Inspiration
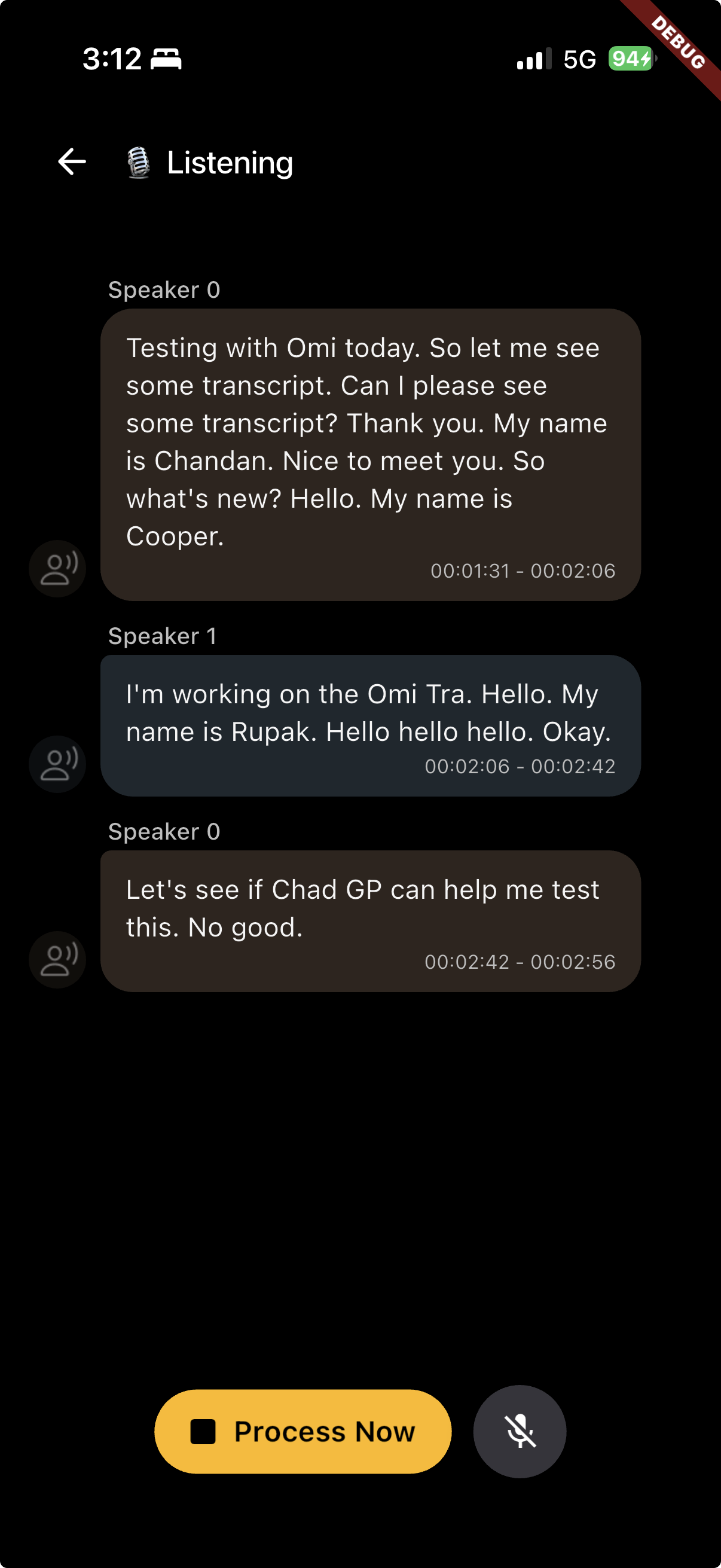
The spark for this project came during an Omi workshop where the team discussed a fascinating dating app concept that analyzes conversation compatibility. I realized that for any such application to work, the fundamental missing link was a "Voice CRM"—the ability for a device to truly "know" who is speaking beyond just the user. Currently, Omi identifies the owner but treats everyone else as a generic "Speaker 1" or "Speaker 2." I was inspired to bridge this gap individually, turning Omi from a transcription tool into a context-aware assistant that understands human relationships and social dynamics.
What it does
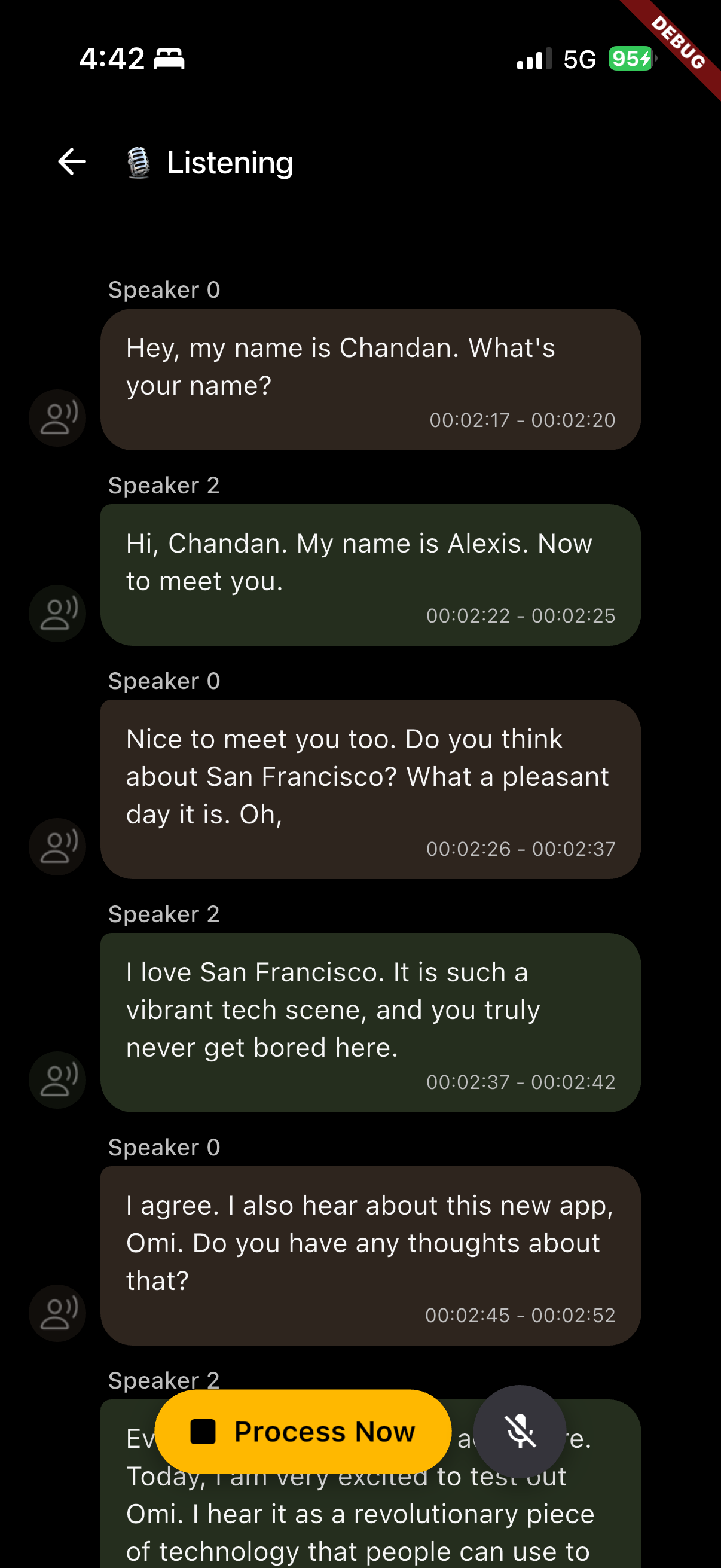
My implementation creates a persistent identity for every voice Omi hears. I biometrically linked voice profiles to specific contact records in Firestore, allowing for seamless speaker identification across multiple conversations.
- Auto-Learning: I built a system that automatically creates and enrolls new people when it detects phrases like "My name is...".
- Intelligent Caching: I implemented a two-tier caching system to identify speakers instantly without lagging the live transcript.
- Biometric Persistence: Once a person is enrolled, Omi recognizes them by voice alone in any future session.
How I built it
I built a bidirectional data bridge between Firestore (relational person data) and Pinecone (high-dimensional vector embeddings).
- SpeechBrain Integration: I pivoted from Pyannote to SpeechBrain to generate voice embeddings, as it provided a more robust and reliable model download experience for production environments.
- Backend Architecture: I modified the transcription WebSocket flow to include a custom Conversation Audio Buffer, allowing the system to "look back" at audio segments for enrollment when names are detected in the text stream.
- Optimization: To keep costs low and performance high, I implemented a pre-loading strategy that fetches the user's most frequent contacts at the start of a session.
Challenges I ran into
The most daunting challenge was the sheer scale of the Omi ecosystem. Within a strict 7-day timeline, I had to individually understand, set up, and run the entire stack—from the complex transcription WebSockets in the backend to the live-updating frontend and the various integrated APIs. Navigating a codebase of this size for the first time while ensuring the frontend, backend, and external databases (Firestore/Pinecone) communicated perfectly was a massive undertaking for a solo developer.
Technically, I also faced Model Stability issues; constant failures with Pyannote's automated downloads threatened to stall my project, leading to my pivot to SpeechBrain. Furthermore, I had to solve a Latency-Cost Tradeoff. Querying a vector database for every spoken sentence is expensive and slow. I solved this by building a Conversation-Level Speaker Cache, which reduced redundant Pinecone queries by over 90% in long discussions.
Accomplishments that I'm proud of
- Full Stack Integration: I successfully stood up the complete Omi environment and deployed my speaker-linking features across the entire pipeline in just one week.
- Seamless Automation: I achieved a flow where Omi learns a new person's voice and name entirely through natural conversation without any manual UI input.
- Cost Efficiency: I developed a scalable architecture that stays within the Firebase and Pinecone Free Tiers for standard users by shifting the heavy lifting to local in-memory caching.
- Cross-Session Memory: I successfully proved that Omi can recognize a guest in "Conversation B" because it met them once in "Conversation A".
What I learned
I learned that in real-time AI, Data Orchestration is just as critical as the model itself. The "magic" isn't just in the voice embedding; it’s in how I linked that math to a human-readable database like Firestore. I also gained deep experience in managing real-time audio buffers within WebSockets—a task that requires precise timing to ensure the audio matches the transcribed text. Most importantly, I learned how to move fast in a large, unfamiliar codebase to deliver a production-ready feature under pressure as an individual contributor.
What's next for OMI-speaker-identification-linking
This is just the first step toward a more socially intelligent Omi. Next, I plan to:
- Shared Profiles: Implement the ability for users to share their voice profiles with others, so Omi can recognize "trusted contacts" instantly without re-learning them.
- Relationship Graphing: Using the persistent
person_idto map how often you speak to certain people, providing insights into your social health. - Refined Accuracy: Fine-tuning the SpeechBrain models to handle noisier environments like cafes or busy offices where multiple voices overlap.
Would you like me to help you create a concise "How to Run" guide for the judges to help them test your individual full-stack implementation quickly?
Built With
- cloud-firestore
- dart
- deepgram
- fastapi
- firebase-authentication
- firebase-cli
- flutter
- git
- google-cloud
- huggingface
- ngrok
- openai-whisper
- pinecone
- pydub
- python
- redis
- speechbrain
- upstash
- websockets

Log in or sign up for Devpost to join the conversation.