The Problem
Businesses lose over $75 billion a year to poor customer service. Feedback sits unread in spreadsheets. Support agents copy-paste from outdated docs. When negative sentiment spikes, nobody connects it to what customers are actually asking in support chats — because feedback, chat, tickets, and analytics all live in different tools.
Omega fixes this: one platform, one data layer (Elasticsearch), one AI orchestration layer (Elastic Agent Builder) connecting feedback collection, customer support, and automated workflows.
What It Does
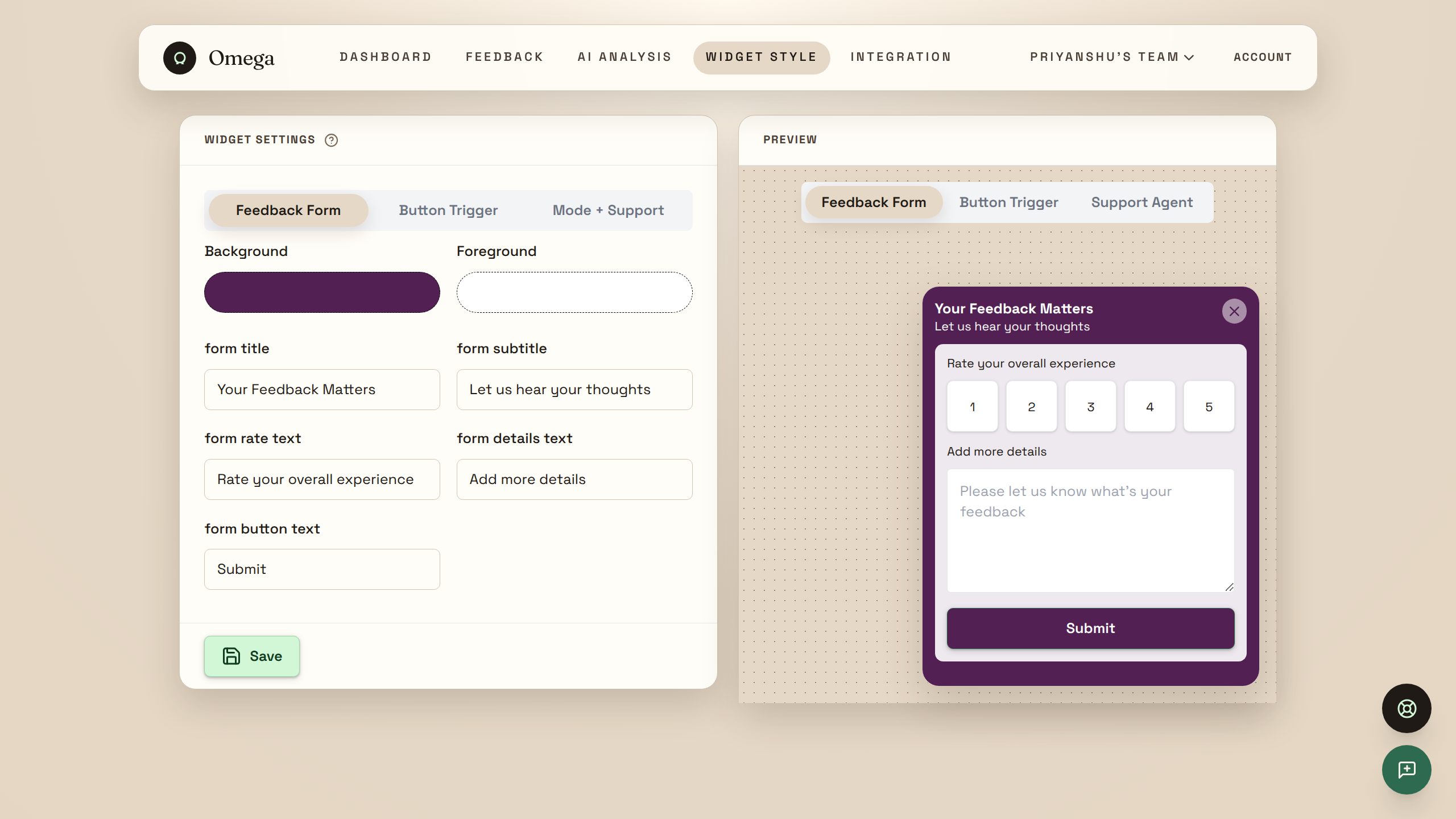
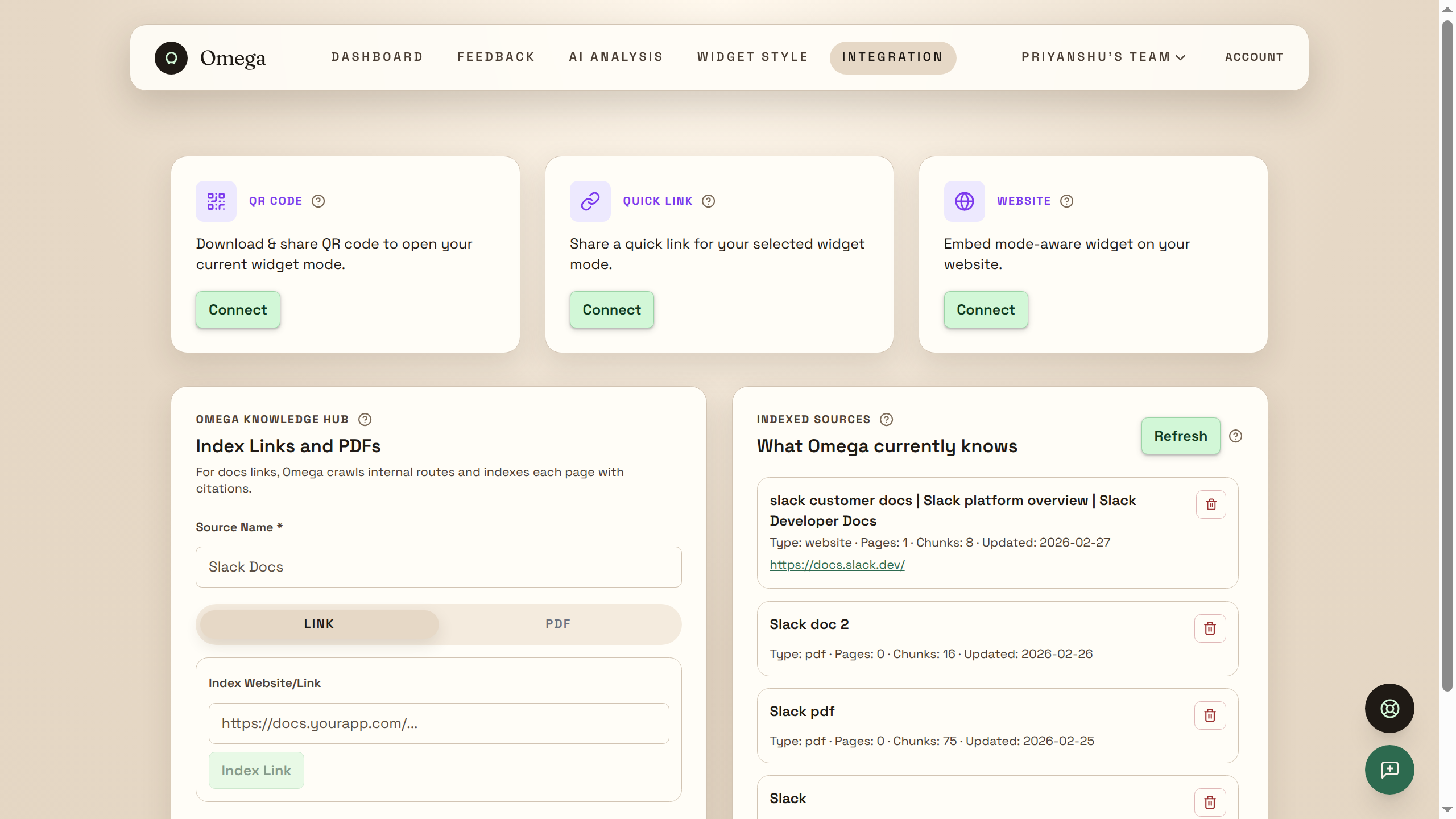
Omega is a dual-mode SaaS platform — Feedback Analytics + AI Customer Support — running entirely on Elasticsearch. Businesses embed a widget with 2 lines of code (or share a direct link/QR code). The same widget handles feedback collection or AI support, configurable per team.
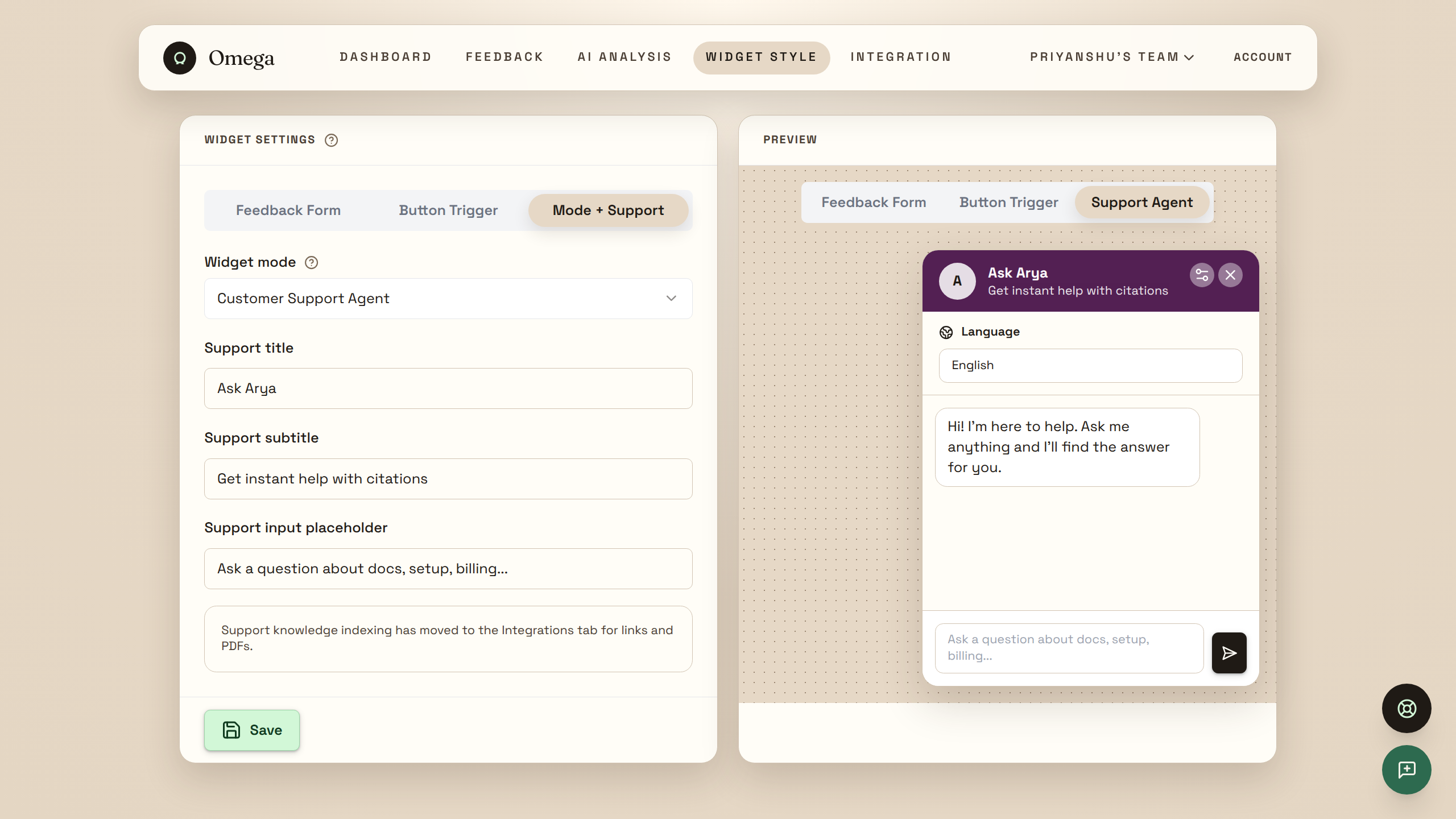
Arya: AI Customer Support Agent
Customers chat with Arya through the embeddable widget. Under the hood:
- Hybrid search on
support_docsusing BM25 (lexical) + KNN (vector) with Reciprocal Rank Fusion (RRF, k=60) - The
omega_customer_supportagent in Elastic Agent Builder generates grounded responses with inline[1],[2]citations mapped to actual source documents - Auto-detects 6 languages (English, Spanish, French, German, Hindi, Arabic) — queries are translated to English for search, responses translated back with citations preserved
- A confidence score is computed from retrieval relevance (75%) and source coverage (25%)
When confidence drops below 55%, the user asks for a human, or frustration is detected, the Smart Escalation Workflow fires automatically: the omega_smart_escalation agent reads the full conversation via omega_conversation_history ES|QL tool, classifies severity (P0–P3), creates a prioritized ticket in support_tickets, and sends a Slack alert for P0/P1.
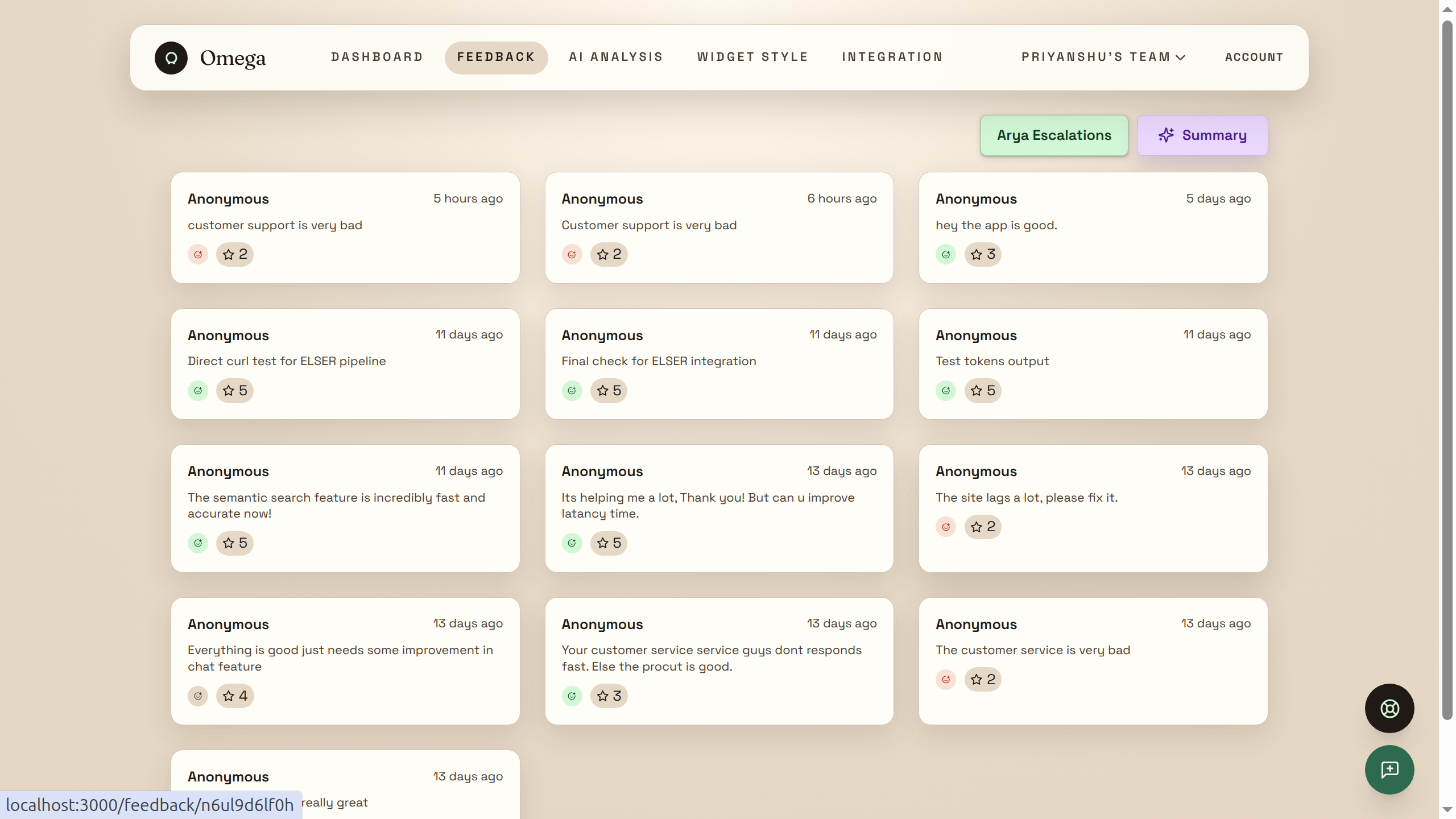
Feedback Analytics
Every feedback submission hits an ingest pipeline that auto-extracts sentiment (positive/neutral/negative) and generates vector embeddings at index time — no separate processing step.
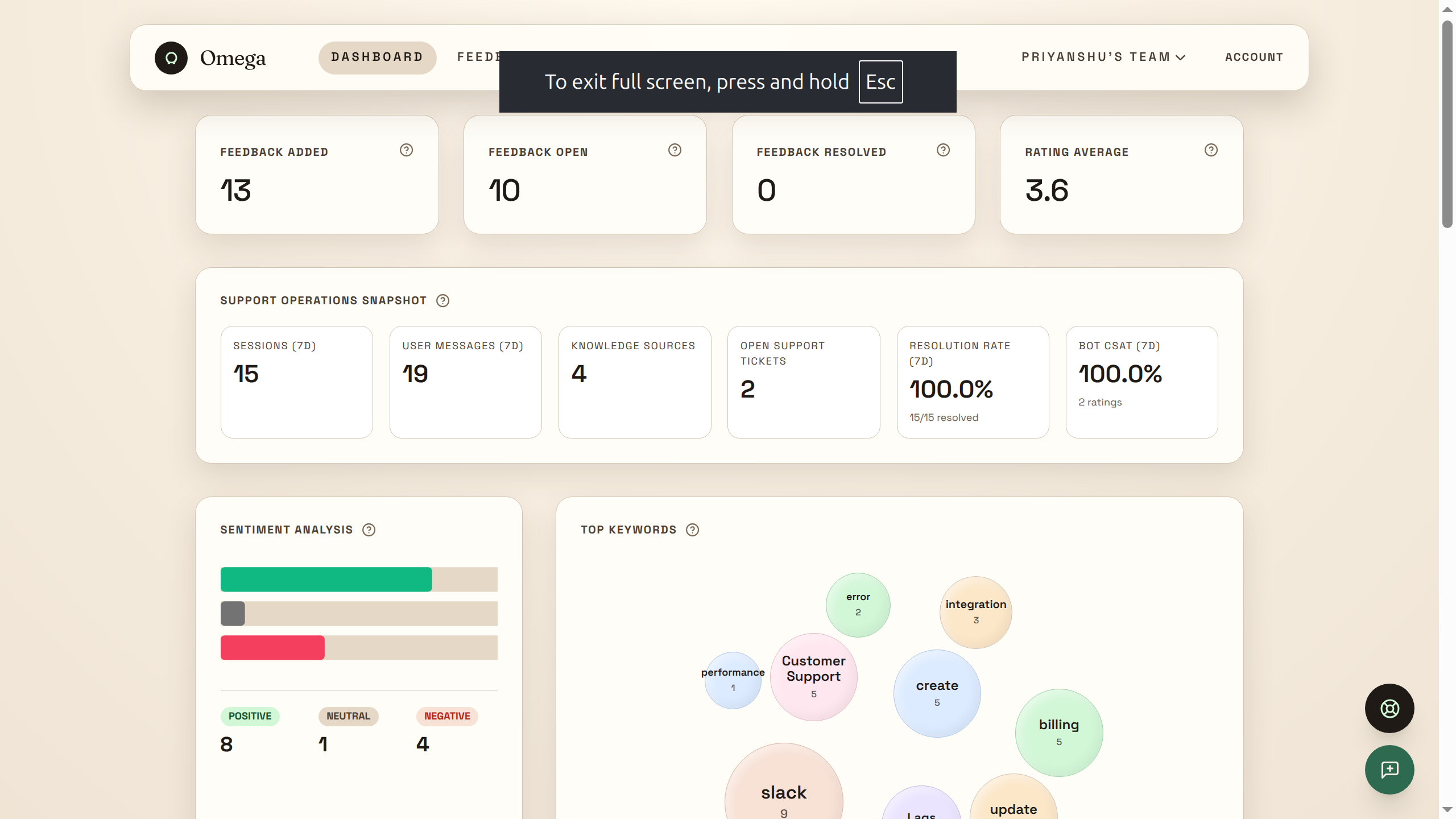
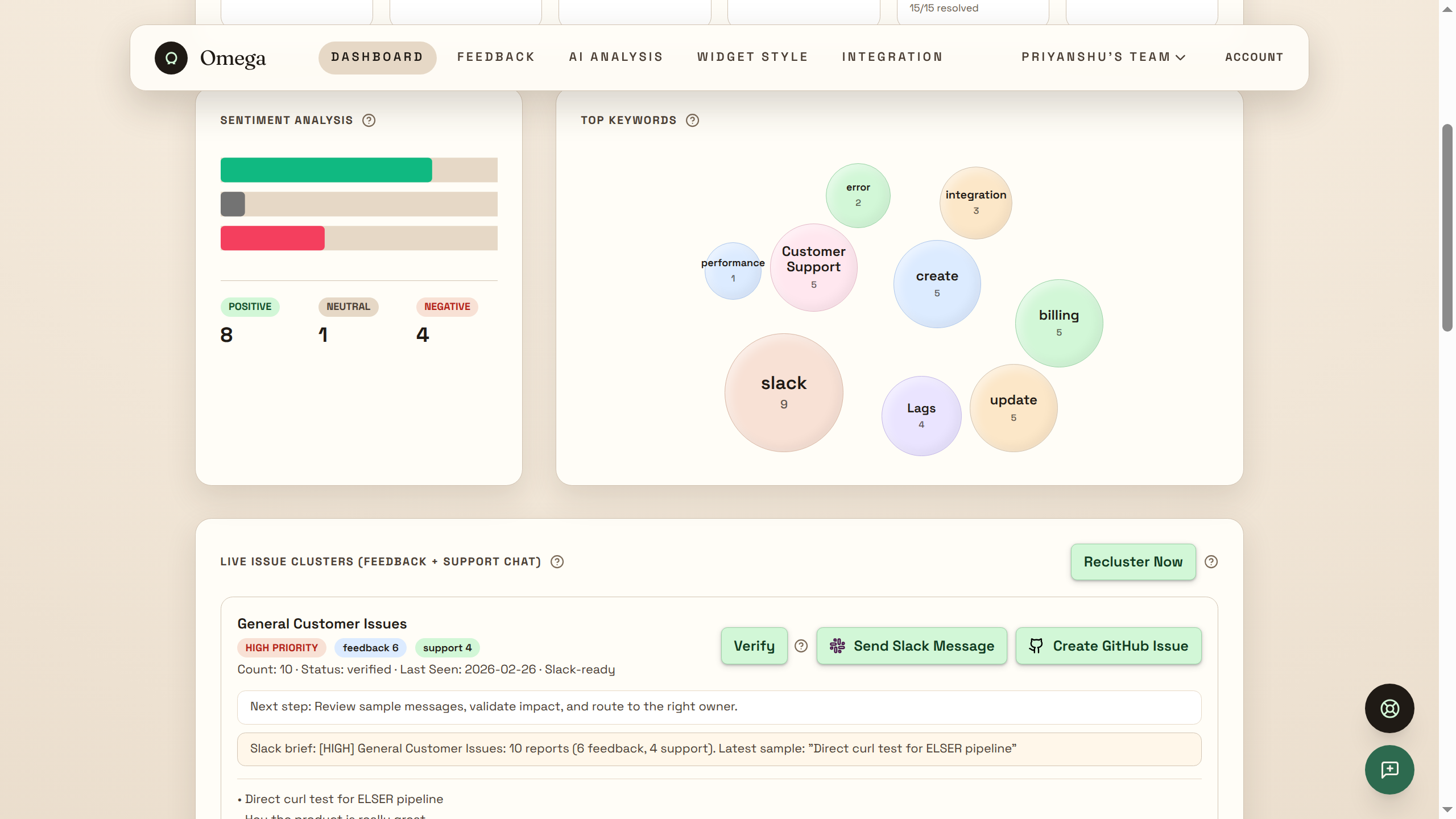
The admin dashboard visualizes real-time sentiment trends, complaint clusters, rating movement, and an urgent queue for unresolved negative feedback — all powered by ES|QL aggregation queries.
Admin AI Chat: 3 Specialized Agents
Product teams query feedback data in natural language. Omega auto-selects the right agent based on keywords:
| Agent | Trigger | Output |
|---|---|---|
omega_insights |
default | Evidence-backed analysis with counts, percentages, trend data |
omega_executive_brief |
"executive", "board", "ceo" | Stakeholder-ready summaries with quantified business impact |
omega_support_triage |
"urgent", "triage", "p0" | Unresolved negative feedback surfaced with remediation proposals |
All three share 6 custom ES|QL tools: omega_sentiment_trends, omega_low_rating_examples, omega_resolution_snapshot, omega_issue_buckets, omega_urgent_queue, omega_issue_clusters.
3 Automated Workflows
Sentiment Spike Workflow — cron every 5 minutes. The omega_sentiment_spike_analyzer agent compares last-hour metrics against a 1–24h baseline, reads recent complaints for root cause analysis, classifies severity (CRITICAL/HIGH/MEDIUM/LOW), and creates a ticket + Slack alert if warranted.
Smart Escalation Workflow — fires from Arya chat. Pulls conversation history and ticket stats via ES|QL tools, assigns P0–P3 priority, routes ticket to the correct team.
Knowledge Gap Workflow — the omega_knowledge_gap_detector agent finds conversations where Arya couldn't answer, clusters them with recent user queries, and recommends articles to write. Slack alert if 5+ gaps detected.
Architecture
Elasticsearch as the Complete Data Layer
All data lives across 8 indices: feedback, support_docs, support_conversations, support_tickets, issue_clusters, action_audit_log, teams, users. No secondary database.
Key features used:
- Hybrid search (BM25 + KNN) with RRF for support doc retrieval
- Ingest pipelines for auto-sentiment extraction and embedding generation at index time
- ES|QL for all analytics queries and all 15 custom agent tools
- Inference endpoints for vector embedding generation
Elastic Agent Builder: 7 Agents, 15 Custom ES|QL Tools
Agent instructions and tool bindings are managed through Agent Builder via the Kibana API. A sync script (npm run sync:agent-builder) pushes all definitions, keeping agent logic decoupled from application code.
| # | Agent | Role |
|---|---|---|
| 1 | Insights Agent | Analyzes feedback trends with evidence |
| 2 | Executive Brief Agent | Board-ready summaries with business impact |
| 3 | Support Triage Agent | Urgent item identification and triage |
| 4 | Customer Support Agent (Arya) | Grounded answers with inline citations |
| 5 | Sentiment Spike Analyzer | Detects and classifies negative sentiment spikes |
| 6 | Smart Escalation Agent | Conversation-aware ticket routing (P0–P3) |
| 7 | Knowledge Gap Detector | Finds documentation gaps from unanswered queries |
Arya's Search Pipeline
- User message received, language auto-detected
- Query translated to English if needed
- BM25 lexical + KNN vector searches fire in parallel on
support_docs - Results fused with RRF (k=60)
- Top sources deduplicated by
sourceId, passed as context toomega_customer_supportagent - Agent generates cited response; post-processed to remove internal jargon
- Confidence score computed (75% relevance + 25% source coverage)
- Response translated back to user's language
- If escalation conditions met, Smart Escalation workflow fires in background
Knowledge Ingestion
Web URLs are crawled, PDFs parsed with pdf-parse, content split into 1,200-character chunks with 150-character overlap, and indexed into support_docs with vector embeddings via Elastic inference endpoint.
Tech Stack
Next.js 14 · TypeScript · Elasticsearch 8.x · Elastic Agent Builder · ES|QL · NextAuth · React 18 · Tailwind CSS · Radix UI · Recharts · Framer Motion · Zustand
Challenges
Hybrid Search Tuning — Balancing BM25 and KNN with RRF required testing different k values and num_candidates settings. Too many candidates slowed queries; too few missed relevant results. Settled on k=60 after testing across diverse query patterns.
Agent Timeout Handling — Complex multi-turn questions occasionally exceeded Agent Builder response limits. Added a 9-second timeout with automatic fallback to the Elastic Completion API so users always get a response.
Citation Accuracy — Early agent versions generated citation numbers that didn't map to actual sources. Fixed by deduplicating sources by sourceId before passing context and adding strict citation rules to agent instructions.
Jargon in Responses — Arya would say things like "based on the indexed documents." Added post-processing regex cleanup and explicit instruction rules to keep the tone natural.
Ingest Pipeline Resilience — If the sentiment analysis pipeline failed (inference endpoint temporarily unavailable), feedback submissions broke entirely. Added fallback logic to index feedback without sentiment/embeddings rather than blocking the submission.
What We Learned
Agent Builder makes multi-agent systems practical. Defining agents with scoped instructions and binding them to custom ES|QL tools through the Kibana API keeps agent logic and application logic cleanly separated. Changing agent behavior is a config push, not a code deploy.
ES|QL works well as agent tooling. Parameterized ES|QL queries give agents structured access to Elasticsearch data without raw DSL. Agents can pull sentiment trends, urgent queues, conversation history, and baseline metrics through clean, typed queries.
Hybrid search with RRF is worth the complexity. Combining lexical and semantic search with rank fusion consistently improved retrieval quality — especially important for customer support, where users phrase the same question in wildly different ways.
Fallback chains are essential. Agent timeouts, inference failures, and translation errors all happen in production. Graceful fallbacks at every stage (Agent Builder → Completion API, Elastic inference → OpenAI, failed sentiment → raw indexing) keep the system reliable.
What's Next
- Streaming responses via Server-Sent Events for real-time chat feel
- Answer feedback loop: thumbs-up/down on Arya's responses to improve retrieval quality over time
- Proactive support: use complaint clusters and sentiment trends to trigger outreach before customers escalate
- Multi-tenant deployment with team-scoped indices and role-based access
Built With
- agent-builder
- elastic
- next.js
- typescript
- vector-search


Log in or sign up for Devpost to join the conversation.