-
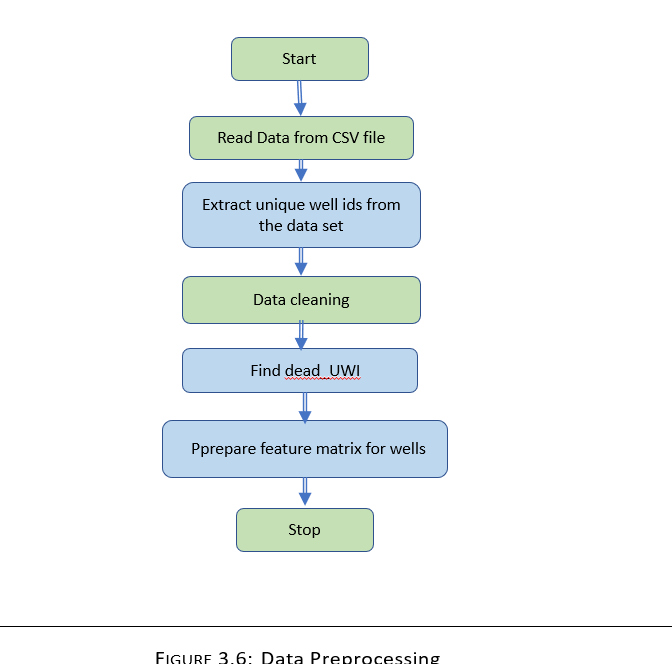
Data Processing
-
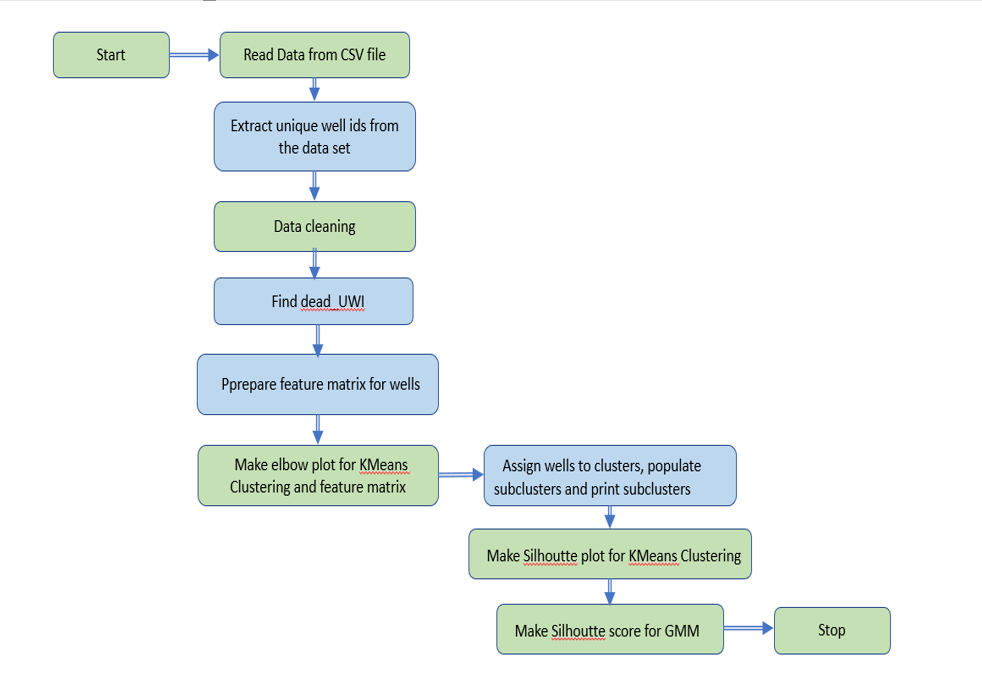
Workflow
-
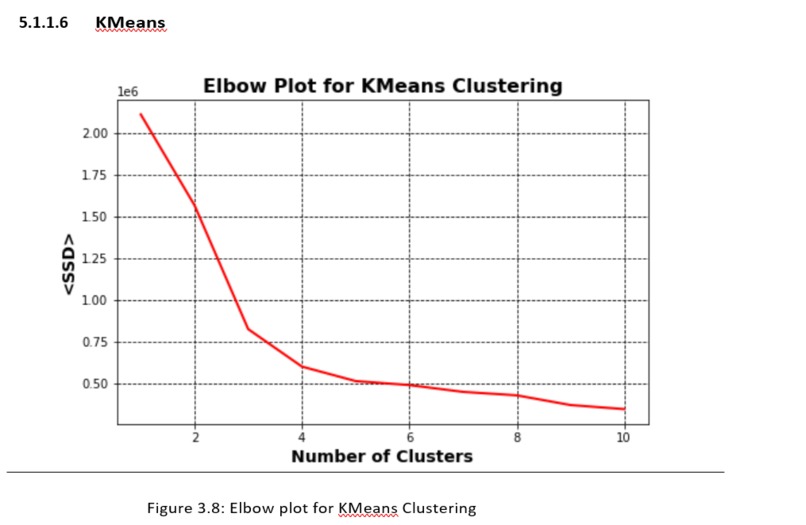
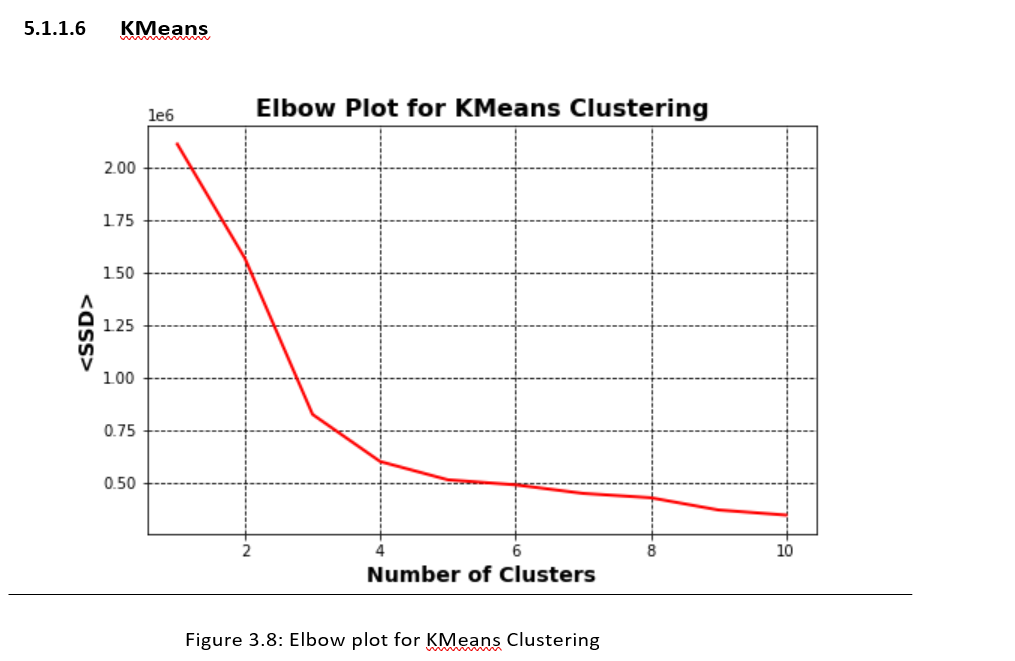
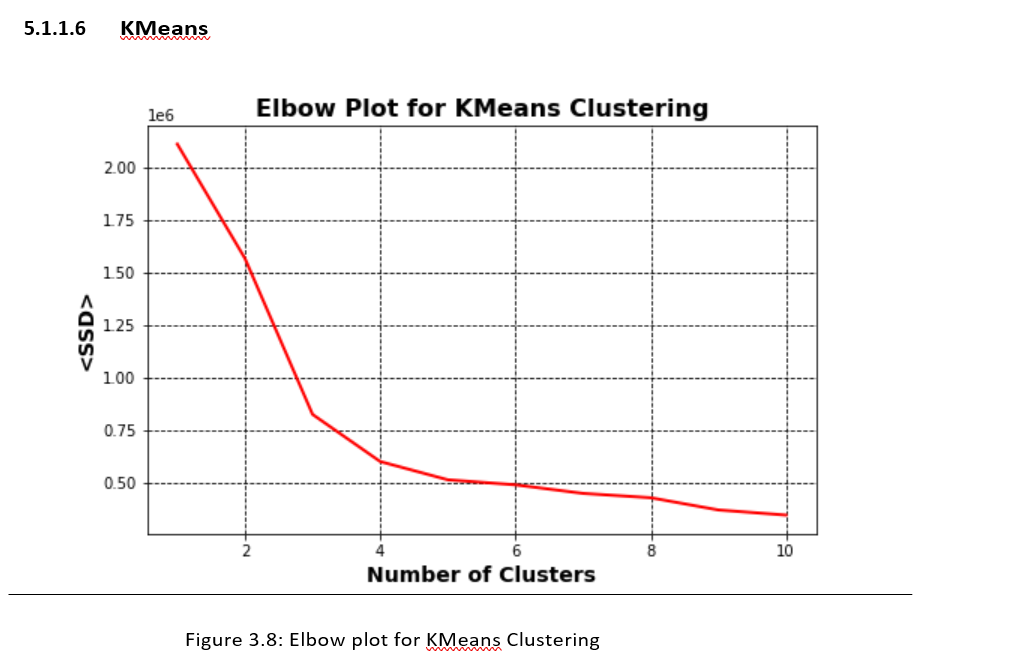
KMeans Elbow
-

-
Well performance
-
-

Inspiration
Manually estimating the performance of oil and gas wells would be extremely difficult, and this complexity depends on several aspects, including depending on operational engineers and their decision-making skills, readiness for unforeseen downtimes, appropriate system understanding, etc. Oil and gas well performance maintenance would influence well production engineering and maintenance, both of which would directly affect the CAPEX and OPEX of the oil and gas sector.
This difficulty is resolved by creating the ML model that will proactively predict well performance, which will help to prioritize wells falling into the low and medium categories for incremental production increases.
What it does
Manually estimating the well performance (how much uptime, availability, etc.) would be a very difficult process, and it depends on many different things, including the operational engineers' capacity to make decisions, their readiness for unforeseen downtimes, their grasp of the system, etc. The continuing procedure should involve anticipating well performance in advance. So, automating crucial production engineering tasks will be made possible by using machine learning and deep learning approaches to forecast well performance.
How we built it
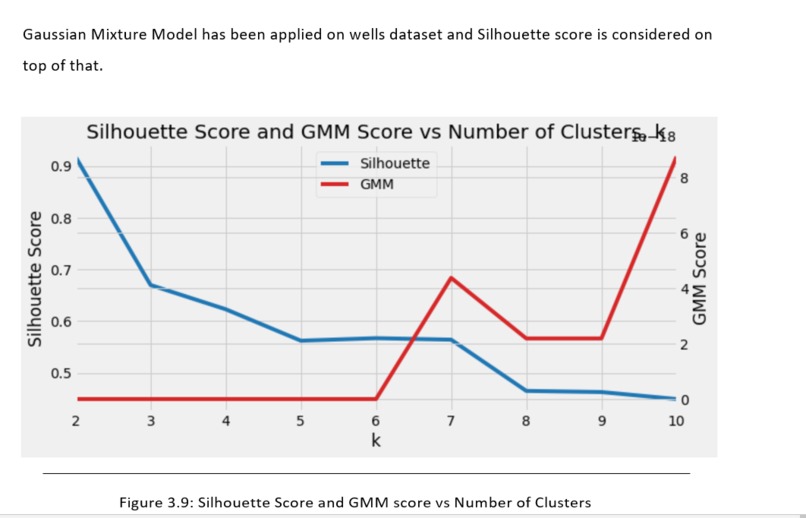
Approach: The technical goal of the project is to develop a data model for predicting well performance using unsupervised clustering approaches such the k-means algorithm, Gaussian Mixture Model algorithm, etc., and evaluate the quality of metrics with each algorithm.
Data : Data Sets from National Library of Medicine : This information, which predicts oil, gas, and water output over a period of around three years, was contributed by researchers at the National Library of Medicine, Saudi Arabia Aramco. Five datasets were obtained from five drilling reservoirs. Twelve features composed the total combined custom data set.
Data Sets from National Natural Science Foundation : This dataset is provided by researchers at the National Natural Science Foundation. Researchers shared data dictionaries associated with the data sets used in their studies.
Steps fallowed:
- Data Collection and Exploratory Data Analysis
- Data Preparation and Data Dictionary
- Perform Experiments
Challenges we ran into
- Availability of Data
- Volume of data
Accomplishments that we're proud of
Implementation of unsupervised learning in Oil and Gas use case.
What we learned
Implementing ML algorithms to real time use case
What's next for Oil and Gas well performance prediction
The results from the work show promising results in using K means and Gaussian Mixture Model, hence these could be explored deeper. With more and more larger data set would make data to get categorized with a greater number of clusters. With increase in number of clusters, these can be mapped to High, medium, and low amount of cumulative oil which can be categorized as steady, increasing, and declining clusters. We can also examine the EM, CEM, and SEM algorithms. In the process of calculating local maximum likelihood estimates (MLE) or maximum posterior estimates (MAP) for detecting unobservable variables in statistical models, a multitude of unsupervised machine learning algorithms are used. utilized for larger, more variety of data sets.

Log in or sign up for Devpost to join the conversation.