
Inspiration & Motivation & Function
Zoom meetings can often feel boring and uninspired. As a team we wanted to find a way to react to content silently with more than just a little pop-up in the corner of your screen. OK Zoomer allows users to use one of four preset hand gestures to express exactly how they're feeling with camera feed app that can be routed to any streaming application. Ok Zoomer also wanted to take things a step further with live image stylization. Although current functionality is limited, OK Zoomer can morph any foreground person or background (including custom elements uploaded into the app) into a multitude of artistic styles that may spice up any feed with a simple click of a button!
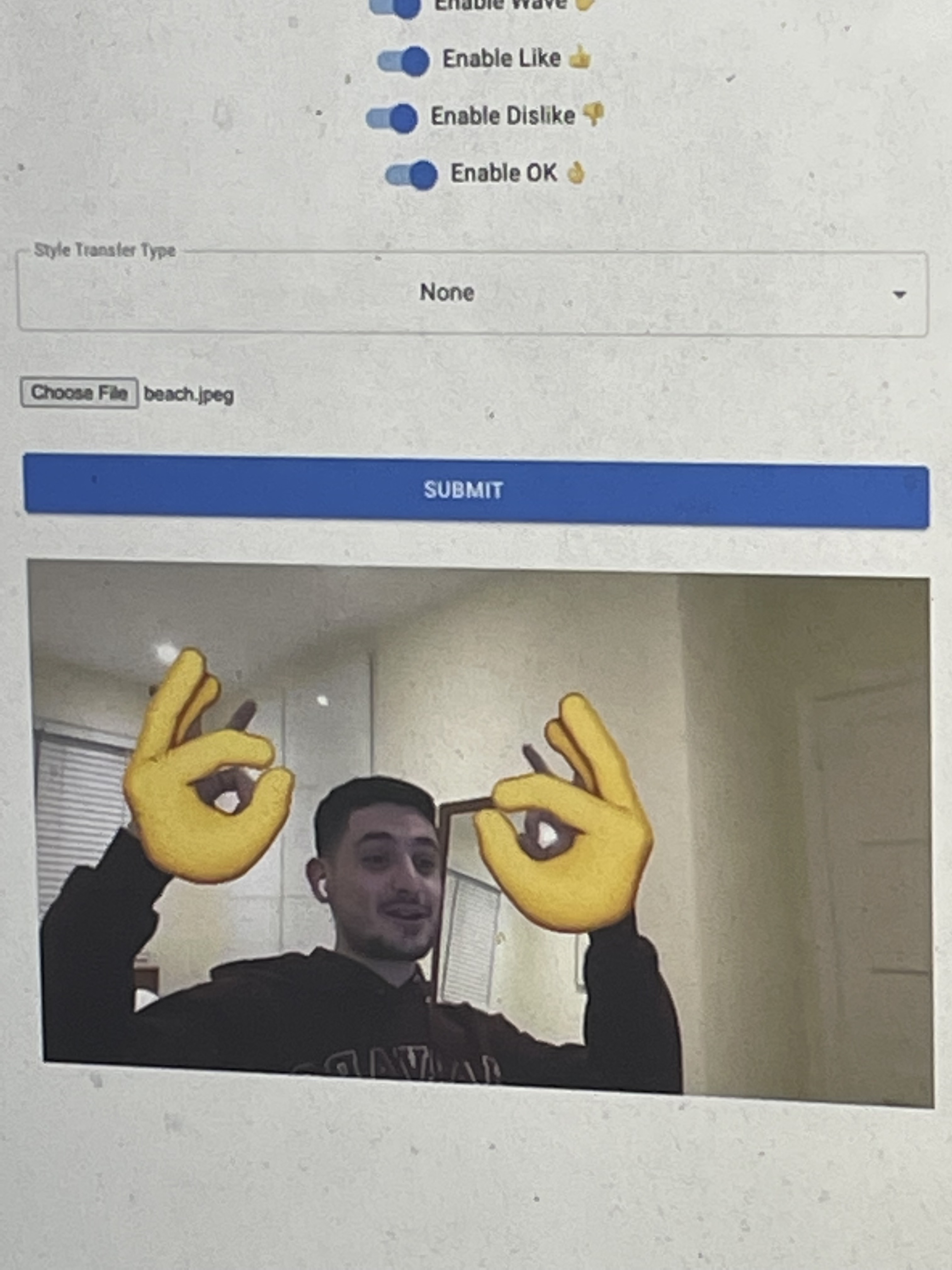
Emoji overlay
Emotion can be expressed in its simplest form... emojis. OK Zoomer is equipped to handle four necessary options which include (👍, 👎, 👌, ✋). We find your hand, figure out the gesture, and wow, you now have an oversized emoji glaringly expressing how you feel!
Greenscreening and Neural Style Transfer
We allow users to at flair to their feeds! This is accomplished using some "Neural Style Transfer" that we can apply directly to the foreground person or background. We let the use freely upload any kind of background and at the flick of a switch, you've become a beautiful painting.
How we built it
Frontend
The platform was built using a client-server architecture. The client is a webapp that makes requests to an intermediate Flask client-side server. The webapp was developed with ReactJS and MaterialUI (mui) for modern and efficient styling. This server makes use of OpenCV to capture the live device webcam stream, and sends the processed frames it receives to the webapp which renders them.
Backend
The backend is also built using a Flask server. It is hosted on McGill computers to leverage the compute resources. The frontend makes HTTP requests to a backend endpoint with the image data of the stream's frame. The server inputs the frame to the model, and then responds with the processed frame returned by the model controller. The frontend server then takes care of forwarding the frame to the client-side webapp in order to ultimately render it in the viewport. There are also routes to upload the selected background image and gesture recognition settings from the webapp to customize the model behavior and output.
Dataset
We use an open source tool based on mediapipe to register hand gesture keypoints to a selected class. We spent countless hours (or minutes, you decide) generating classes for 9 total classes (4 right hand emojis, 4 left hand emojis, and one other class). In total, we help up our hands infront of a camera for a whopping 6k images used to train our little gesture classifier!
Deep Learning
We use Mediapipe for keypoint extraction and train a simple two layer MLP for gesture classification. We then approximate centroids of the hands with a bounding box extraction provided by the extraction tool. We can compute where the emojis should be mapped and can use fast fast masking operations to fix them in all in real time (20+ fps)! We also make sure things won't be break so we make sure everything stays in frame and make the emojis 'sticky' so they don't fade away if the classifier fails on an edge case.
We use a segmentation neural network (YOLACT) with a resnet-50 backbone to perform instance segmentation (person / background) using pretrained weights learned on COCO. We also bust out pytorch's fast neural style transfer equipped with a few modes. We stitch everything together with a little blending stack and there you go!
Challenges we ran into
Training dataset for pose estimation
Datasets are hard to find! I don't know whose the last person that said "find something on kaggle" but let me tell you, the quality was not there. We spend a good half of the hackathon getting openpose together (Caffe) only to find out that the keypoints provided weren't correlated with the reference model output. We were then forced to swap to mediapipe and had to down the rabbit-hole of gathering data.
Local compute resources
A big goal of this project was to deliver an end product that could feasibly target the average consumer PC and push normal fps. This was accomplished with a lightweight version of the emoji mapper but CPU neural network processing was too slow. To handle this we had to offshoot our processing to a computer locked down with too much security and had to hack things together. Although our framerates were down for NST, we were still able to produce understandable results. Although most video-conference applications are nowadays built with a centralized server that mediates the connection (rather than peer to peer. For the purposes of this hackathon, we hacked a two-way HTTP connection to handlimage transfers to get to GPUs and push a usable fps rate :)
Accomplishments that we’re proud of
- Everything!
- Building our very own datasets to train with
- We built a webappp that enables users to control how their video looks to others, including toggling their favourite real-time hand gesture-mapped emojis as well as choosing which type of Neural Style Transfer individually for their background and themselves as a subject
- We were able to capture a live webcam stream on the frontend's client-side backend server and route it forward to our user-facing React webapp, which was not how we initially planned things.
- Our team managed to set up a consistent and reliable stream of frames from our local machines to a remote server with large computing resources and return a processed frame in near real-time
What we learned
We learned so many things
What's next for Ok Zoomer
- JOJOGAN + ARCANEGAN + One-shot learners
- Low latency and smaller lightweight in-house models
- Different protocol for bi-directional video stream pipeline between client and server
- Custom stylization
- Custom emoji mapping
- More data










Log in or sign up for Devpost to join the conversation.