-
-
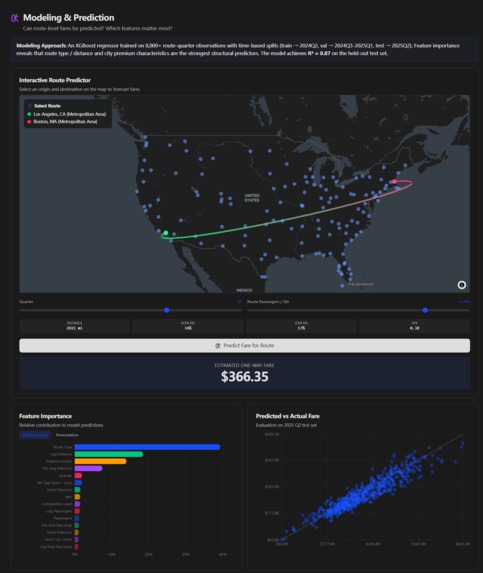
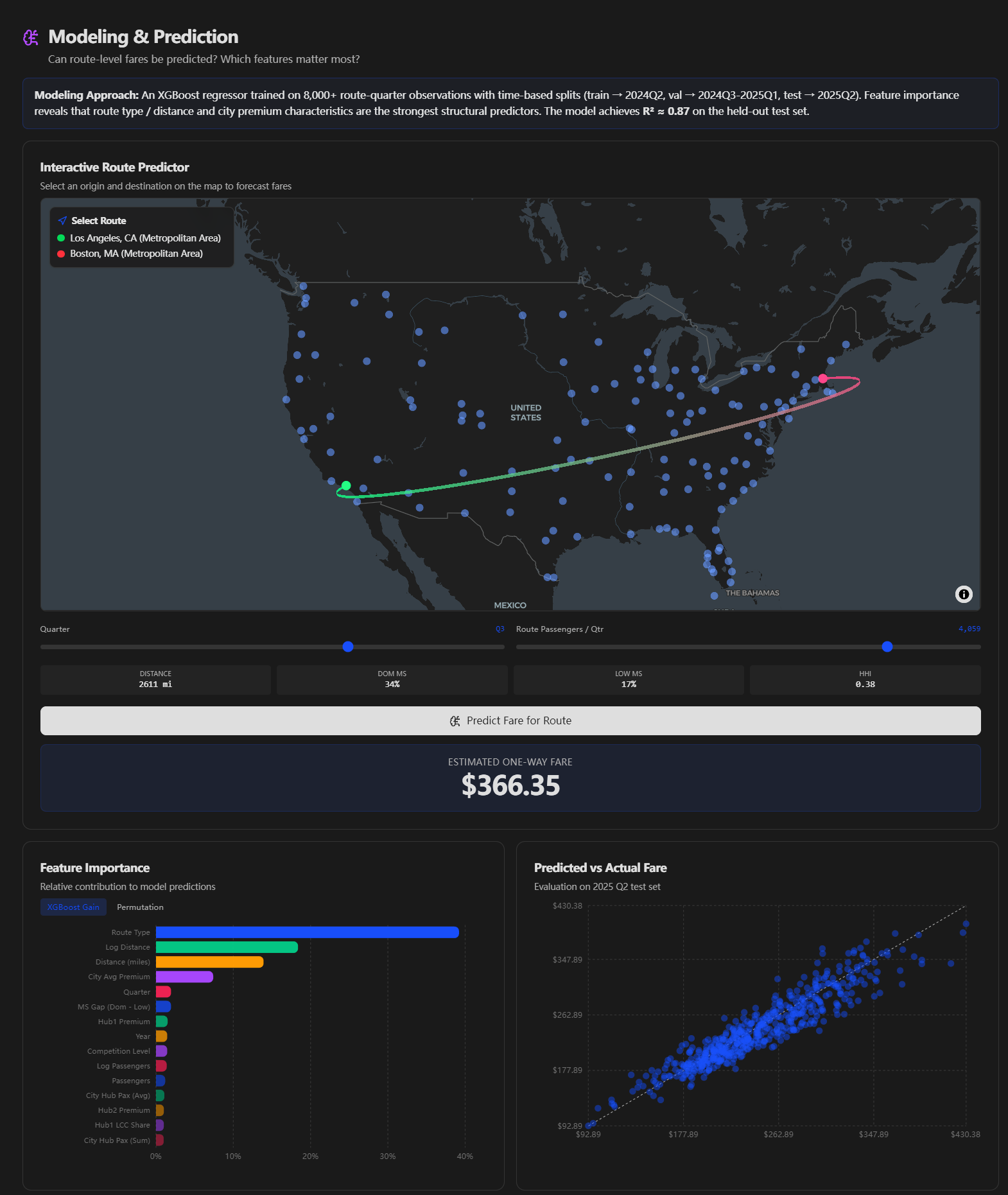
Model & Prediction
-
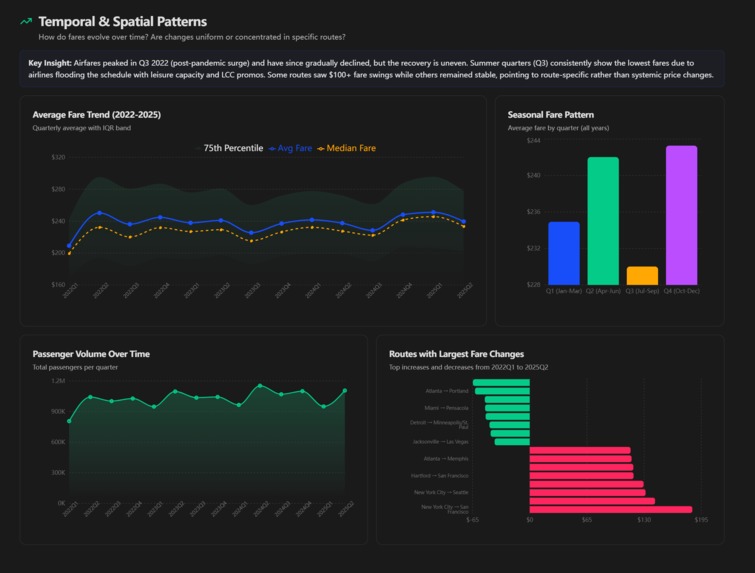
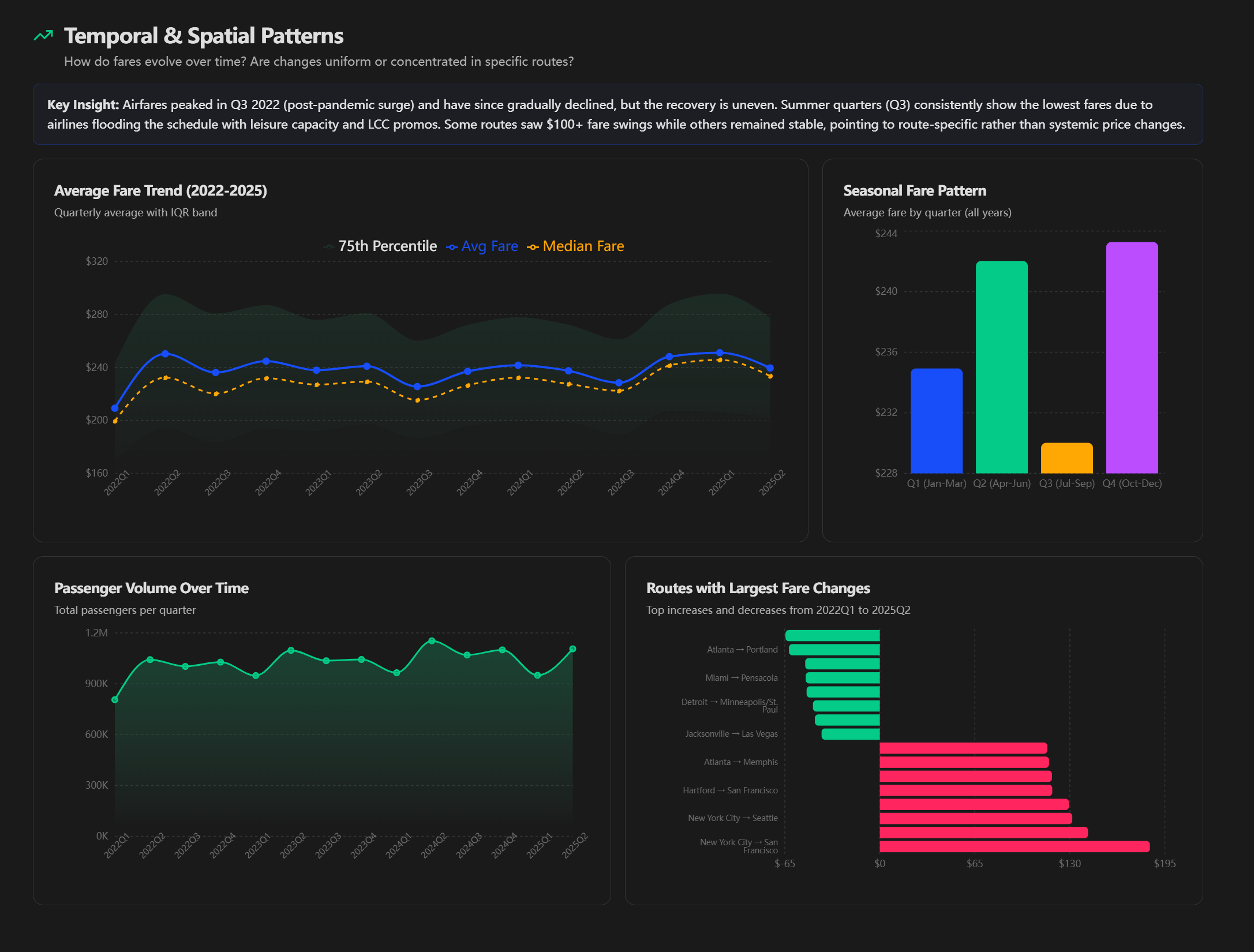
Temporal Patterns
-
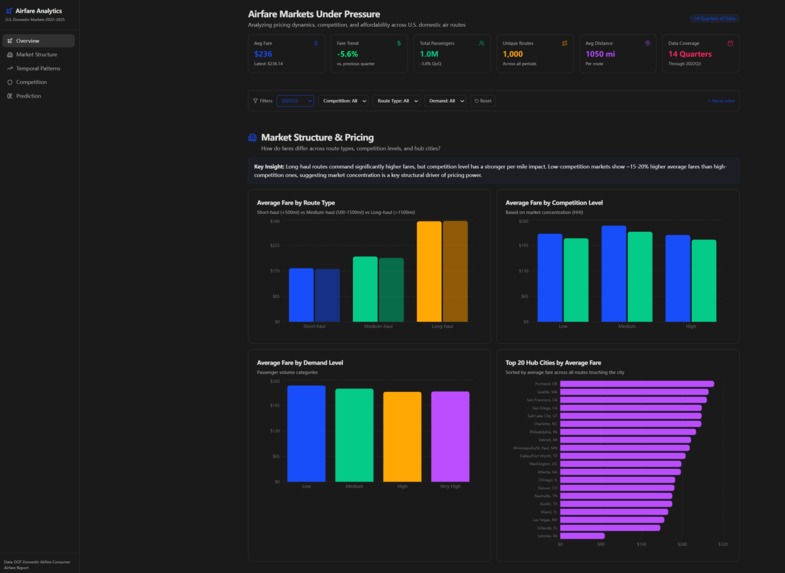
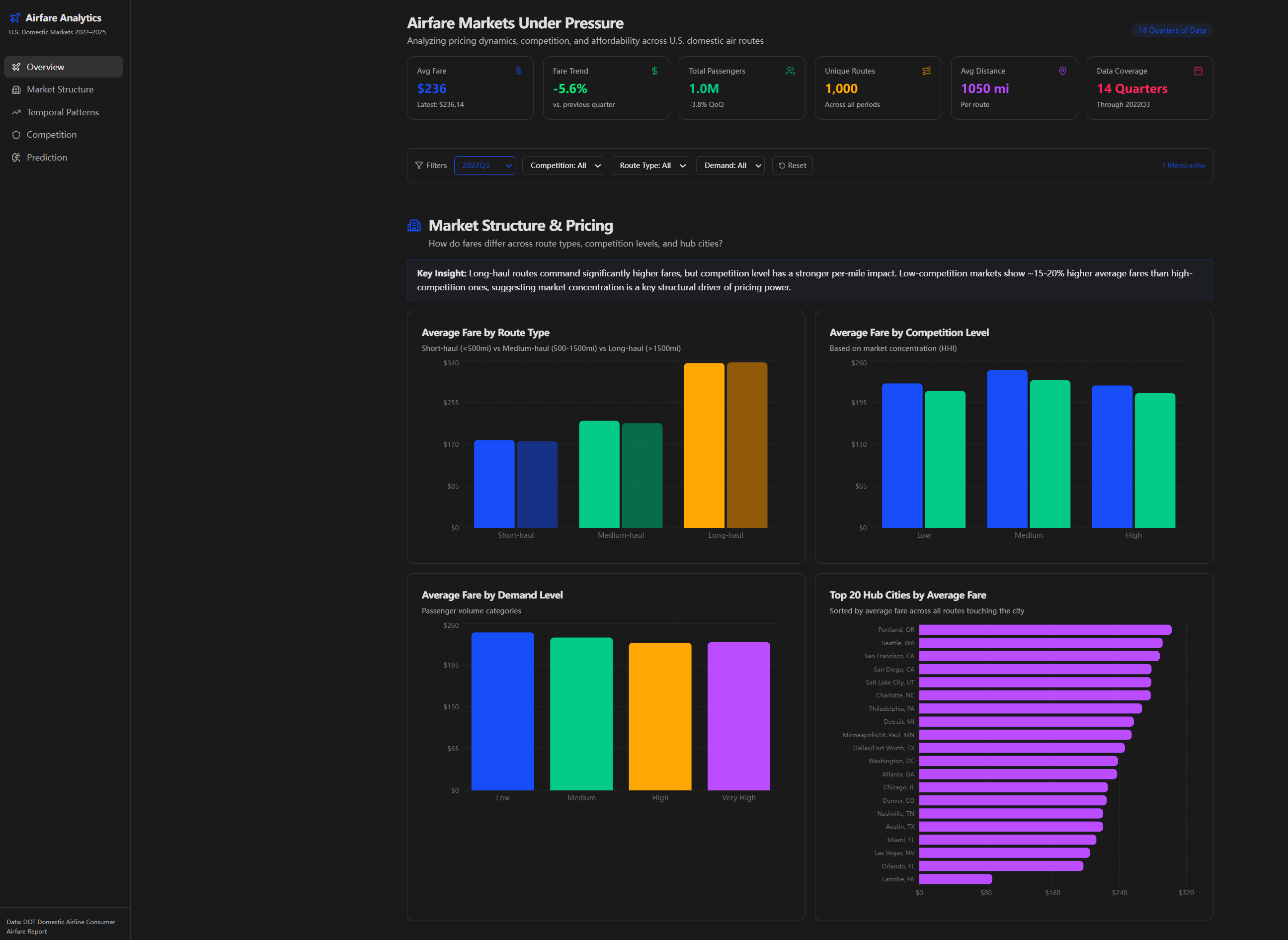
Market Structure
-
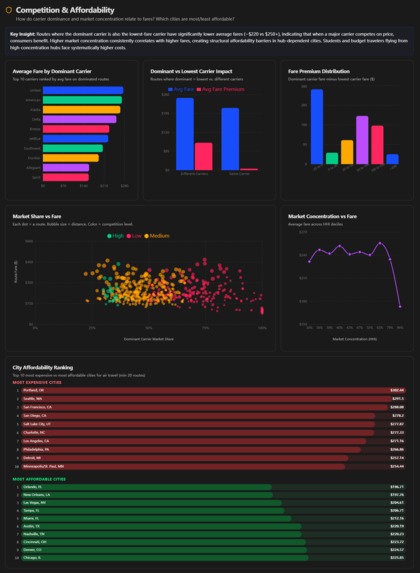
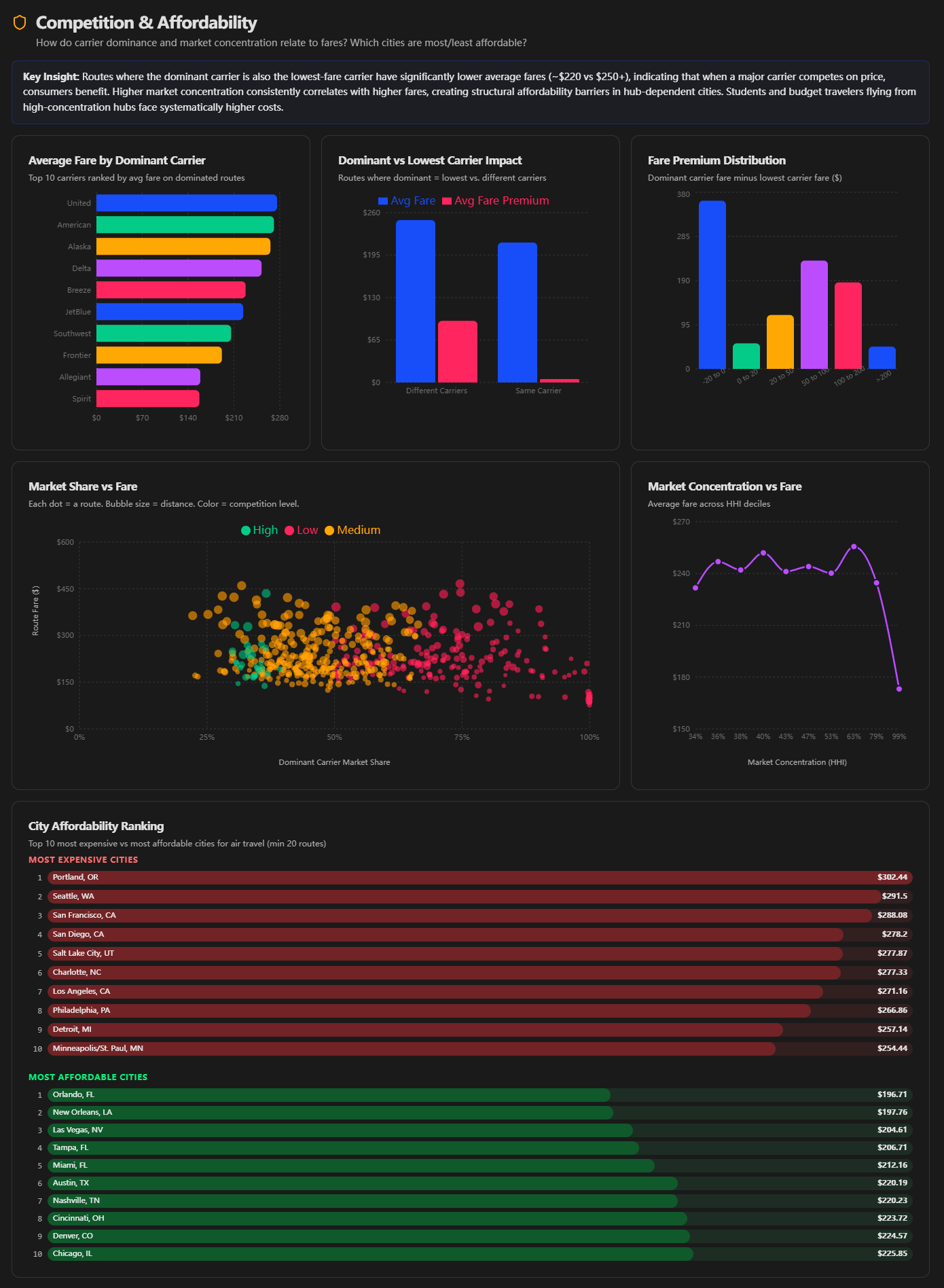
Competitions
Project Story
About the Project
Airfare headlines kept citing “mystery surcharges,” but most articles lacked route-level evidence. That gap pushed me to build a transparent analytics stack that traces each fare back to measurable structure—distance, competition, and hub power—instead of vague narratives. The Data Marathon brief further nudged me to turn a static dataset into a story-first dashboard that stakeholders can actually explore, filter, and validate.
What I Learned
- Translating aviation economics into engineered features matters: deriving price-per-mile, demand bins, and hub premiums made the model’s behavior far more interpretable.
- Building a clean MLOps loop (data → XGBoost training → FastAPI serving) enforced disciplined reproducibility: versioned CSVs, pinned dependencies, and deterministic seeds.
- Story-first UX beats chart dumps: curating 16 endpoints into 5 dashboard sections helped surface the “so what” behind each metric instead of overwhelming users with raw plots.
How I Built It
- Data pipeline —
clean_data.pyingests ~14k rows, handles currency coercion, imputes missing city metrics, then exports both vis-ready and ML-ready tables. Market concentration is computed via the Herfindahl–Hirschman Index:
$$ HHI = \sum_i s_i^2 $$
where \( s_i \) is carrier \( i \)’s market share (using a three-share proxy when full carrier breakdowns aren’t available).
Modeling layer —
backend/app/models/train_cli.pyruns a 100-trial XGBoost search (hist method, time-based split) and logs artifacts for deployment, including tuned hyperparameters and evaluation outputs.Service + UX — FastAPI exposes 16 visualization routes plus
/predict/fare, while a Vite + Tailwind React dashboard consumes them with live filters and an interactive fare predictor for “what-if” exploration.
Challenges
- HHI estimation: Limited carrier breakdowns required a proxy that wouldn’t oscillate across routes. Clipping shares and smoothing medians stabilized the concentration signal without destroying ranking.
- GPU/CPU parity: Training on GPU introduced slight numeric drift. Exporting the tuned parameters and re-running with
fallback_to_cpukept serving behavior consistent and easier to reproduce.
Built With
- fast
- javascripts
- python
- react
- scikit-learn
- tailwind




Log in or sign up for Devpost to join the conversation.