-
Homepage
-
tree
-
step 3
-
step 5
-
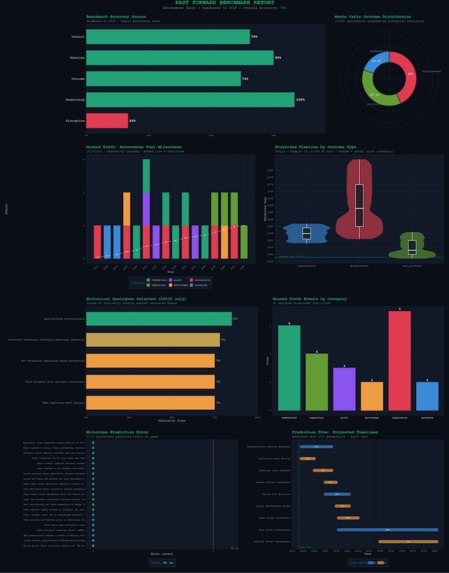
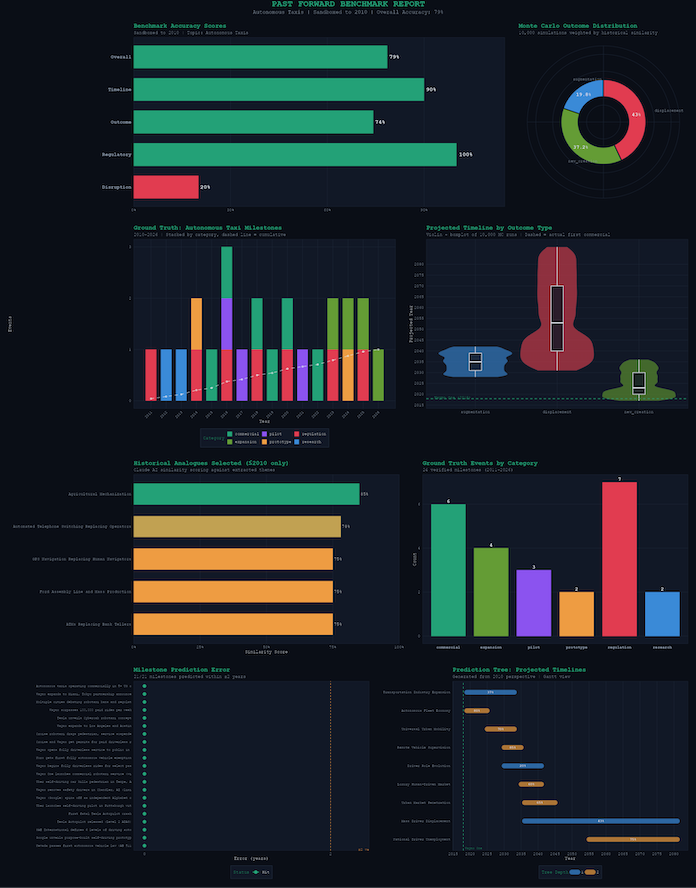
benchmark graphs made with R
inspiration
We kept hearing the same thing at every AI demo: "Claude says theres a 70% chance of X." But where does that 70% come from? The model made it up. Theres no data behind it, no way to verify it, no historical basis, just vibes dressed up as statistics.
We wanted to build a prediction tool where every single number is traceable back to real data. If the system says theres a 58% chance of augmentation, you should be able to grab a calculator and verify that number yourself from the inputs.
the idea crystallized around a simple question: "What if we treated historical events like a probability distribution and actually simulated from it, instead of asking a LLM to guess?"
What it does
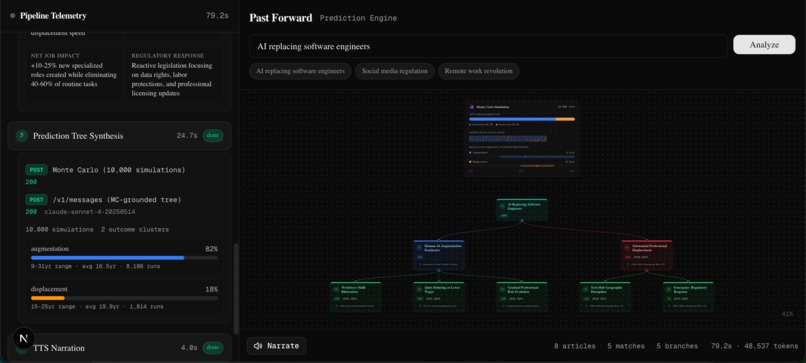
Past Forward takes any current n ews topic ("AI replacing radiologists," "autonomous trucking," "EU AI regulation") and runs it through a 6-step prediction pipeline:
- News Ingestion: Claude searches the live web for recent articles about the topic
- Entity Extraction: Claude pulls out key themes and displacement patterns from the articles
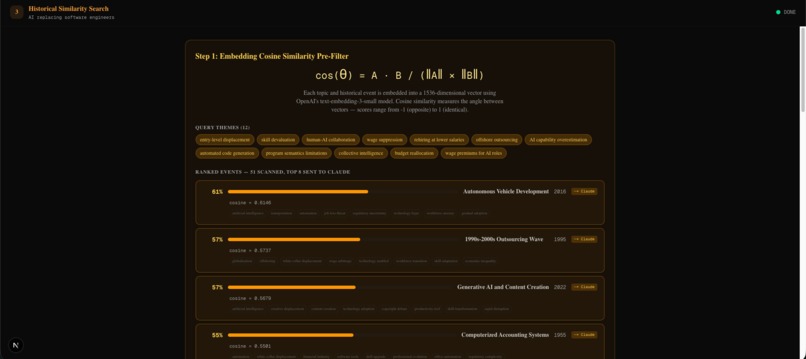
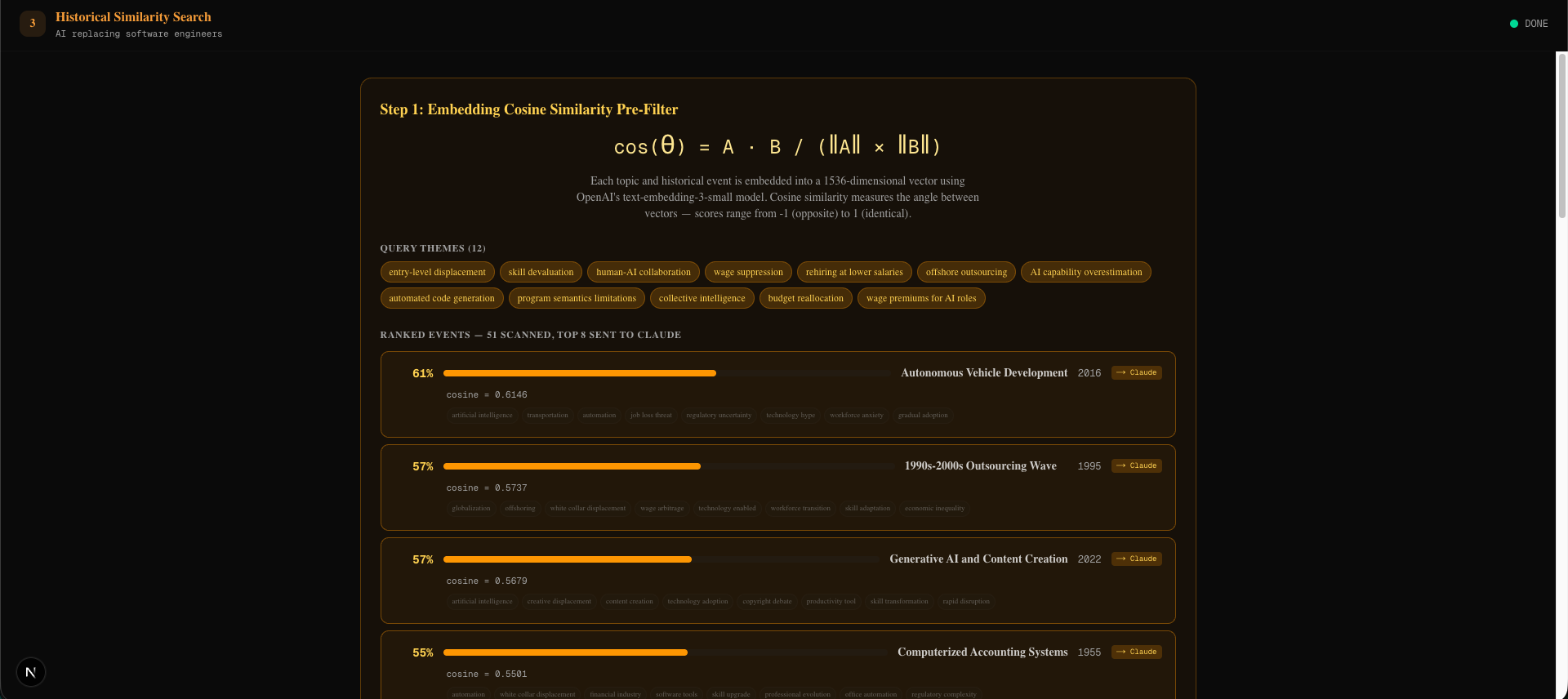
- Historical Similarity Search: We embed the topic using OpenAI's text-embedding-3-small, compute cosine similarity against 50+ pre-embedded historical events, then have Claude re-score the top 8 candidates for deeper semantic matching
- Pattern Convergence: Claude analyzes what the matched historical events have in common
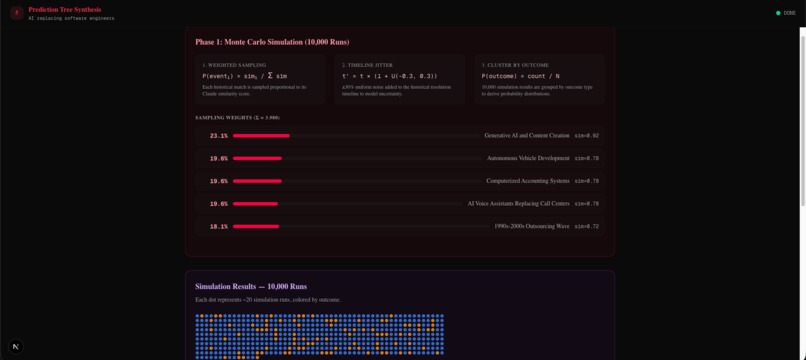
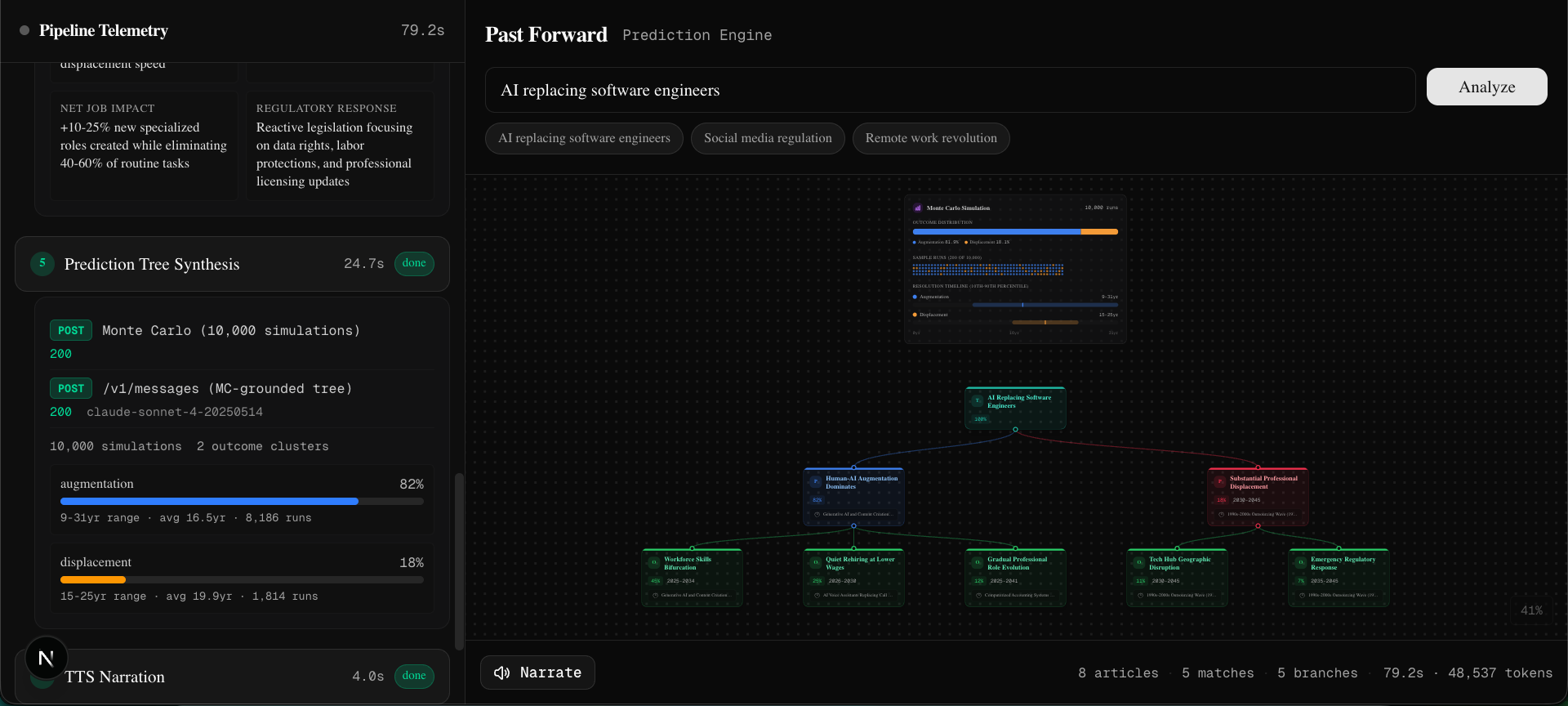
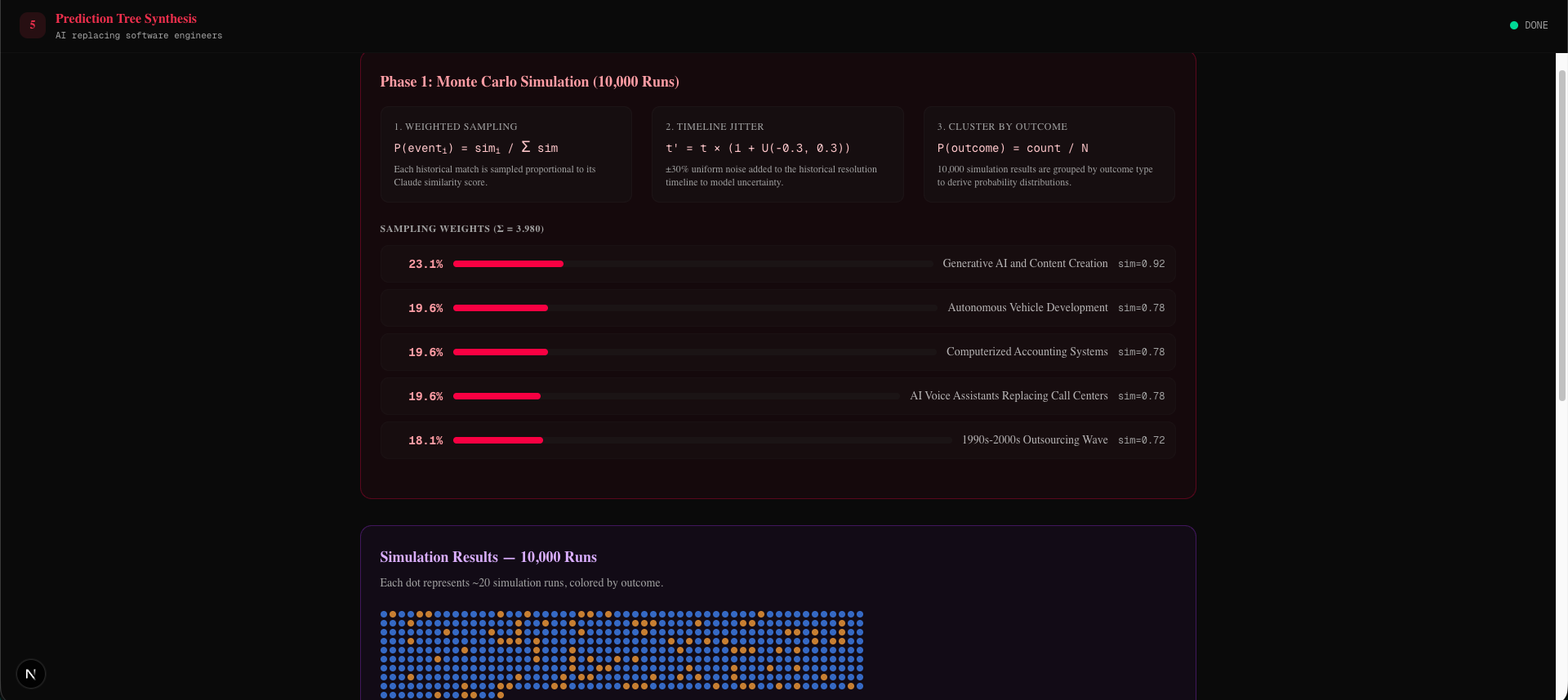
- Monte Carlo Simulation: We run 10,000 simulations sampling historical events weighted by their similarity scores to produce grounded probability distributions
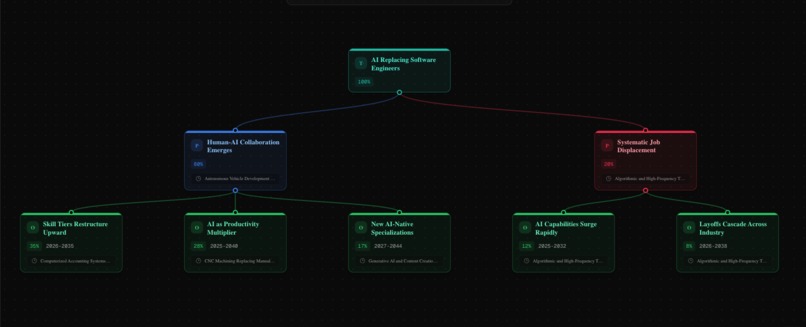
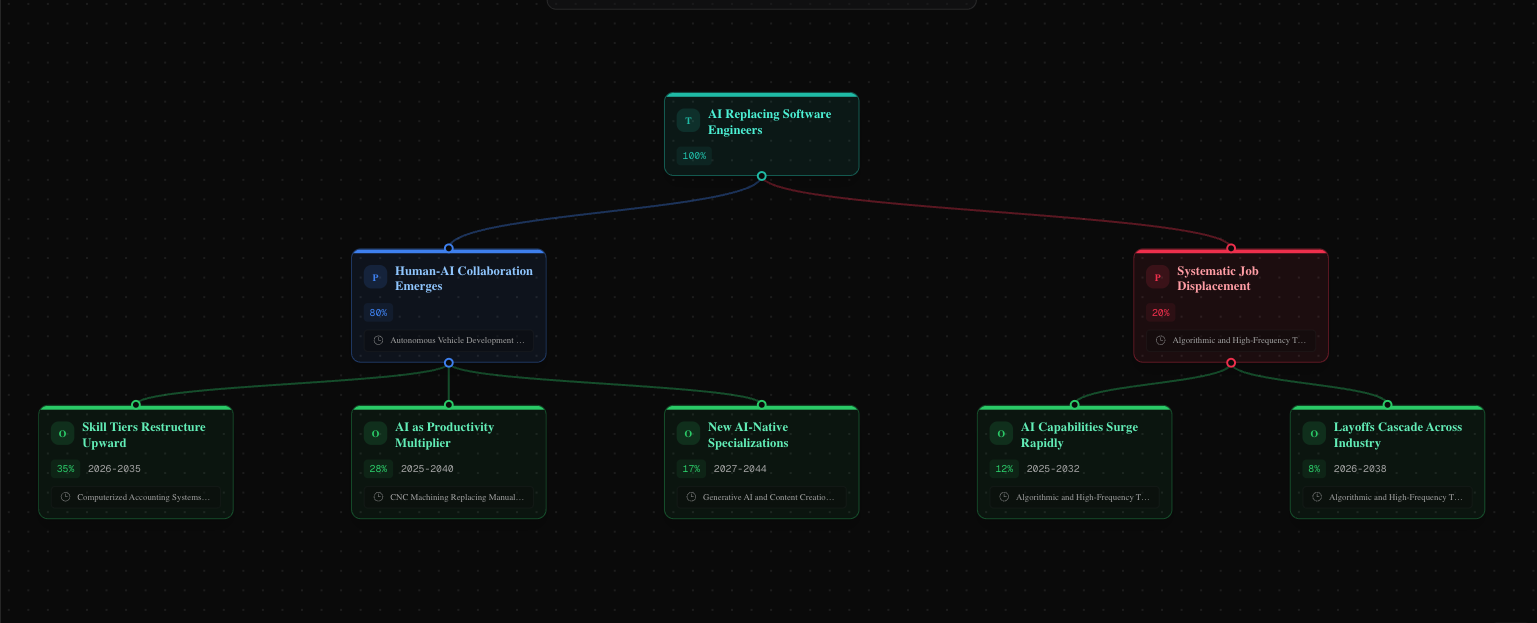
- Prediction Tree: Claude generates a branching prediction tree constrained to the Monte Carlo probabilities, with every branch linked to a specific historical precedent
The entire pipeline streams to the frontend via Server-Sent Events so the user watches every API call, every similarity score, and every simulation result show up in real-time.
How we built it
The core math, cosine similarity for matching:
We embed both the users topic and each historical event into 1,536-dimensional vectors using OpenAI's embedding model. To compare them we compute cosine similarity, which simplifies to a dot product since the vectors are unit-normalized:
$$\cos(\theta) = \mathbf{A} \cdot \mathbf{B} = \sum_{i=1}^{1536} a_i \times b_i$$
This gives us a fast pre-filter (50+ events ranked in <1ms), after which Claude re-scores the top 8 with deeper reasoning.
The core math, Monte Carlo simulation:
Each matched historical event has a similarity score $s_i$ and an outcome type. We normalize scores into sampling probabilities:
$$P(\text{event}i) = \frac{s_i}{\sum{j} s_j}$$
Then we run 10,000 simulations. Each simulation samples one event using inverse CDF sampling, records its outcome type, and applies ±30% uniform jitter to the historical timeline:
$$t' = t \times (1 + U(-0.3, +0.3))$$
After all runs we cluster by outcome type and count:
$$P(\text{outcome}) = \frac{\text{count}(\text{outcome})}{N}$$
The standard error at $N = 10{,}000$ is:
$$SE = \sqrt{\frac{p(1-p)}{N}} \approx \pm 0.5\%$$
The key architectural decision: Claude never produces the probabilities. Monte Carlo produces them from the similarity scores. Claude then generates human-readable labels and descriptions for each branch, but is explicitly constrained: "You MUST use the Monte Carlo probabilities, do NOT invent your own."
Stack: Next.js 16 with App Router, React 19, Tailwind CSS 4, shadcn/ui, Framer Motion. The backend is a single SSE endpoint that runs all 6 steps sequentially and streams events to the frontend. multi-device support lets iPads display individual pipeline steps full-screen via a listener API.
Challenges we ran into
Getting Claude to return clean JSON consistently. Claude sometimes wraps JSON in markdown backticks or adds explanation text. We built a multi-layer parser that tries direct parse first, then strips backticks, then regex extracts the JSON array.
Balancing embedding pre-filter vs Claude scoring. Pure embeddings miss causal patterns ("ATMs didnt replace tellers, they transformed the role"). Pure Claude scoring on 50+ events would be too slow and expensive. The two-phase approach where embeddings narrow to 8 and then Claude scores those 8 in parallel was the sweet spot.
Explaining Monte Carlo to judges. The hardest part wasnt building it, it was explaining why we simulate instead of just asking Claude. We had to make the case that traceable, data-grounded probabilities are fundamentally different from LLM-hallucinated ones.
Accomplishments that we're proud of
Every probability in the final output can be traced back to specific historical events and their similarity scores with a calculator. The 10,000-run Monte Carlo simulation executes in ~10ms in pure JavaScript, no external API needed. the visible pipeline design means users watch every API call, token count, and intermediate result stream in real-time. Multi-device demo mode where each pipeline step can be displayed full-screen on a seperate iPad.
What we learned
Embeddings are surprisingly good at semantic matching. Cosine similarity between "AI automating medical diagnosis" and "ATMs automating bank transactions" correctly identifies the structural parallel even though the domains are completely different.
Monte Carlo is underused in AI applications. Everyone asks LLMs to estimate probabilities. Almost nobody uses actual statistical simulation to derive them from data. the technique is 80 years old and it works.
Streaming changes everything for UX. A 40-second pipeline that shows nothing until the end feels broken. The same pipeline streaming every step in real-time feels fast and transparent.
What's next for Past Forward
Expand the historical events database beyond 50+ events using automated research. Add a vector database for the similarity pre-filter so it scales to thousands of events. Let users add their own historical events and see how predictions shift. Implement confidence warnings when all similarity scores are low (no good historical match).
Built With
- anthropicapi
- elevenlabsapi
- framer
- next.js
- node.js
- openaiapi
- r
- react
- shadcn
- sqlite
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.