
Ojo - Wikipedia for Everyone
Know how they reached, not just who they are.
Inspiration
Wikipedia is incredible but it mainly documents those already famous.
If you want to know how Sundar Pichai or Elon Musk got to where they are, you’ll find only a summary, not the full story.
And if you search for someone less known - a local entrepreneur, researcher, or even yourself -Wikipedia gives nothing.
That’s why we built Ojo, Wikipedia for everyone, where you can know how they reached, not just who they are.
Ojo makes verifiable life journeys accessible to anyone. It lets curious people, recruiters, mentors, researchers, and community members search any name and discover the complete, evidence-backed path of a person’s growth - from education to projects to turning points.
Our goal is to convert scattered public records into a single, traceable, auditable timeline that teaches and inspires.
What It Does
Ojo accepts a person’s name (via text or voice) and returns a ranked disambiguation list.
Once the user confirms a candidate, Ojo aggregates verified public signals from sources like LinkedIn, GitHub, YouTube, MediaWiki, and Google Search.
Each person’s journey is visualized as an image-first interactive timeline, with:
- Exact quoted source snippets (max 25 words)
- Source URLs and provenance logs
- ISO date-normalized events
- Verified summaries and hero images (license-aware)
Every node represents a milestone - an education, a job, a project, or an achievement - backed by real evidence.
How we built it
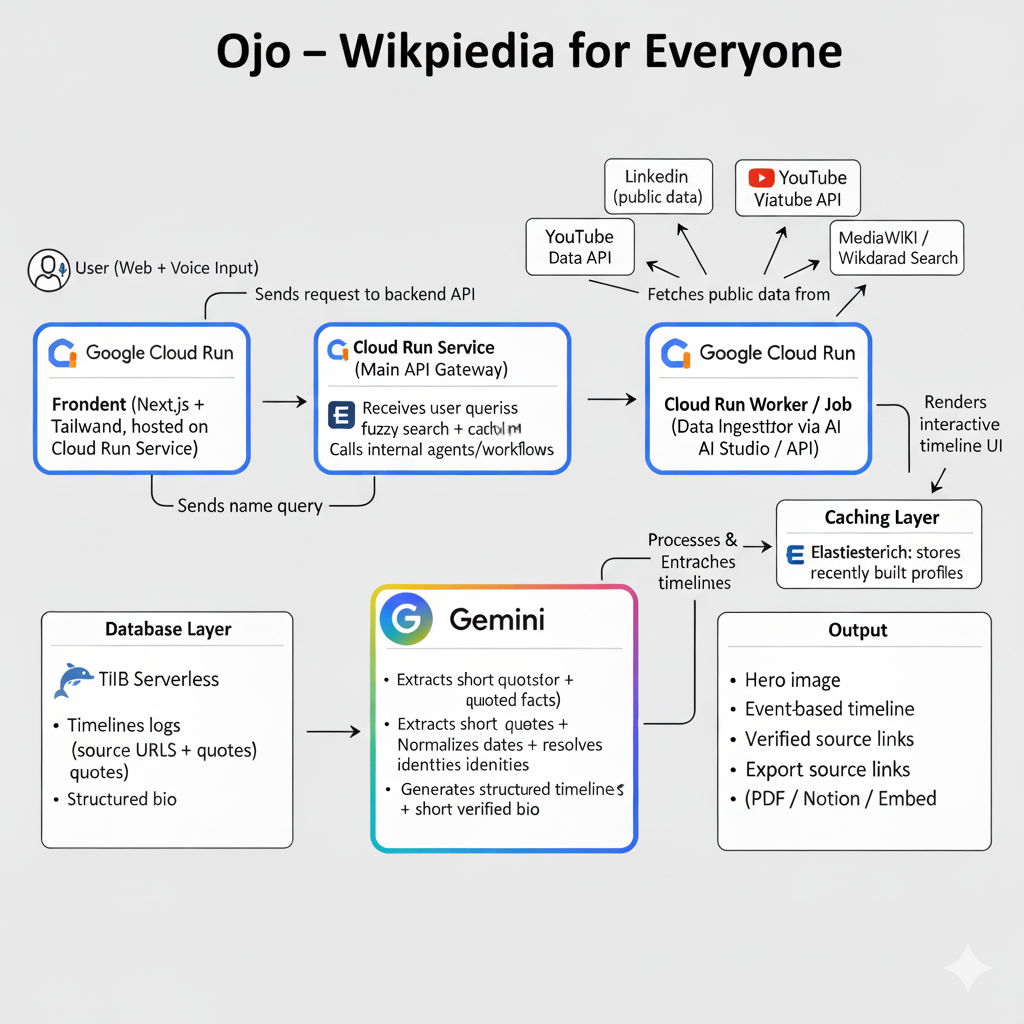
We deployed Ojo as a multi-agent workflow on Cloud Run, powered by Gemini:
- Cloud Run Services handle the user API and UI delivery.
- Cloud Run Jobs / Worker Pools perform data ingestion and profile refresh tasks.
- Gemini (AI Studio + API) extracts timeline events, resolves entities, and generates concise bios.
- Elasticsearch handles name search, fuzzy matching, and cached profile lookups.
- The frontend (Next.js + Tailwind) renders the interactive visual timeline.
All AI outputs are grounded in quoted evidence, preventing hallucination and ensuring trust.
Challenges we ran into
- Preventing model hallucination when summarizing fragmented data
- Normalizing dates from inconsistent web sources
- Designing multi-agent orchestration that scales efficiently
- Ensuring repeated profile lookups are fast and API cost-effective
- Managing provenance metadata so users can audit every fact easily
Accomplishments that we're proud of
- Achieved a fully verifiable, evidence-driven timeline builder
- Eliminated hallucinations by restricting AI input to exact quoted snippets
- Reduced subsequent lookup time from seconds to milliseconds using Elasticsearch caching
- Built a clean, image-first UI that makes complex journeys intuitive to explore
- Created a pipeline ready for real-world scale on Cloud Run
What we learned
- Grounding AI in evidence is the strongest path to trust
- Hybrid search (semantic + keyword) dramatically improves name matching
- Agent orchestration works best when each agent has a clear, narrow responsibility
- Cloud Run makes it surprisingly easy to scale from a prototype to production workflows
What's next for Ojo
- Add MCP (Model Context Protocol) to improve agent collaboration
- Introduce community annotations + crowd-sourced fact verification
- Release Notion, Slack, and website embed widgets for sharing timelines
- Expand timelines into network graphs to show relationships, influences, teams, and mentorships
Ojo is just getting started — we’re building the world’s first open, verifiable map of human growth.
Built With
- api
- cloud-storage-(optional)
- elasticsearch
- framer-motion
- gemini-(ai-studio)
- github-api
- google-agent-development-kit-(adk)
- google-cloud-run
- google-cloud-run-jobs
- linkedin-public-data
- mediawiki-+-wikidata-sparql
- next.js
- speech
- tailwind-css
- tidb-serverless
- typescript
- web
- youtube-data-api






Log in or sign up for Devpost to join the conversation.