-
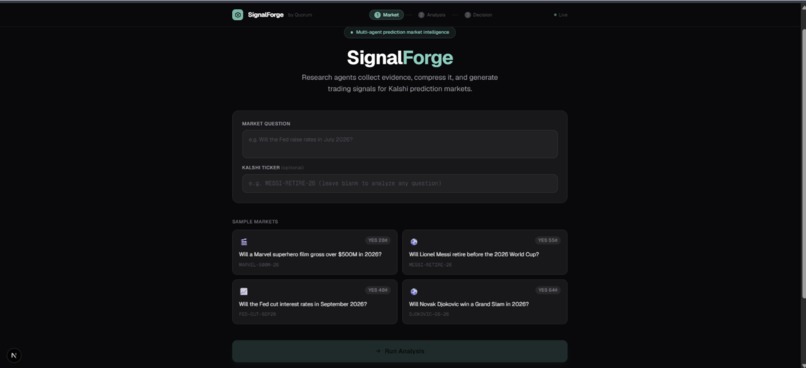
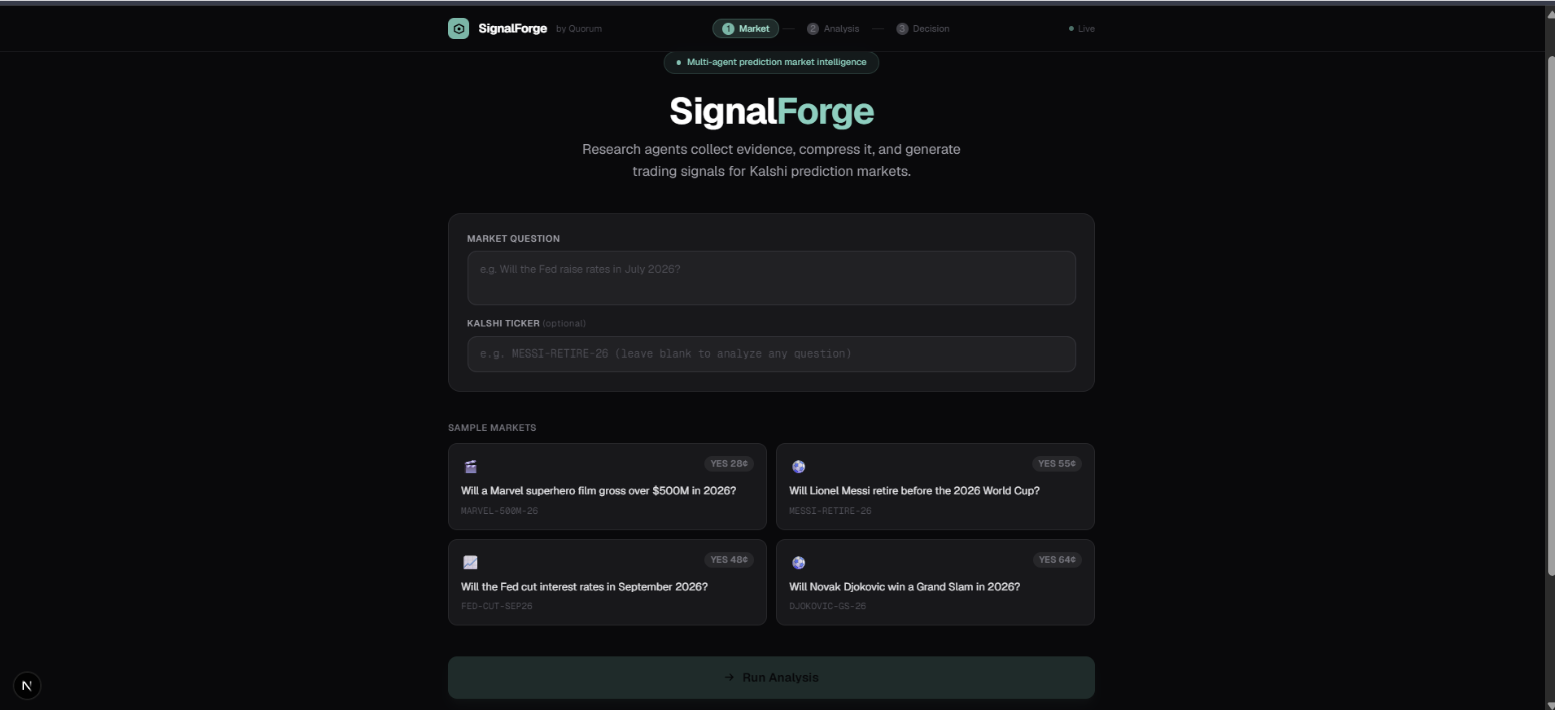
Landing page. Enter any prediction market question. SignalForge auto-routes to the right evidence agent and runs the full analysis pipeline.
-
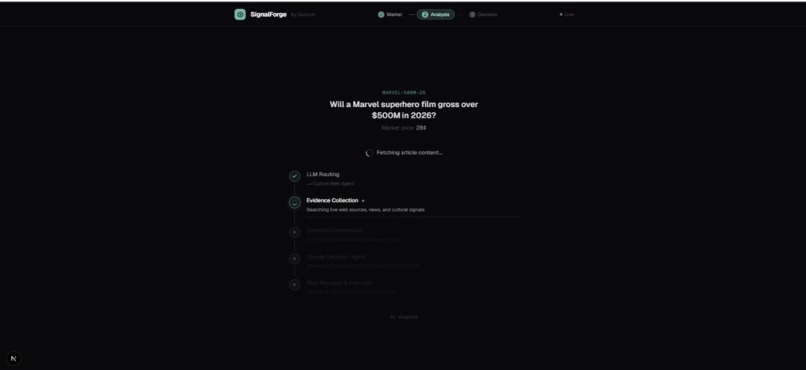
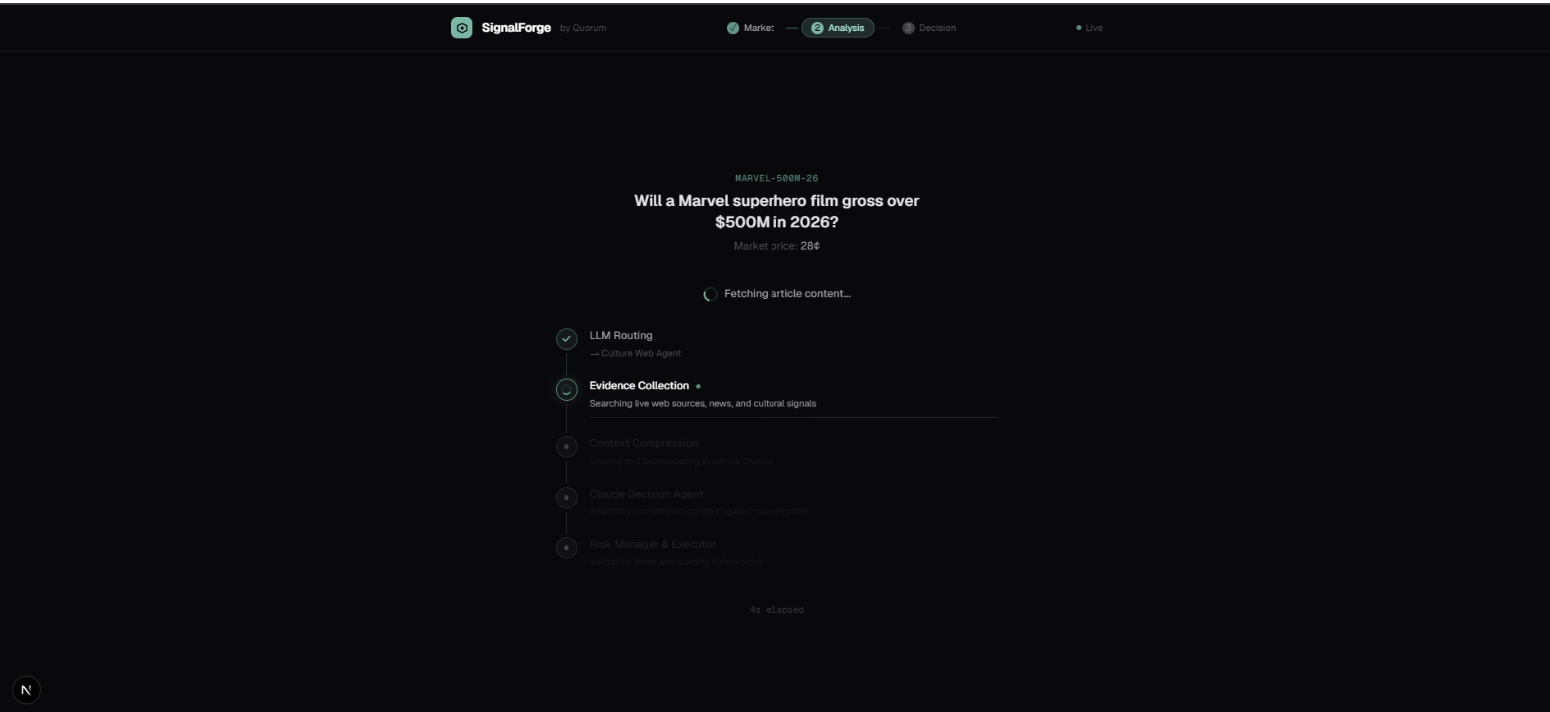
Live pipeline. Real-time pipeline view: LLM routing selects Culture Web Agent, evidence collection begins, elapsed timer counts up.
-
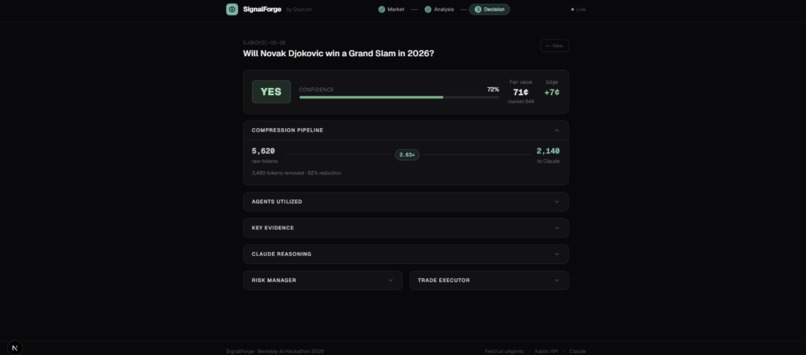
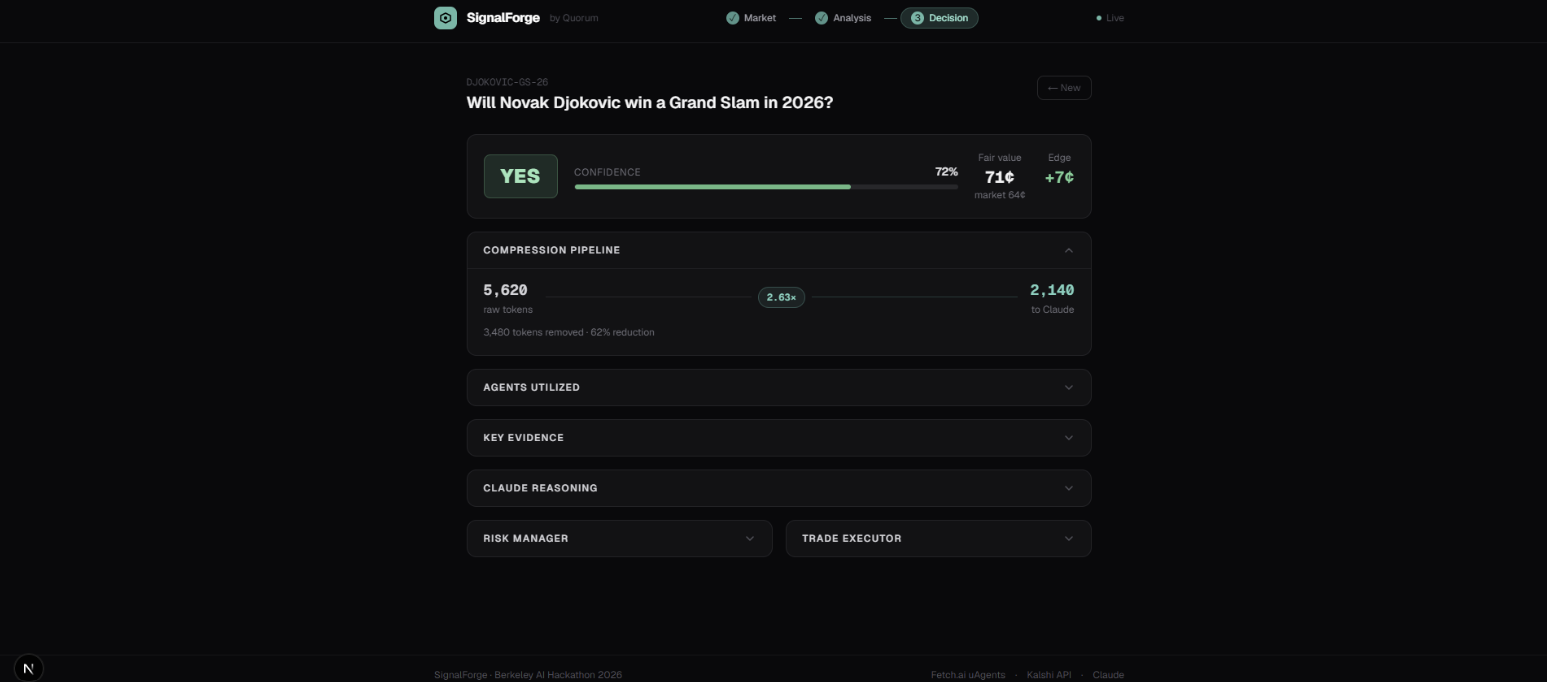
Results: Djokovic YES 72%. YES at 72% confidence, +7¢ edge. 5,620 raw tokens compressed to 2,140 before Claude
-
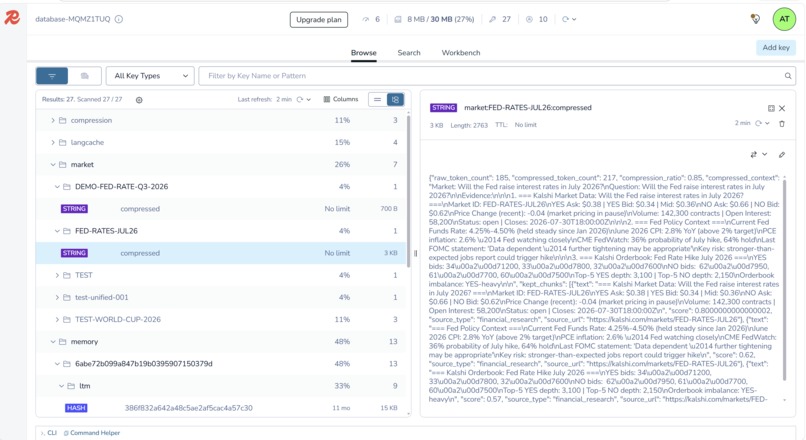
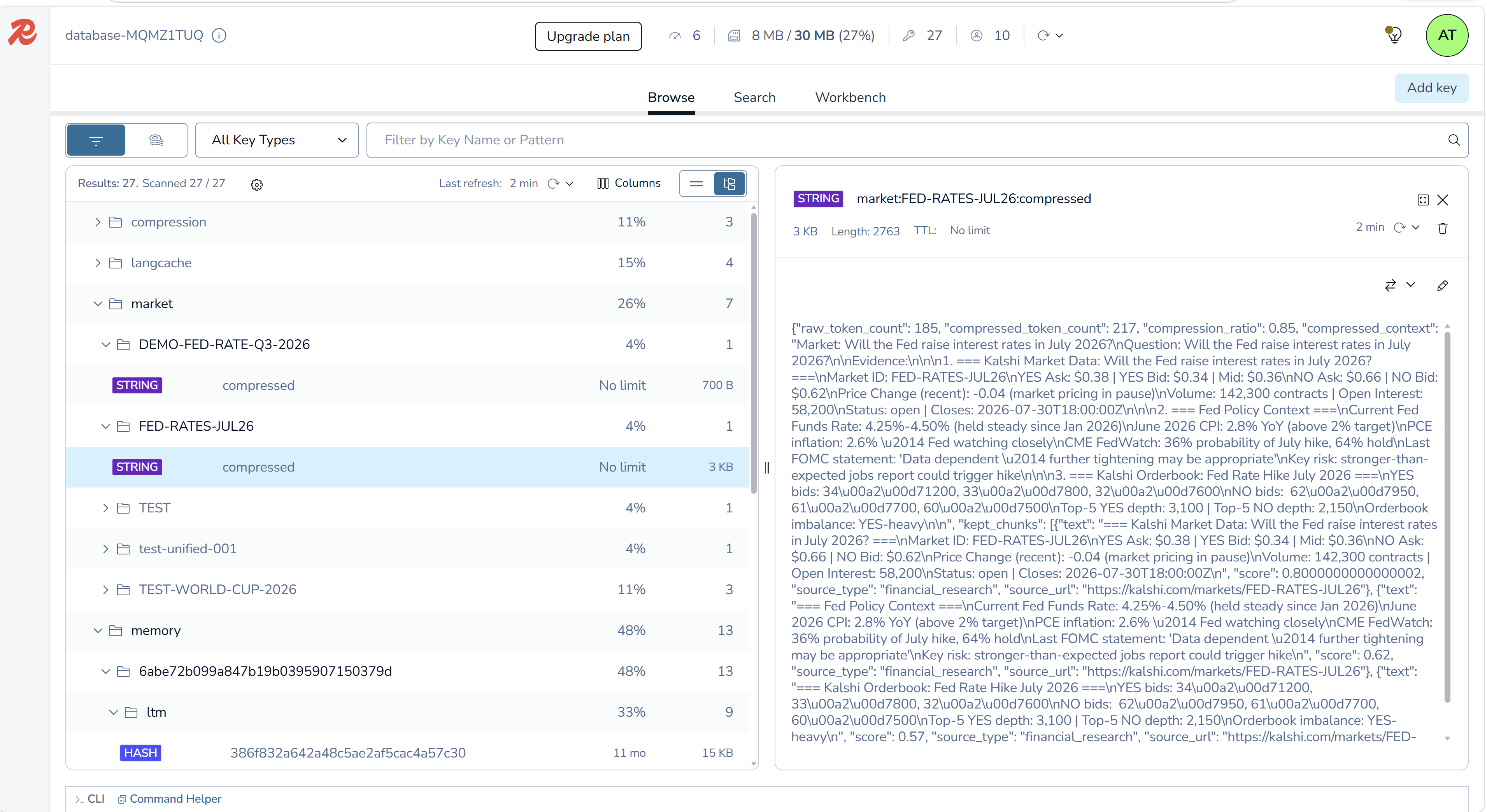
Redis Insight, on repeated questions, the compression step is skipped entirely, cache HIT returns in milliseconds instead of seconds.
-

Fetch.ai Agentverse: orchestrator + sports agent
-
Fetch.ai Agentverse: culture + financial agents
-
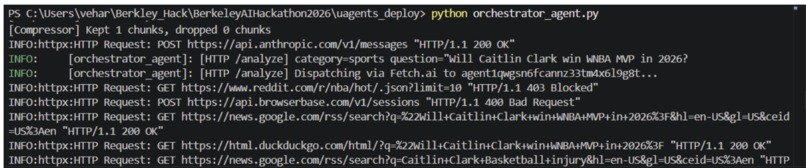
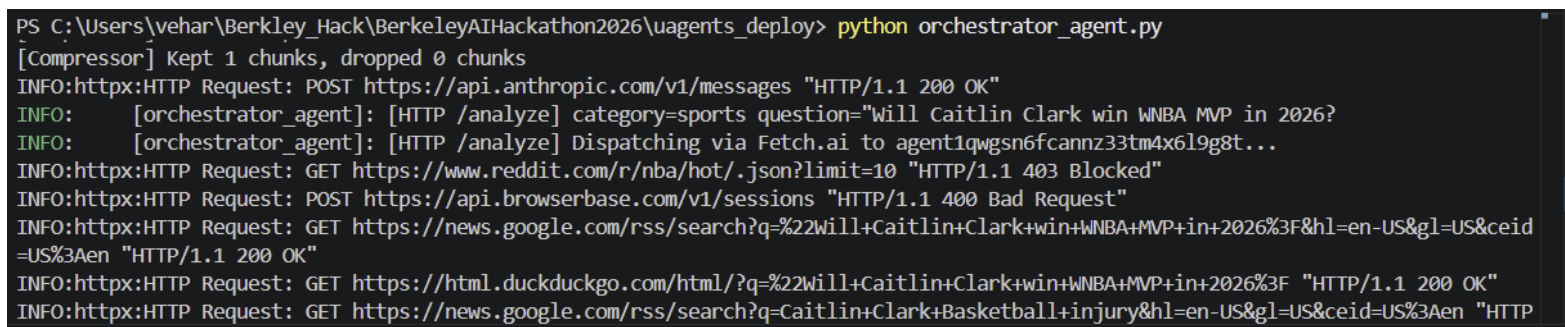
Orchestrator Agent Example - “Will Caitlin Clark win WNBA MVP in 2026?” - category=sports
Inspiration
Prediction markets like Kalshi and Polymarket are supposed to reward people who can find the truth faster than the crowd. But in reality, most traders are still jumping between Twitter, injury reports, earnings calls, polling dashboards, box office trackers, and random Reddit threads trying to decide whether a market is mispriced.
The problem is not that the information does not exist. The problem is that the information is scattered, noisy, and moves faster than humans can reasonably process. A single player injury, trailer delay, court ruling, or earnings quote can completely change a market before most people even know it happened.
We wanted to build the research analyst that never sleeps: a multi-agent AI system that can monitor live information, compress the noise into decision-relevant evidence, and give users a transparent recommendation they can inspect before acting.
What it does
SignalForge is a multi-agent AI research copilot for prediction markets.
A user submits a market question like:
- "Will Portugal win the 2026 World Cup?"
- "Will GTA 6 release before 2027?"
- "Will this company beat earnings expectations?"
From there, a network of specialized AI agents fans out across the web to gather evidence from relevant sources. Sports agents look for injuries, rosters, odds movement, and recent performance. Culture agents track box office numbers, release timelines, and entertainment news. Finance agents look at earnings calls, market news, and company signals. Political agents can monitor polling, policy updates, and election-related news.
Instead of dumping hundreds of noisy links into an LLM, SignalForge passes the raw evidence through a compression engine that ranks, deduplicates, and trims the information down to the highest-signal facts. Claude then reasons over the compressed research brief and returns a structured recommendation:
- YES
- NO
- HOLD
Each recommendation includes a confidence score, supporting evidence, reasoning, and what could change the decision.
We also built an event watcher that monitors live news feeds and automatically triggers the research pipeline when important events occur, such as a player injury, release delay, elimination, or breaking headline. Every recommendation is logged to a dry-run Kalshi-style paper trading ledger with timestamp, confidence, trigger event, supporting evidence, and decision rationale.
SignalForge is not meant to blindly place bets for users. It is a transparent, human-in-the-loop research system that helps users understand why a market may be moving and whether the evidence supports action.
How we built it
We built SignalForge as a modular multi-agent system using Fetch.ai's uAgents framework and deployed the agents through Agentverse.
The system has four main layers:
OrchestratorAgent
The OrchestratorAgent receives the user's market question, identifies the relevant domain, launches the correct evidence agents, and coordinates the full research pipeline.
Evidence Agents
We built specialized agents for sports, culture, politics, and finance. Each agent collects raw evidence in parallel and returns structured evidence chunks with a source, timestamp, relevance score, and extracted claims.
CompressionAgent
The CompressionAgent is the core technical layer. It scores evidence using relevance, source strength, protected keywords, information density, and duplicate similarity. It then applies Jaccard deduplication and trims the evidence into a compact research brief. Redis caching makes repeated or similar queries much faster.
DecisionAgent
The DecisionAgent uses Claude to read the compressed brief and output a structured YES / NO / HOLD recommendation with confidence, reasoning, counterarguments, and trigger conditions that would change the recommendation.
All agent messages are typed with Pydantic schemas so each step of the system has clear inputs and outputs. Recommendations are stored in a dry-run trade ledger so users can audit the full chain from headline to evidence to final recommendation.
Challenges we ran into
The hardest challenge was not getting an LLM to answer a question. The hard part was deciding what information deserved to reach the LLM in the first place.
Prediction market questions can generate hundreds of evidence chunks, many of which are repetitive, outdated, low-signal, or only loosely related to the actual market. If we simply summarized everything, the model could miss the few facts that actually mattered. We had to build compression as a ranking problem, not just a summarization problem.
Our CompressionAgent scores each evidence chunk before trimming. It weights source quality, relevance to the market question, protected terms, recency, and information density. Then it removes near-duplicates with Jaccard similarity. This let us reduce the context by about 8x while preserving the most decision-relevant information.
Another major challenge was coordinating asynchronous agent communication through Agentverse mailboxes. Evidence agents return at different times, but compression should only start after the necessary responses are collected. We built an async aggregation barrier so the orchestrator can wait for parallel evidence responses before moving to the next step.
Accomplishments that we're proud of
We are proud of getting a real multi-agent research pipeline working end to end in a hackathon timeframe.
The biggest technical accomplishment was the compression engine. We reduced large evidence payloads by roughly 8x while preserving the facts that changed the final recommendation. We tested this by comparing Claude's outputs with and without compression on the same market questions.
We are also proud of the event watcher, which turns SignalForge from a passive search tool into an active monitoring system. Instead of waiting for the user to ask a question, the system can detect a breaking headline and automatically trigger the research pipeline.
Finally, we built a dry-run Kalshi-style ledger that logs every recommendation with timestamp, trigger, confidence, supporting evidence, and reasoning. That gives users an audit trail instead of a black-box answer.
What we learned
We learned that multi-agent systems are only as strong as their protocols. Giving every message a strict Pydantic schema made the system much easier to debug and prevented agents from passing vague or inconsistent outputs to each other.
We also learned that compression is not the same thing as summarization. In fast-moving markets, the edge is often hidden inside one or two critical facts. If the system compresses blindly, it can remove the exact signal that matters. Ranking before summarizing was one of the most important design choices we made.
We also learned that speed matters. Redis was not just a convenience cache; it made the system feel usable in a market setting where stale information loses value quickly.
What's next for SignalForge
Next, we want to replace placeholder evidence sources with live, domain-specific data feeds for sports, finance, culture, and politics. We also want to connect more deeply with Kalshi's API for real market metadata while keeping the system human-in-the-loop.
We plan to add an agent reputation layer that tracks how often each evidence agent's signals actually predict market outcomes. Over time, the system could learn which sources and agents deserve more weight for different market categories.
Long term, SignalForge could become a continuously running prediction market research desk: monitoring open markets, detecting important events, generating compressed evidence briefs, and helping users make faster, more transparent decisions without drowning in noise.
Built With
- agentverse
- claudeapi
- fetch.ai
- kalshiapi
- pydantic
- python

Log in or sign up for Devpost to join the conversation.