a Google Doc, a screenshot, or buried in a video recording. Cloud-based note apps are slow, require constant internet, and worst of all, they can't search across different media types.
As students and developers, we constantly save things; lecture recordings, code snippets, research papers, whiteboard photos, voice memos, but when we need to find something, we're stuck doing manual searches through folders or hoping we remember the exact filename.
We wanted a notes app that's as fast as our thoughts. One that understands all our content and lets us find anything instantly using natural language without waiting for cloud syncs or paying monthly subscriptions. Your data, your machine, your speed.
What it does
Omni is a lightning-fast personal knowledge base that understands everything you save. It lets you:
- Search everything with natural language: Ask "find my notes about machine learning" and it finds relevant documents, images of diagrams, video lectures, and audio recordings
- Analyze videos frame-by-frame: Automatically extracts keywords from video content with timestamps, so you can jump to exactly what you're looking for
- Transcribe and index audio: Voice memos and recordings become searchable
- Understand images: Screenshots, photos, and diagrams are analyzed and indexed
- Write in a beautiful Markdown editor: Built-in editor with live preview, formatting toolbar, and AI-powered summaries
- Stay local and private: Everything runs on your machine. No cloud dependency, no sync delays, no subscription fees
How we built it
Frontend: React 19 + Vite + Electron for a native desktop experience, styled with Tailwind CSS
Backend: Express.js + TypeScript with SQLite (better-sqlite3) for instant local storage
Semantic Search: We use Xenova/all-MiniLM-L6-v2 a sentence transformer that runs entirely locally via transformers.js. It generates 384-dimensional embeddings that capture the meaning of content, enabling search by concept rather than exact keywords.
Media Processing:
- Videos:
semantic-videolibrary + FFmpeg for frame extraction and analysis - Audio: Transcription and keyword extraction with openai whisper-1
- Images: AI-powered description and tagging
- Documents: Keyword extraction and summarization
AI Analysis: OpenRouter API with Gemini 2.0 Flash for content understanding
The architecture is designed for speed, SQLite gives us millisecond queries, local embeddings mean no API latency for search, and Electron provides a snappy native experience.
Challenges we ran into
Version Control Disaster: Midway through the hackathon, we ran into major Git conflicts that corrupted our repository structure. We had to migrate to a completely new repo, carefully cherry-picking commits and rebuilding our branch structure. Lost a few hours but learned a lot about Git internals.
Embedding Performance: Initially, generating embeddings was slow and blocked the UI. We optimized by batching operations, caching embeddings in SQLite as binary blobs, and ensuring the embedding model only loads once.
Video Processing: FFmpeg integration was tricky across different operating systems. We had to handle path differences between Windows and Unix systems, and manage async frame extraction without freezing the app.
Masonry Layout: Getting the file grid to look good with mixed media (tall documents, square images, wide videos) required custom sizing logic based on file type and content length.
Accomplishments that we're proud of
- True semantic search: Searching "cooking" finds files tagged with "recipes," "kitchen," "ingredients" even without exact matches
- Sub-100ms search times: Local SQLite + embeddings = instant results
- Video timestamp search: Find the exact moment in a video where something was discussed
- Beautiful, responsive UI: Drag-to-select multiple files, hover checkboxes, smooth animations
- Zero cloud dependency: Privacy-first, works offline, no subscriptions, only you and your API keys
- Recovered from repo disaster: Didn't let Git issues stop us!
What we learned
- Local-first is powerful: The speed difference between local SQLite and cloud APIs is night and day
- Embeddings are magic: Semantic similarity search feels like the future of information retrieval
- Git hygiene matters: We'll never skip proper branching strategies again
- FFmpeg is everywhere: Video/audio processing almost always needs it, document it clearly
- Ship incrementally: Building features end-to-end (backend → frontend → UI polish) kept us moving forward
What's next for Omni
- Folder watching: Automatically index files when you save them to watched directories
- Browser extension: Clip web content directly into Omni
- Sync (optional): End-to-end encrypted sync for those who want it, staying true to privacy-first
- Plugin system: Let users add custom analyzers and integrations
- Mobile companion: Quick capture app that syncs to your desktop Omni
- Better AI models: Support for local LLMs (Ollama) for fully offline AI analysis
Built With
- electron
- express.js
- ffmpeg
- gemini
- node.js
- openai
- openrouter
- react
- sqlite
- tailwindcss
- transformer.js
- typescript







Log in or sign up for Devpost to join the conversation.