-
-
Landing page
-
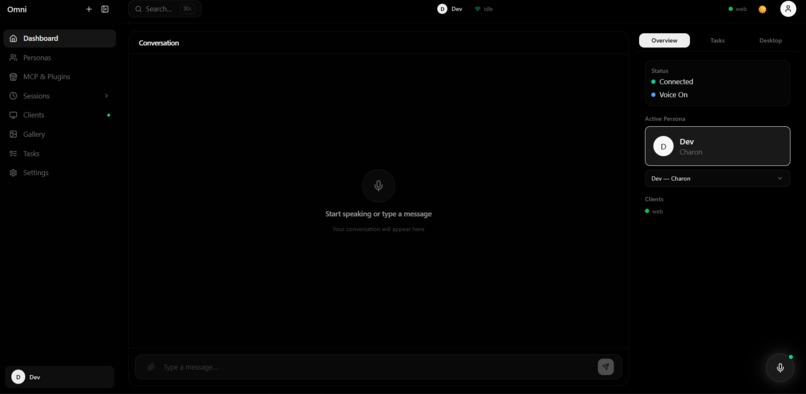
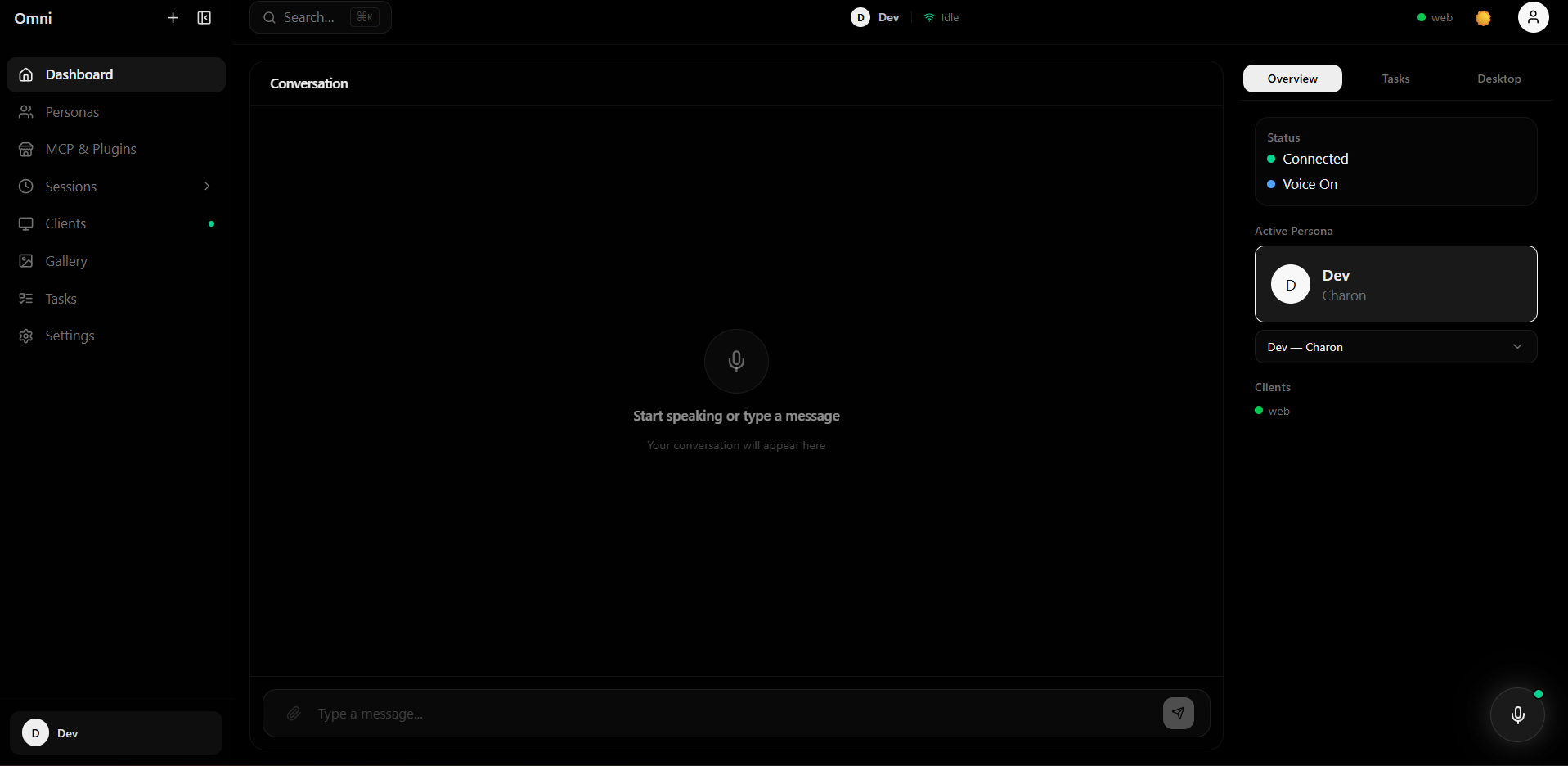
dashboard
-
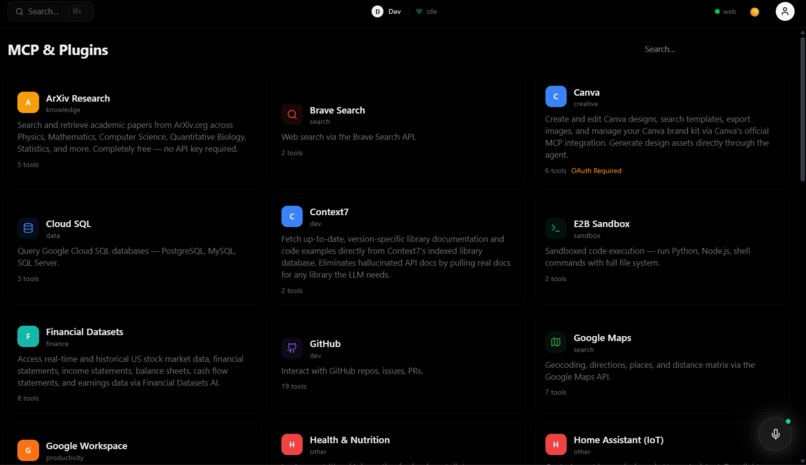
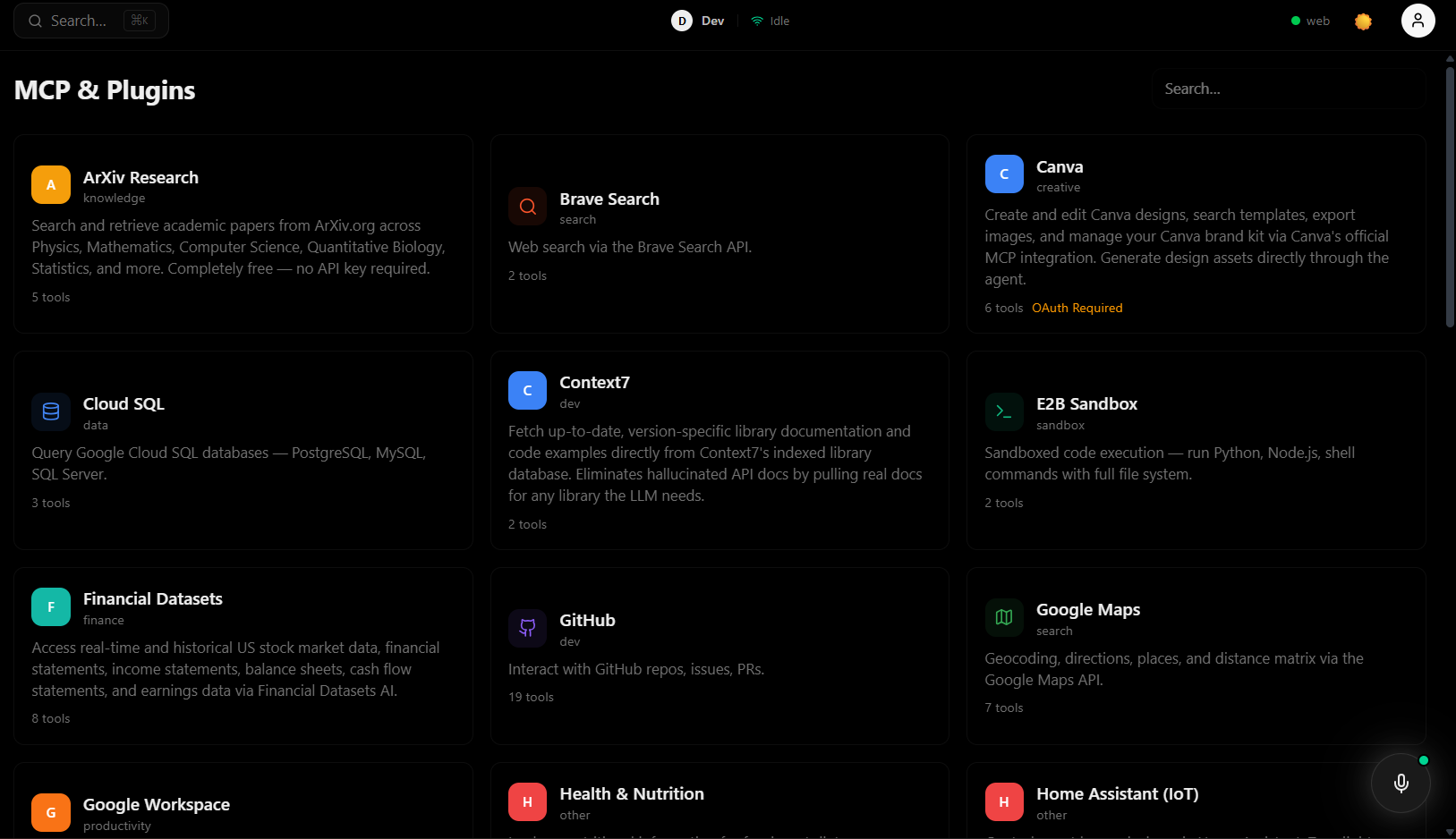
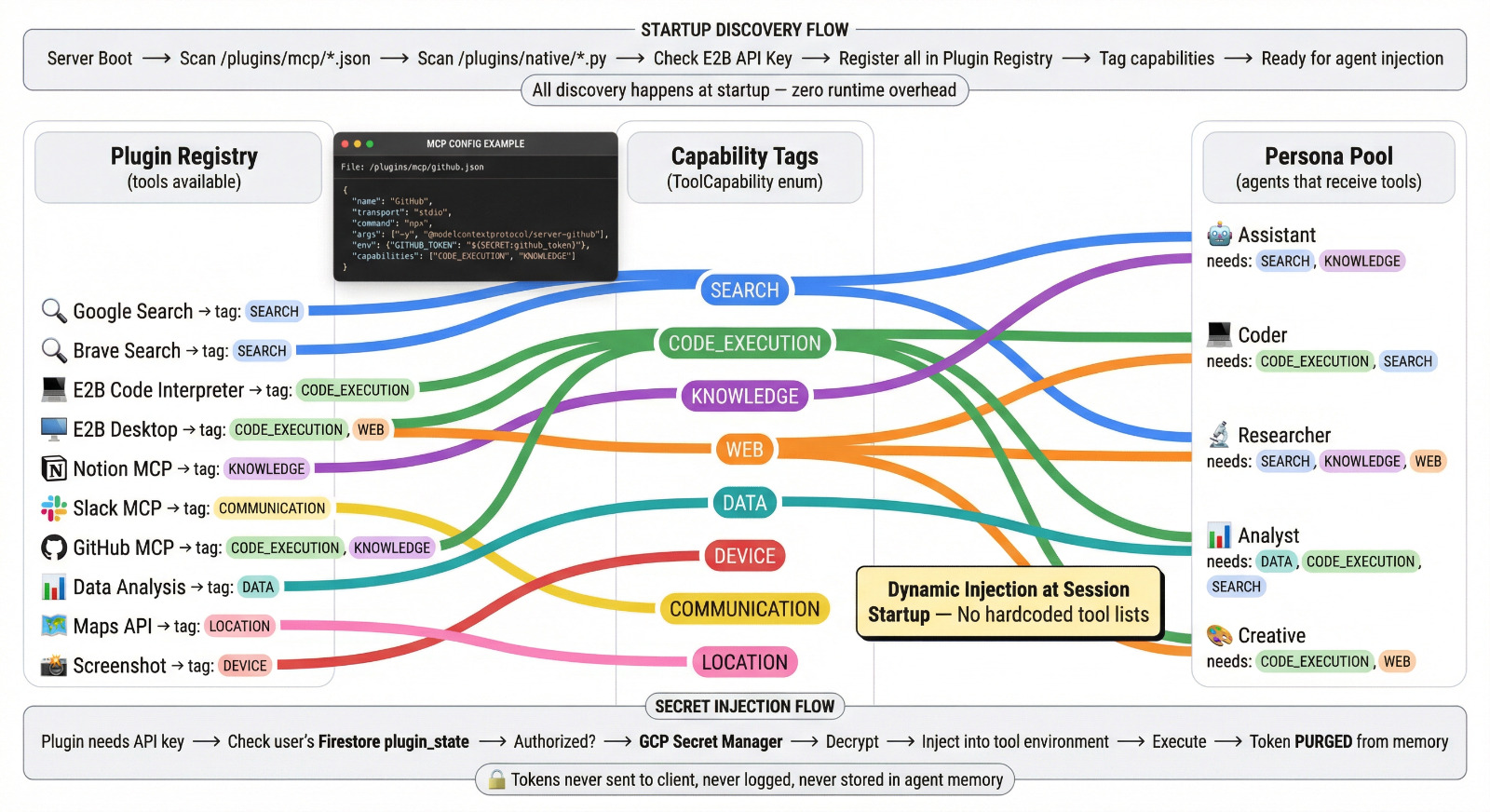
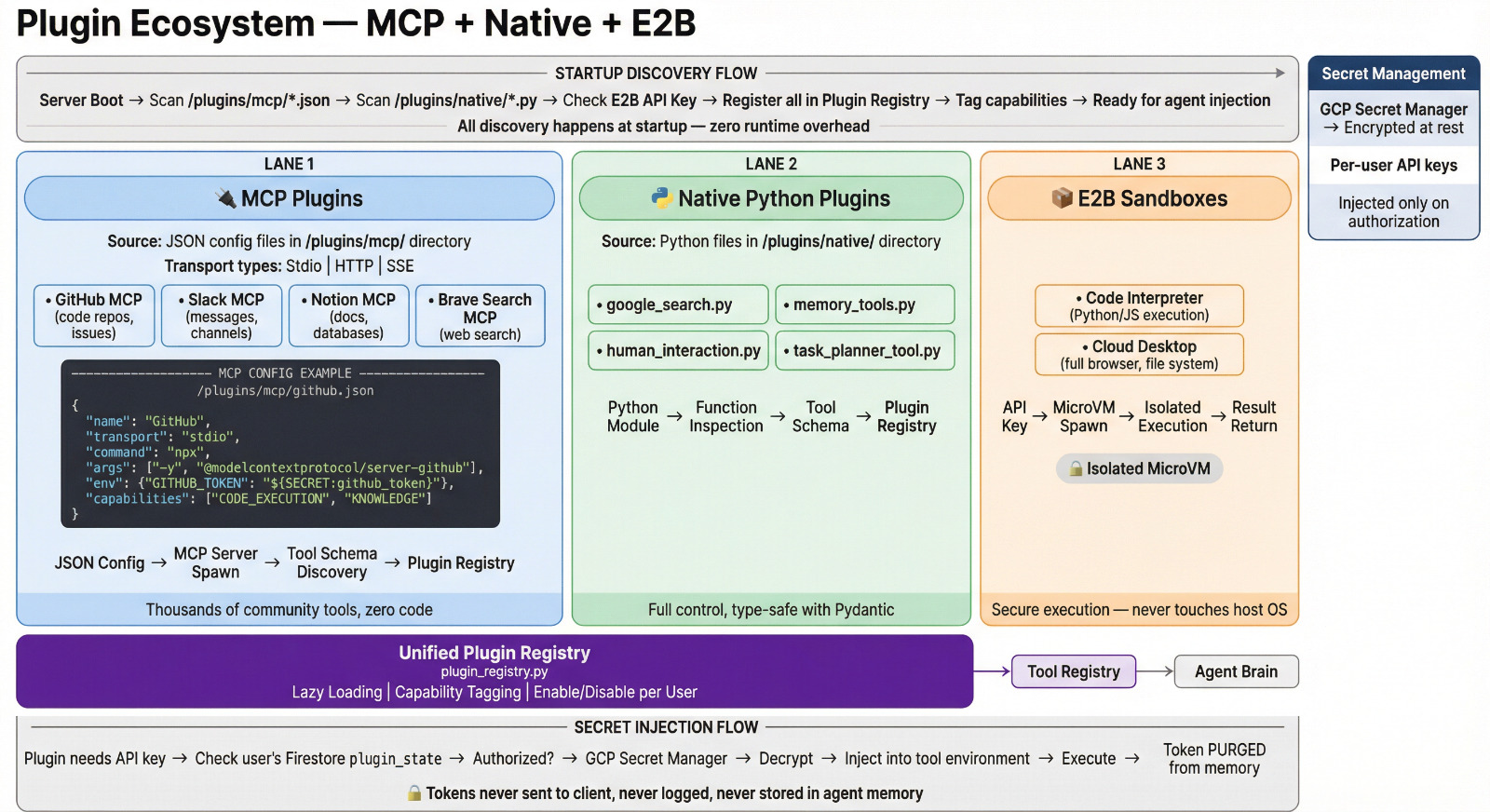
MCPs
-
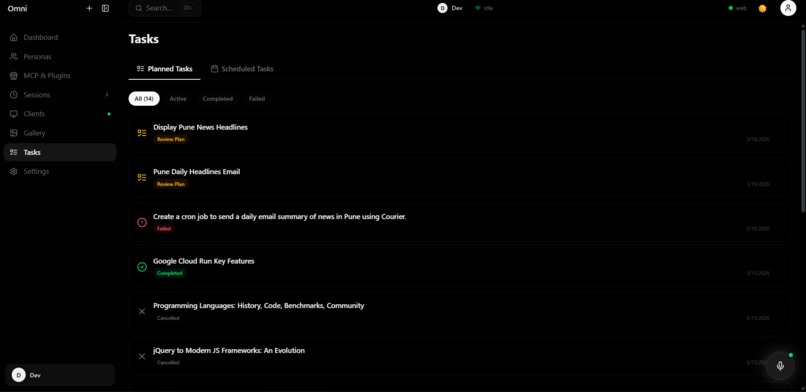
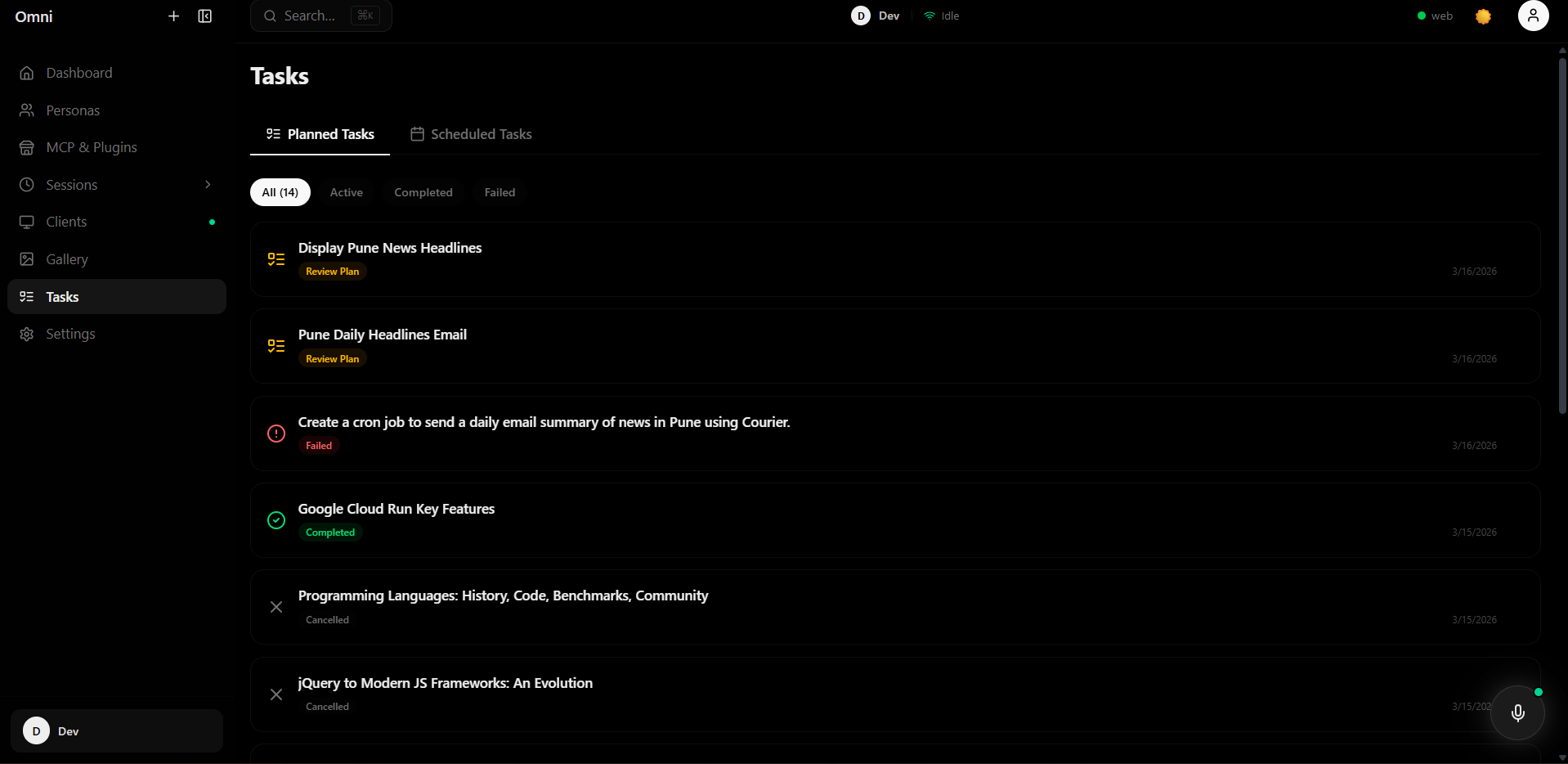
task lists
-
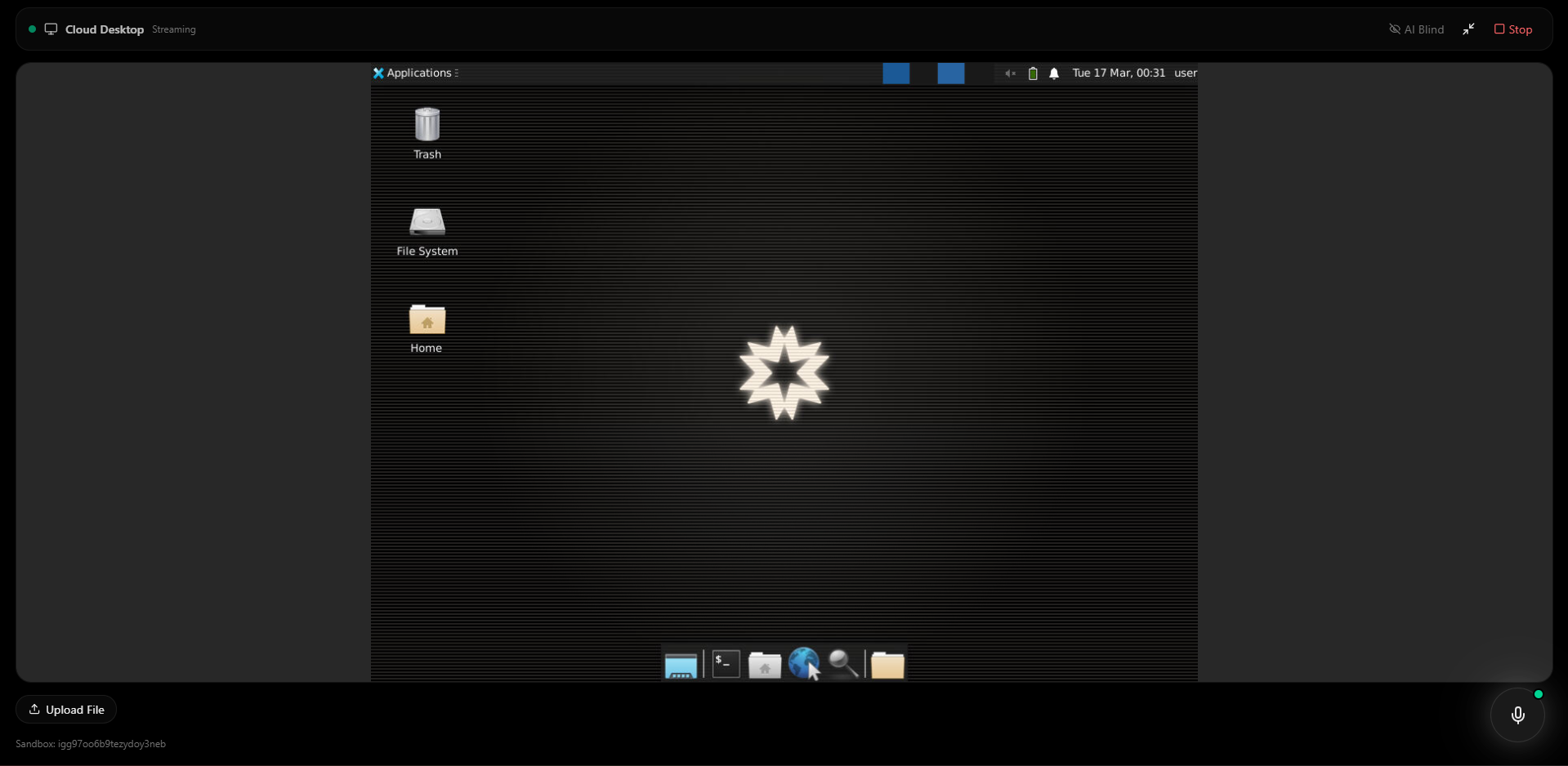
E2b Sandbox
-

Image gallary
-
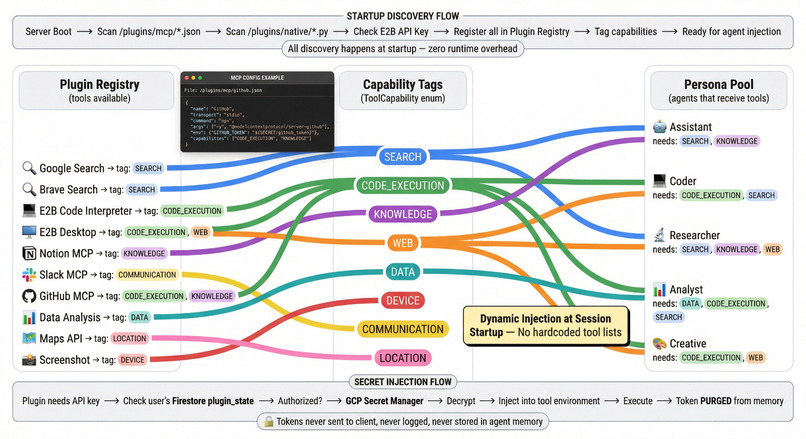
System Flow
-
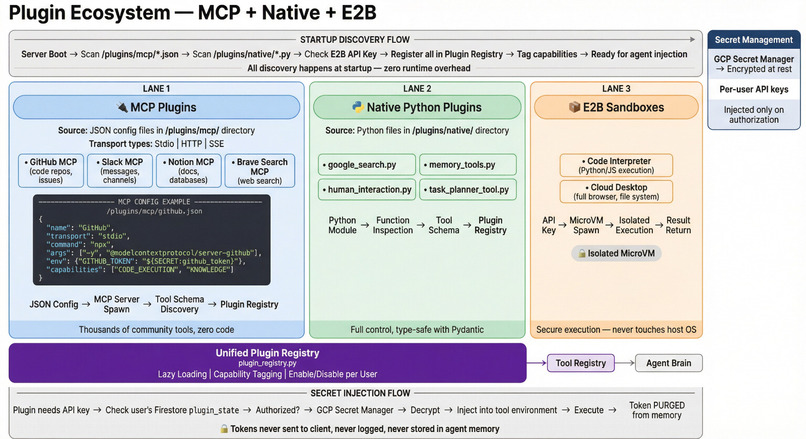
3 Tire Architecture

Omni — One AI Brain Across Every Device
Testing creds: id: omanand@gmail.com pass:123456
The Idea
Today, AI assistants exist everywhere — in browsers, phones, laptops, and smart devices - yet they operate in isolation. Each assistant lives inside its own platform and cannot seamlessly collaborate across devices.
We asked a simple question:
What if one intelligent AI agent could exist across every device you own?
Instead of separate assistants, imagine a single AI brain that you can talk to from anywhere — your laptop, phone, browser, or even a small robot on your desk — and it can act across all of them simultaneously.
This idea became Omni.
Omni is a multi-client AI agent hub powered by Gemini Live API that enables real-time multimodal interaction across devices.
With Omni, you can:
- Speak to a robot on your desk
- Trigger actions on your web dashboard
- Store data from your phone
- Execute tasks on a cloud desktop
—all through one AI agent.
Inspiration
Our inspiration came from observing how fragmented the current AI ecosystem is.
Voice assistants can answer questions but cannot interact deeply with developer tools. Web-based AI systems cannot easily control IoT devices. Robots and embedded systems are usually isolated from modern AI workflows.
We wanted to bridge these worlds by creating a unified AI interface that connects hardware, software, and cloud intelligence.
We were also inspired by the concept of agentic AI systems — AI that doesn't just respond but acts across environments.
Omni explores what the future might look like when AI agents become the operating system for your digital life.
What Omni Does
Omni is a multi-device AI agent platform that connects multiple clients to a single intelligent backend powered by Gemini Live API.
Users can interact with Omni through:
- Web dashboard
- Mobile interface
- Chrome extension
- Desktop tray application
- Embedded hardware devices such as ESP32-based robots or smart glasses
Each client communicates with the same central AI agent.
This enables cross-device actions, such as:
- Speaking to the robot and seeing results appear on the dashboard
- Saving information from mobile that instantly syncs to the desktop
- Generating charts, reports, or visualizations live in the web interface
- Executing tasks on a cloud-hosted desktop environment
Omni effectively becomes a universal AI layer across devices.
Multimodal AI Interaction
Omni was designed as a true multimodal AI system.
It supports:
Audio Input
- Real-time voice streaming using ESP32 microphones
- Users can talk naturally to the AI agent
Audio Output
- AI responses played through speakers connected to hardware devices
Visual Output
- Dynamic dashboards showing charts, cards, and insights generated by the agent
Hardware Interaction
- Embedded devices such as a mini table robot act as physical interfaces for Omni
This combination allows Omni to move beyond simple text interactions and into real-world embodied AI experiences.
Hardware Agent: The Mini Table Robot
To demonstrate Omni in the physical world, we built a small AI-powered tabletop robot.
The robot includes:
- ESP32 microcontroller
- I2S microphone for voice input
- Speaker for AI voice responses
- OLED display with animated AI eyes
The robot streams audio to the Omni backend, where the Gemini Live API processes the conversation and returns responses in real time.
This creates a natural voice interface to the AI agent, making Omni feel like a living assistant rather than just software.
Architecture
Omni uses a multi-layer architecture designed for scalability.
Device Layer
- ESP32 robot
- Browser clients
- Mobile interfaces
- Chrome extension
Communication Layer
- Real-time audio streaming
- WebSocket communication
- REST APIs
Agent Layer
- Gemini-powered agent logic
- Context management
- task orchestration
Cloud Layer
- Backend services deployed on Google Cloud
- AI processing using Gemini models
This architecture enables real-time interaction across multiple devices simultaneously.
Google Cloud & Agent Infrastructure
To power Omni at scale, we deeply integrated multiple Google Cloud services along with the Agent Development Kit (ADK). Our backend is built on a serverless architecture using Cloud Run, which allows us to deploy containerized AI services that automatically scale based on real-time demand while optimizing resource usage. ([Google Cloud][1])
We implemented a CI/CD pipeline using Cloud Build to automate the process of building, testing, and deploying our services, ensuring rapid iteration and reliability. For scheduling background tasks and periodic agent workflows, Cloud Scheduler is used to trigger jobs such as context cleanup, data syncing, and agent maintenance.
At the core of Omni’s intelligence lies Vertex AI, which provides a unified platform to build, deploy, and scale generative AI systems powered by Gemini models. ([Google Cloud][2]) We leveraged Vertex AI not only for inference but also for managing prompts, multimodal interactions, and experimentation through its developer tooling.
Using Google’s Agent Development Kit (ADK), we structured Omni as a modular, tool-augmented agent capable of reasoning, planning, and executing cross-device actions. ADK enabled us to design a flexible agent architecture with support for context memory, tool invocation, and multi-agent workflows, all of which can be deployed seamlessly to production environments like Cloud Run or Vertex AI Agent Engine. ([Google Cloud Documentation][3])
This deep integration of Google Cloud and ADK allows Omni to transition from a prototype into a production-ready, scalable, and extensible AI agent ecosystem.
Key Features
Live AI Agent
Users can talk to Omni in real time through voice-enabled hardware.
Multi-Client Architecture
One AI agent connects to multiple devices simultaneously.
GenUI Dashboard
Omni dynamically generates charts, tables, code blocks, and data cards on the dashboard while responding.
Agent Personas
Users can switch between specialized AI personalities such as:
- Analyst
- Developer
- Researcher
Each persona has different capabilities and voice responses.
Cross-Device Actions
Commands executed on one device instantly appear across others.
Example:
"Save this insight to my dashboard."
The information becomes visible immediately on the web interface.
Technologies Used
- Google Gemini Live API
- Google GenAI SDK / Agent Development Kit
- Google Cloud backend services
- React.js dashboard
- Node.js / Python backend
- ESP32 microcontrollers
- I2S audio streaming
- WebSockets for real-time communication
Challenges We Faced
Building Omni required solving several technical challenges.
Real-time audio streaming
Handling low-latency audio between ESP32 devices and the backend required careful buffering and streaming optimization.
Multi-client synchronization
Ensuring that actions triggered from one device instantly reflected across others required designing a reliable event-driven architecture.
Hardware and AI integration
Connecting embedded devices with modern AI systems required bridging microcontroller networking with cloud AI APIs.
Designing a natural interaction model
Creating a system that feels like one coherent AI agent instead of multiple disconnected tools required thoughtful architecture and context management.
What We Learned
This project taught us several valuable lessons:
- How to design agentic AI systems
- Integrating hardware with cloud AI services
- Building multimodal interaction systems
- Creating scalable multi-client architectures
Most importantly, we learned that AI agents become far more powerful when they exist across devices rather than inside a single application.
Future Vision
Omni is just the beginning.
Future versions could include:
- Smart glasses integration
- Vision-based AI agents
- autonomous device orchestration
- collaborative AI agents
We envision a world where AI agents become the connective tissue between humans and their digital environment.
Omni is our step toward that future.










Log in or sign up for Devpost to join the conversation.