-
-
-

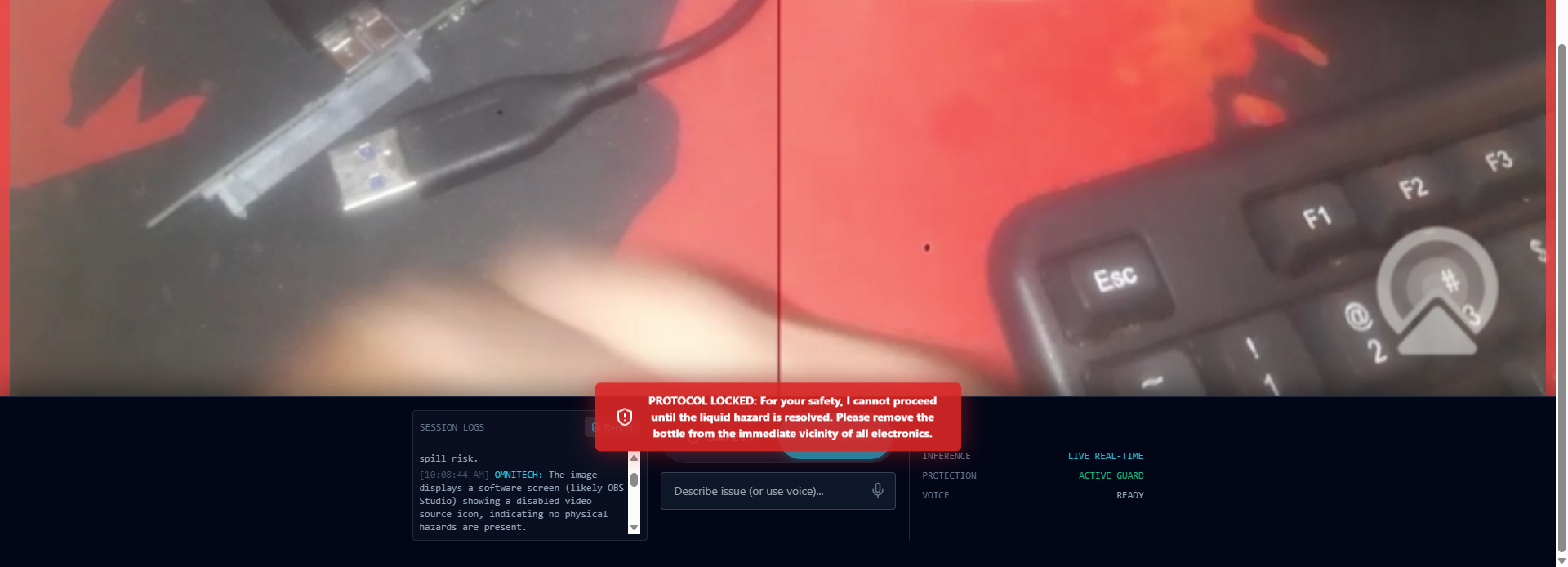
OmniTech detects liquid near electronics and immediately flags a critical safety risk before any repair guidance is given.
-
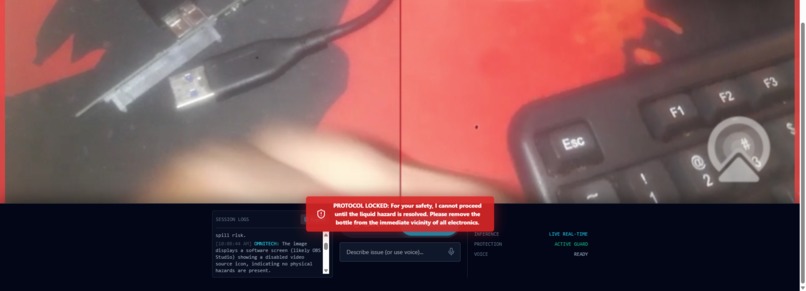
When a hazard is present, OmniTech locks the system and refuses further actions until the environment is made safe.
-

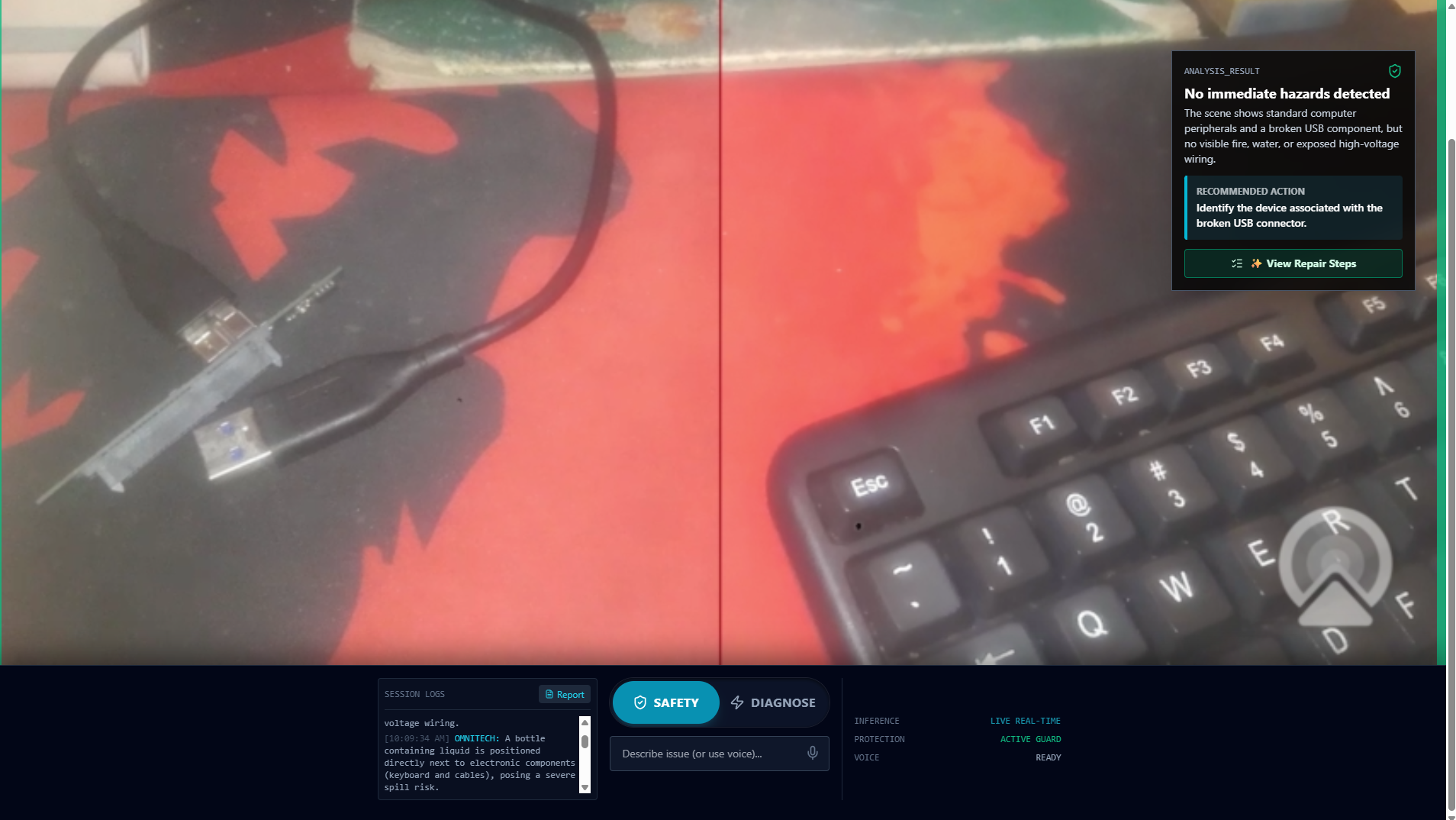
After the hazard is removed, OmniTech confirms the area is safe and allows diagnostics to continue.
-
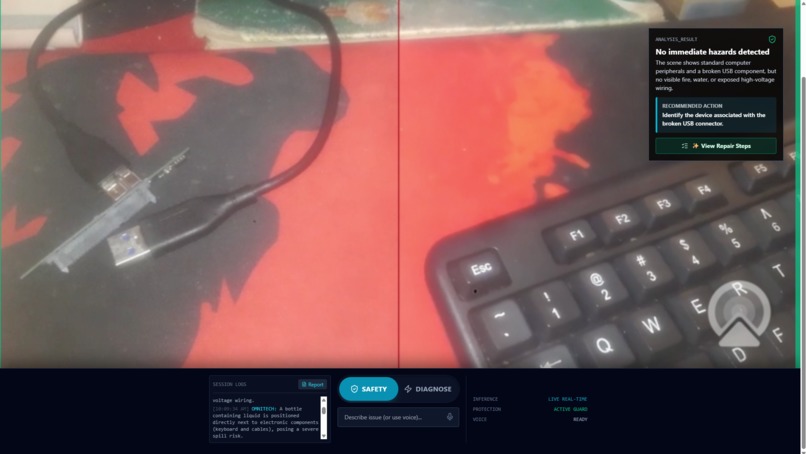
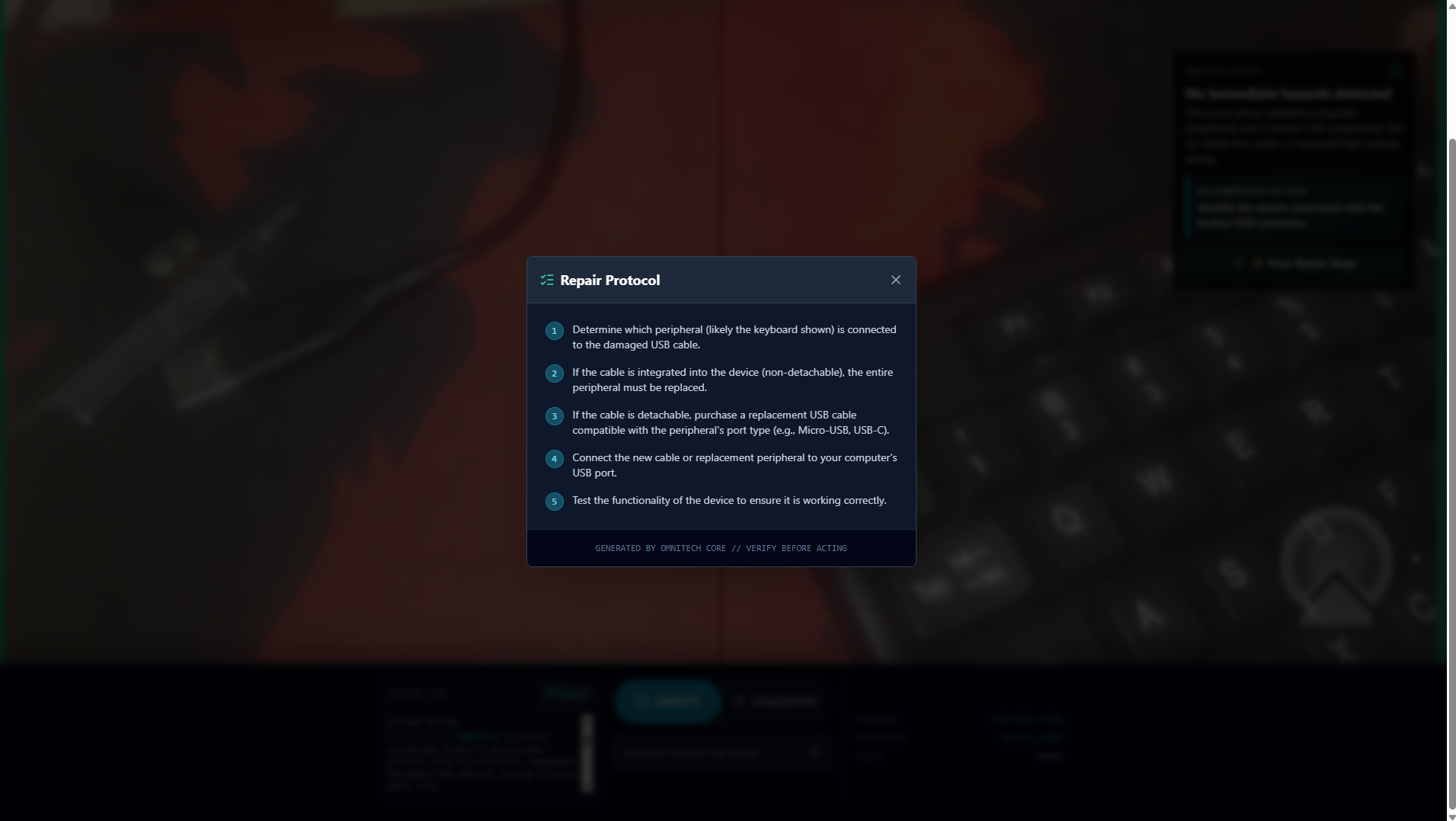
Structured analysis output with clear reasoning and a recommended action, designed for fast field decisions.
-
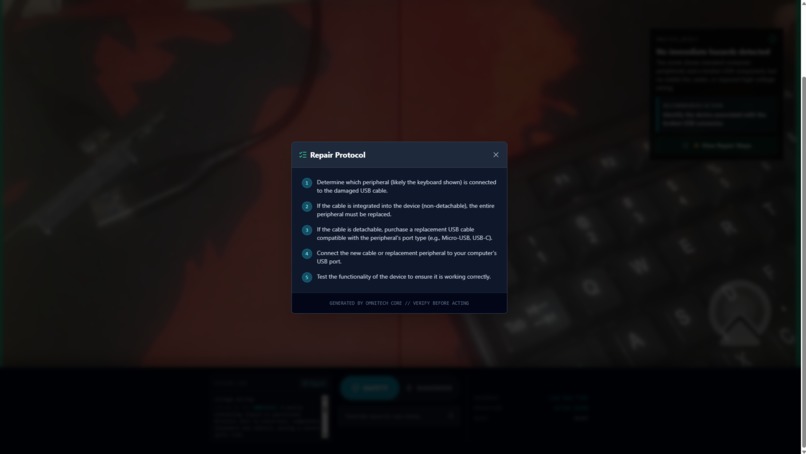
Step-by-step repair guidance is unlocked only after OmniTech confirms the situation is SAFE.
-
Session logs and incident reporting show how OmniTech records safety events for later review and accountability.


Inspiration
I know it sounds a bit cliché, but my biggest inspiration has always been J.A.R.V.I.S. from Iron Man. Not just the cool voice or the holograms but the specific way he protected Tony Stark. He didn't just blindly follow orders; he would say things like, "Sir, power levels are critical," or "That flight path is unsafe." He had agency.
I looked at current AR tools for technicians, and they were all passive. They overlay instructions, but they don't care if you're standing in a puddle of water while touching a live wire. I wanted to build something that bridges that gap, an AI that doesn't just see the world, but reasons about safety and actively protects the user.
What it does
OmniTech is a web-based autonomous field safety agent that uses Google Gemini’s multimodal reasoning to perceive and reason about physical environments in real time. It acts as a safety interlock for technicians rather than a passive assistant.
See: Captures live video frames of machinery or environments.
Reason: Detects hazards (corrosion, loose wires, water leaks) using multimodal reasoning.
Protect: If a hazard is detected, the UI locks down. The "Diagnose" button is physically disabled, and the AI issues a stop command until the user confirms the scene is safe.
Unlike traditional assistants, OmniTech can override user intent. If the situation is dangerous or unclear, it will explicitly refuse to give repair instructions.
How I built it
I built OmniTech as a high-performance web application so it could run on any device like a phone, laptop or tablet without requiring installation.
Frontend: React + Vite for a fast, near-native experience
Styling: Tailwind CSS for a cyberpunk/industrial HUD aesthetic
AI Engine: Google Gemini (Multimodal Vision), I chose it specifically for low-latency reasoning since safety feedback needs to be near real-time
Backend & Auth: Firebase (Firestore + Anonymous Auth) to log safety events instantly
One intentional design constraint I imposed was enforcing structured JSON-only outputs from the AI. This allowed OmniTech’s reasoning to directly control application state like locking buttons, changing UI modes and enforcing safety without relying on fragile text parsing.
Challenges I ran into
The hardest part wasn’t really the code but it was choosing the idea. I spent days stuck between “this is too simple” and “this is too ambitious,” falling into analysis paralysis trying to find the perfect concept.
Once I committed to OmniTech, the main technical challenge was handling real-time camera input in React without crashing the browser. I had to properly understand hooks, refs, and async state management to safely pipe live visual data into an LLM context. That learning curve was steep, but necessary.
Accomplishments that I'm proud of
The Safety Lock: Getting the AI to refuse actions until conditions are safe felt like a true “agent” moment.
Multimodal Integration: Successfully combining video frames and textual context into Gemini and receiving structured, actionable output.
Resilience: Pushing through camera API issues, UI frustration, and self-doubt until the system actually worked.
What I learned
This project taught me that integration is harder than generation. Getting an AI to produce text is easy; making it reliably interact with application state, enforce constraints, and behave predictably requires careful structure and discipline.
I also learned that you don’t need to be a senior engineer to build something meaningful, you just need to be willing to read the docs, ask questions, drink lots of coffee and iterate until it works.
What's next for Omni-Tech
Next, I plan to add audio reasoning so OmniTech can listen to machinery (detecting things like abnormal humming or grinding) and correlate those sounds with visual data. This would move OmniTech closer to being a truly multimodal field expert rather than just a visual assistant.
Beyond that, I also plan to add a lightweight login and dashboard experience so users can review past safety scans, diagnostics, and incident reports over time, turning OmniTech from a one-off tool into a persistent safety record for real-world field work.
Note: This app uses the Gemini 2.5 Flash Preview model. If you encounter a 429 Rate Limit error, please wait a moment for the quota to refresh.

Log in or sign up for Devpost to join the conversation.