

ojo
ojo is wikipedia for everyone where you can search any name and see verified details. Ojo aggregates public signals and displays them as an image first interactive timeline with exact quoted source snippets for full provenance.
TIDB Cloud account email: satyapoojith4@gmail.com
Repositry: https://github.com/surya4419/ojo-
Demo Link: https://ojo-sxv3.onrender.com/
Youtube Link:https://youtu.be/s_6_bNRGFPQ?si=WsJF9yIOmbi0DjOq
Inspiration
Wikipedia is an incredible public resource yet it covers mainly well known figures. We built Ojo to change that by making verifiable life journeys available for anyone. The core idea is to let curious people, recruiters, mentors, researchers and community members search any name and discover how someone reached a role or domain through evidence that can be audited. The goal was to convert scattered public records into a single, traceable narrative that teaches and inspires.
What it does
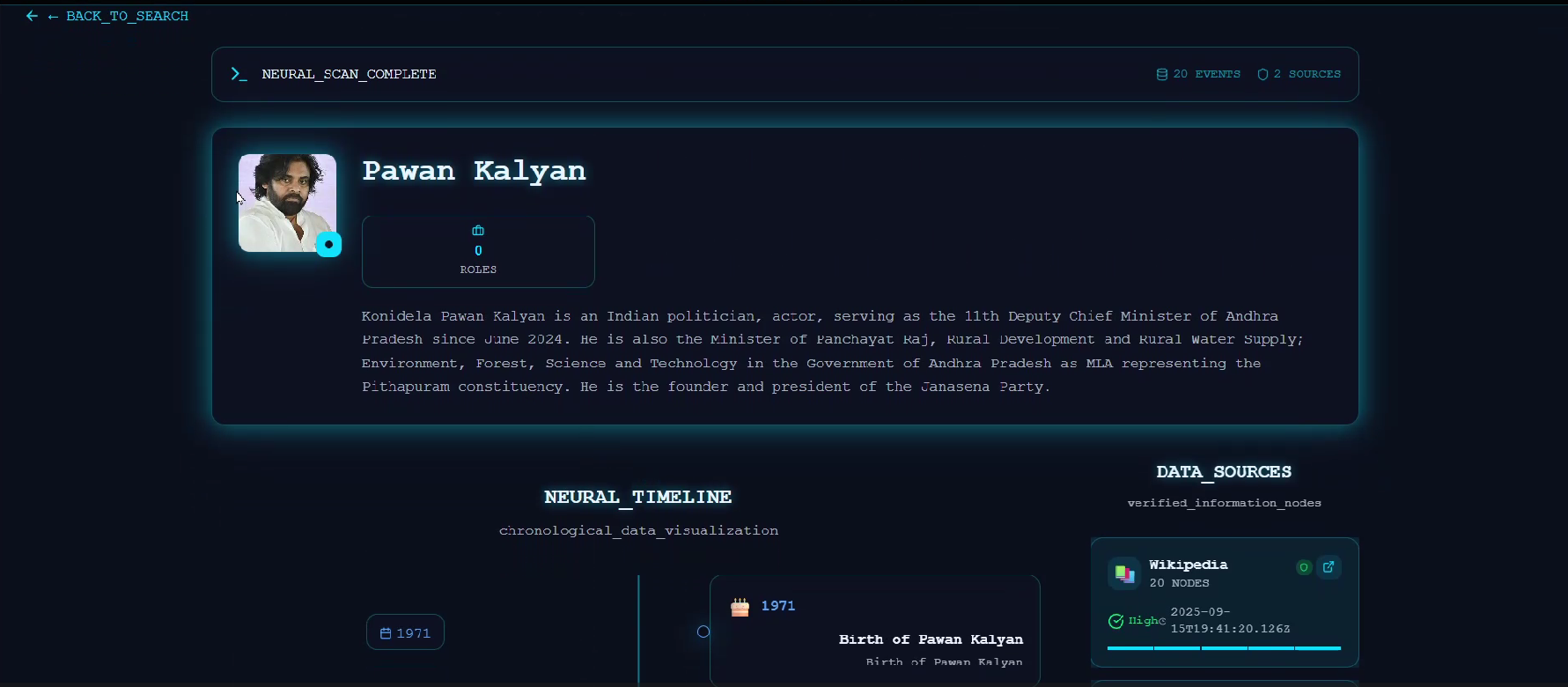
Ojo accepts a person's name as text or voice and returns a ranked disambiguation list. After the user confirms a candidate, Ojo fetches public sources in parallel and stores short quoted snippets and embeddings in TiDB Serverless. Ojo uses vector search and full-text search on TiDB to find relevant snippets. A strict extractor LLM is fed only exact quoted snippets and their URLs and produces date-normalized timeline events. Each timeline node includes ISO date information, a concise description, categories, and at least one source URL plus an exact quoted snippet of no more than twenty-five words. Ojo shows a hero image plus three alternates with license metadata, a one to three-sentence verified summary with citations, and a provenance log that records fetch times and confidence calculation strings.
How we built it
Tech stack and structure
Next.js with TypeScript for frontend and serverless API routes. Tailwind CSS and Framer Motion for the glassmorphic dark hacker style UI. TiDB Serverless on TiDB Cloud for document storage and vector index search. Hosted LLM APIs for the extractor and optional summarizer. MediaWiki API, Wikidata SPARQL, and search APIs for primary discovery. YouTube Data API, public GitHub, and publicly visible LinkedIn pages for additional signals. IndexedDB for local cache.
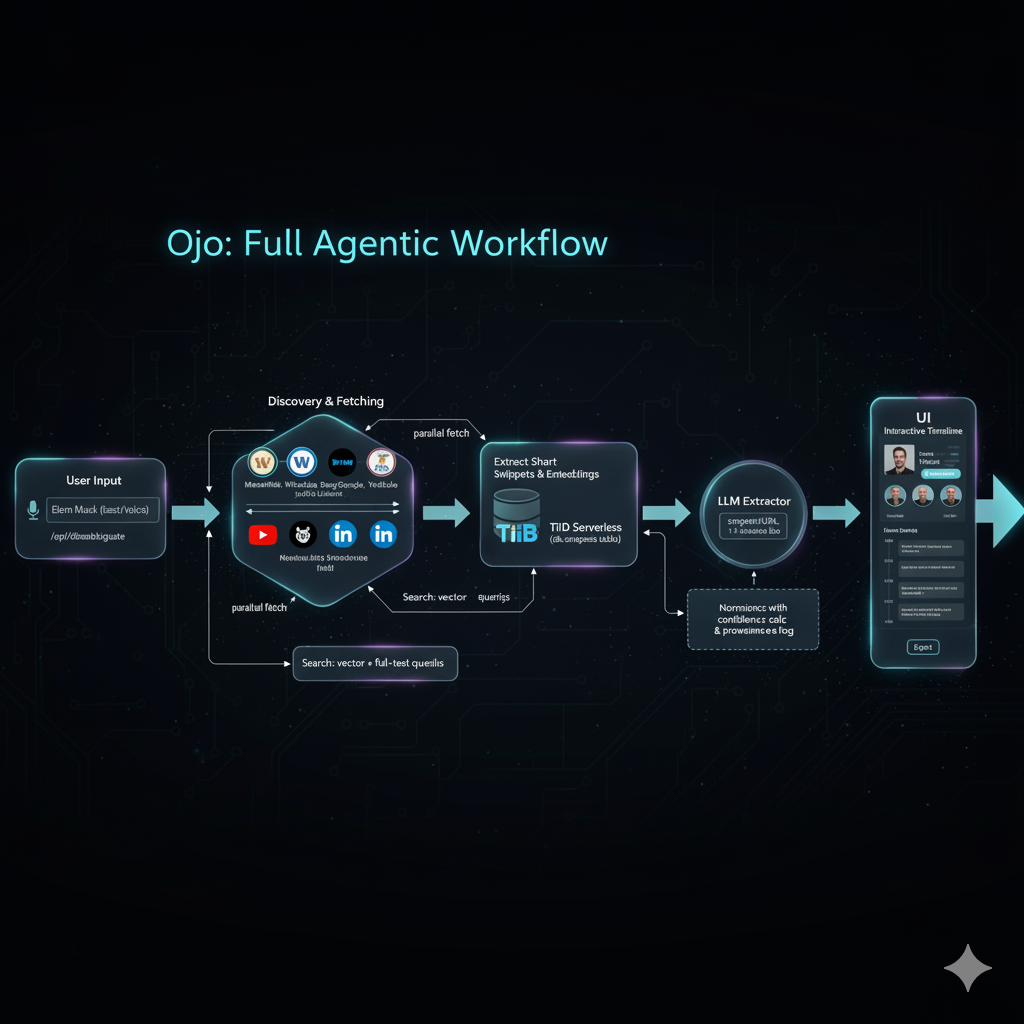
Data flow & integrations (concise)
http://googleusercontent.com/image_generation_content/2
- Input: User input (text/voice) →
/api/disambiguate. - Ingestion: Discover & fetch pages (MediaWiki, Wikidata, Bing/Google, YouTube, GitHub, public LinkedIn) in parallel → Extract short quoted snippets → Insert raw snippets + embeddings into TiDB Serverless (
db.snippetstable). - Search: Vector + full-text queries on TiDB Serverless to find relevant snippets.
- Extraction: Pass only snippet+URL pairs to an LLM Extractor → Normalized timeline events are returned → Store events with confidence calculation &
provenance_log. - Summarization (Optional): A Summarizer LLM creates a 1–3 sentence bio using only verified events/snippets.
- UI: Render hero image + alternates, interactive timeline, and export features.
Key components and mapping to hackathon building blocks
Ingest and index data A serverless ingestion worker fetches discovered pages, extracts short quoted snippets, and creates vector embeddings which are upserted into TiDB Serverless.
Search your data A search endpoint queries TiDB Serverless using vector nearest neighbor search and full-text queries to retrieve the highest relevance snippets.
Chain LLM calls The orchestrator sends only snippet plus URL pairs to the extractor LLM which returns normalized timeline events. An optional summarizer LLM composes the short verified biography using only high-confidence events and their snippets.
Invoke external tools Voice capture uses the Web Speech API for STT. Image licensing checks contact Wikimedia or official image sources. PDF export generates downloadable snapshots.
Full agentic flow User input leads to disambiguation. After confirmation, the system ingests and indexes sources in TiDB. Search retrieves relevant snippets. The extractor LLM parses only the quoted snippets into events. The pipeline stores events with confidence calculations and renders the final UI including export and share features. This chain satisfies the hackathon requirement to connect multiple building blocks in a single automated workflow.
Challenges we ran into
Ambiguous names created many candidate matches, so we implemented ranking that combines name similarity, role, and source authority. Diverse APIs have varying rate limits, so we added concurrency limits, exponential backoff with jitter, and caching in TiDB for 24 to 72 hours. LLM hallucination risk required a snippet-first extractor design where the LLM may not invent facts. Image licensing is varied, so we mark social images as "limited license" and require user confirmation before display. LinkedIn and some profiles are gated, so we use only publicly visible data and redact contact information.
Accomplishments that we are proud of
We built a production-style multi-step agent that chains ingestion, indexing, search, LLM extraction, and export into a single flow. Every displayed fact is backed by at least one source URL and an exact quoted snippet. TiDB Serverless vector search powers fast similarity retrieval across heterogeneous sources. The UI presents image-first timelines with license-aware images and provenance logs that show confidence calculation strings. Automated tests enforce JSON schema validation, date normalization, and snippet length constraints.
What we learned
Feeding only exact quoted snippets to the extractor is the most reliable way to avoid hallucination. Transparently computing and storing a confidence calculation for each event builds trust and auditability. Hybrid vector plus full-text search yields better relevance for disambiguation and snippet retrieval. Rate-limit-aware crawlers with caching reduce interruptions and maintain freshness. Clear UI signals such as source snippets and license badges increase user trust more than stylized summaries alone.
What's next for Ojo
Short term roadmap
- Integrate Model Context Protocol (MCP) to standardize context exchange between the extractor and summarizer.
- Add a queue-based serverless crawler to incrementally refresh profiles.
- Enable user annotations with a verified correction workflow that updates provenance.
- Add Slack, Notion, and embeddable timeline widget exports.
Built With
- framer-motion
- github-api
- hosted-llm-apis
- linkedin-public-data
- mediawiki-api
- next.js
- tailwind-css
- tidb-cloud
- tidb-serverless
- typescript
- web-speech-api
- wikidata-sparql
- youtube-data-api

Log in or sign up for Devpost to join the conversation.