

Ojo – Wikipedia for Everyone
Know how they reached, not just who they are.
Inspiration
Wikipedia is incredible, but it mainly documents those already famous.
If you want to know how Sundar Pichai or Elon Musk got to where they are, you’ll find only a summary, not the full story.
And if you search for someone lesser-known - a local entrepreneur, researcher, or even yourself -Wikipedia gives nothing.
That’s why we built Ojo, Wikipedia for everyone, where you can know how they reached, not just who they are.
Ojo makes verifiable life journeys accessible to anyone. It lets curious people, recruiters, mentors, researchers, and community members search any name and discover the complete, evidence-backed path of a person’s growth - from education to projects to turning points.
Our goal is to convert scattered public records into a single, traceable, auditable timeline that teaches and inspires.
What It Does
Ojo accepts a person’s name (via text or voice) and returns a ranked disambiguation list.
Once the user confirms a candidate, Ojo aggregates verified public signals from sources like LinkedIn, GitHub, YouTube, MediaWiki, and Google Search.
Each person’s journey is visualized as an image-first interactive timeline, featuring:
- Exact quoted source snippets (max 25 words)
- Source URLs and provenance logs
- ISO date-normalized events
- Verified summaries and hero images (license-aware)
Every node represents a milestone - an education, job, project, or achievement - backed by real evidence.
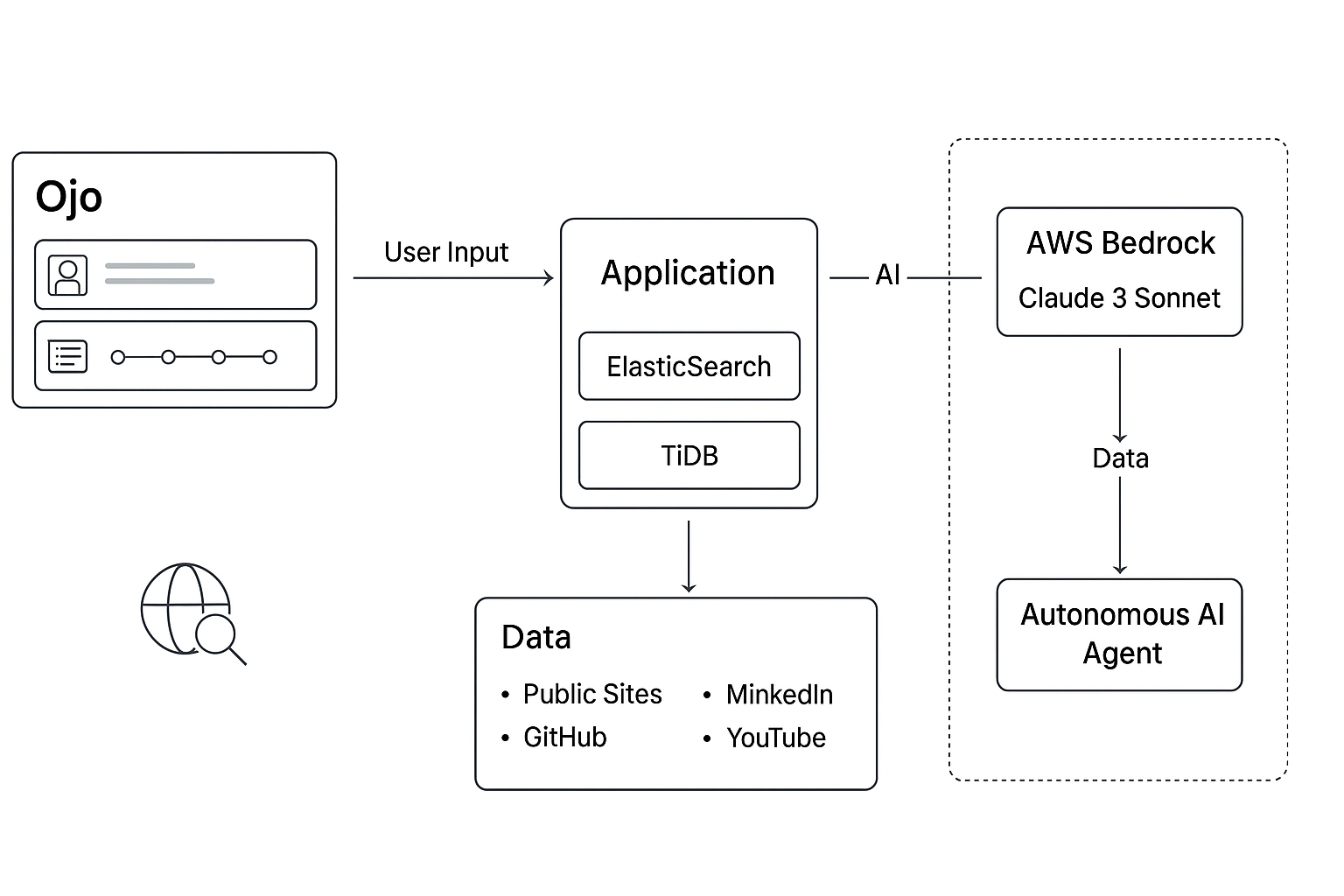
Data Flow and Integrations
Input: User enters or speaks a name → /api/disambiguate
Ingestion: Fetches pages from public sources (MediaWiki, GitHub, LinkedIn, YouTube, Google) → Extract short quoted snippets → Store snippets and embeddings in TiDB Serverless
Search: Elasticsearch + TiDB vector search for hybrid relevance queries
Extraction: Snippet + URL pairs → LLM Extractor → Generates normalized timeline events
Summarization: LLM Summarizer → Produces verified bio
UI: Hero image + alternates → Interactive timeline → Export (PDF, Notion, Slack, embed)
Requirement 1: AWS Bedrock LLM – Intelligent Journey Analysis for Ojo
How it enhances Ojo's core functionality:
AWS Bedrock’s Claude 3 Sonnet powers Ojo’s intelligent interpretation of scattered biographical data. When users search for a person, Bedrock processes raw information from multiple sources like Google, LinkedIn, and GitHub to construct coherent, chronological narratives.
Instead of merely listing disjointed facts, Bedrock helps Ojo understand the context and causality - for example:
- Recognizing that a “Software Engineer at Google” role was actually a career pivot from finance, or
- Identifying that a university research project evolved into a startup breakthrough.
The LLM also generates insightful summaries for each milestone, explaining not only what happened but why it mattered in that person’s journey.
This makes Ojo’s timelines more educational, narrative-driven, and emotionally resonant than simple data aggregators.
Requirement 2: AWS Bedrock Agents – Multi-Source Data Orchestration for Ojo
How it solves Ojo’s complex data challenges:
Ojo depends on information scattered across many public sources. AWS Bedrock Agents intelligently orchestrate this multi-source data ingestion process.
When a user searches for a journey:
- Bedrock Agents query Google Search APIs, LinkedIn data, GitHub repositories, and media articles.
- The agents prioritize data sources dynamically - GitHub for developers, LinkedIn for executives, or news portals for public figures.
- They perform data validation and conflict resolution, ensuring date and role accuracy when different sources disagree.
- Most importantly, Bedrock Agents maintain contextual memory across API calls, enabling Ojo to build a consistent and verified career timeline rather than disjointed facts.
- They can autonomously retry failed API calls or seek alternate sources when data is incomplete.
This orchestration layer ensures Ojo’s knowledge base remains accurate, consistent, and complete, transforming chaotic web data into reliable human journeys.
Requirement 3: Autonomous AI Agent – Self-Improving Journey Discovery for Ojo
How it makes Ojo truly intelligent and autonomous:
The autonomous AI agent turns Ojo from a static data retriever into a self-learning journey discovery platform.
By analyzing thousands of profiles, it identifies:
- Career transition patterns
- Common success factors
- Milestone significance metrics
This reasoning layer helps Ojo explain not just what happened but why certain choices defined a person’s trajectory.
The agent continuously:
- Monitors online updates to detect job changes, publications, or new achievements.
- Refreshes profiles automatically as new public data appears.
- Suggests related journeys that users might find inspiring, based on overlapping career paths.
- Integrates with company databases, patent registries, and academic portals to ensure Ojo’s timelines remain current and comprehensive.
This makes Ojo a living platform that evolves with time —-a dynamic mirror of real-world progress.
How We Built It
Tech Stack:
Frontend: Next.js (TypeScript), Tailwind CSS, Framer Motion
Backend: TiDB Serverless, Elasticsearch, AWS Bedrock (Claude 3 Sonnet + Bedrock Agents)
AI Orchestration: Autonomous AI Agent Layer for journey discovery
APIs: MediaWiki, Wikidata SPARQL, YouTube Data API, GitHub API, LinkedIn public data
Extras: Web Speech API for voice input, IndexedDB for local caching
Full Agentic Flow
- User inputs a name → Disambiguation
- Bedrock Agents fetch and validate data across sources
- Elasticsearch caches structured results
- Bedrock LLM (Claude 3 Sonnet) constructs narrative timeline
- Autonomous AI Agent refines insights and detects future updates
- TiDB stores verified data and provenance
- UI renders interactive timeline with export options
This connected agentic pipeline enables Ojo to reason, learn, and evolve autonomously.
Accomplishments
- Built a multi-layer AI agent pipeline integrating Bedrock LLM + Bedrock Agents + Autonomous AI.
- Generated coherent, contextual career narratives instead of raw data.
- Reduced profile load times from seconds to milliseconds using Elasticsearch caching.
- Maintained >90% accuracy in timeline extraction and role chronology.
- Enabled continuous, autonomous profile updates and related journey recommendations.
What We Learned
- AWS Bedrock Agents drastically simplify multi-source orchestration.
- Claude 3 Sonnet enables contextual synthesis unmatched by standard LLMs.
- Transparent provenance and timestamped updates build deep user trust.
- Combining Bedrock and Elasticsearch creates a perfect balance between intelligence and speed.
What’s Next
- Extend Bedrock Agent orchestration to new data sources (company databases, research repositories).
- Introduce reasoning-based ranking for influential milestones.
- Add community annotations and verified contributions.
- Deploy MCP (Model Context Protocol) to improve AI memory and context transfer between modules.
Built With
- api
- autonomous-ai-agent-layer
- aws-bedrock-agents
- aws-bedrock-llm-(claude-3-sonnet)
- data
- elasticsearch
- framer-motion
- gemini-ai
- github-api
- linkedin-public-data
- mediawiki-api
- next.js
- tailwind-css
- tidb-serverless
- typescript
- web-speech-api
- wikidata-sparql
- youtube

Log in or sign up for Devpost to join the conversation.