-
-
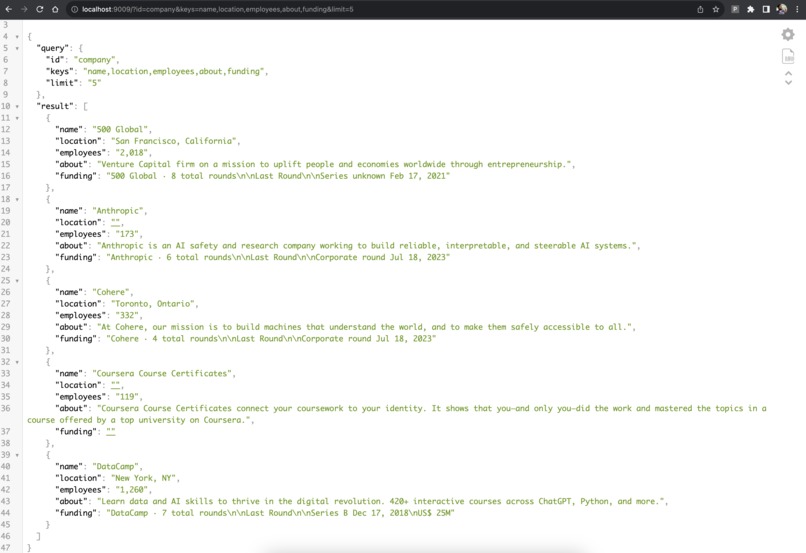
Results for a sample query
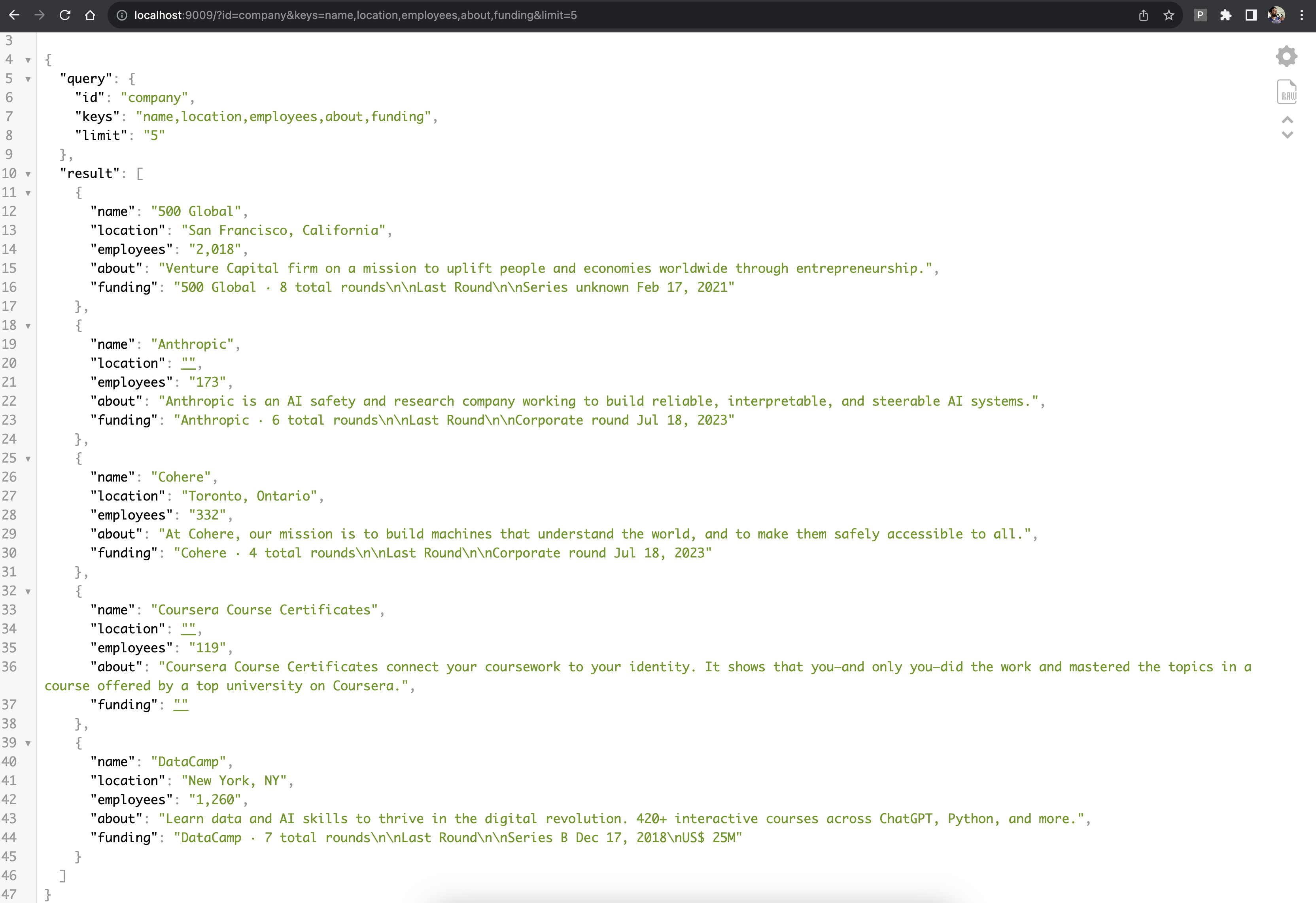
Inspiration
Whenever I am doing research on a specific topic, I open 20-30 pages and go through them looking for specific things that I want to find. I always end up creating a google sheet to keep track of things.
What it does
It takes in raw pages as input and provides you a way to extract entities out of the raw form text and return it in a JSON format specified by you.
How we built it
- Used Google Cloud Functions for the serverless infra and API endpoint
- Built a chrome extension to download raw text from a webpage
- Used claude2 to convert raw text into JSON format
Challenges we ran into
- I started with using saved html files but that was too much content
- I looked into embeddings to solve the problem of auto categorization, but we are not there yet
- Ran into the challenge of getting just a JSON as output
Accomplishments that we're proud of
- Building all these things within the short time period
- Keeping the tech stack slim
- Keeping the user interactions to as minimal as possible
What we learned
- How to enforce model to return JSON outputs
- How to use embeddings
What's next for Omni - Text to API
- Auto capture pages and put them in cloud storage
- Background tasks to process data async
- Semantic search using ScaNN over embeddings
Built With
- chrome
- claude2
- google-cloud
- node.js

Log in or sign up for Devpost to join the conversation.