-
-
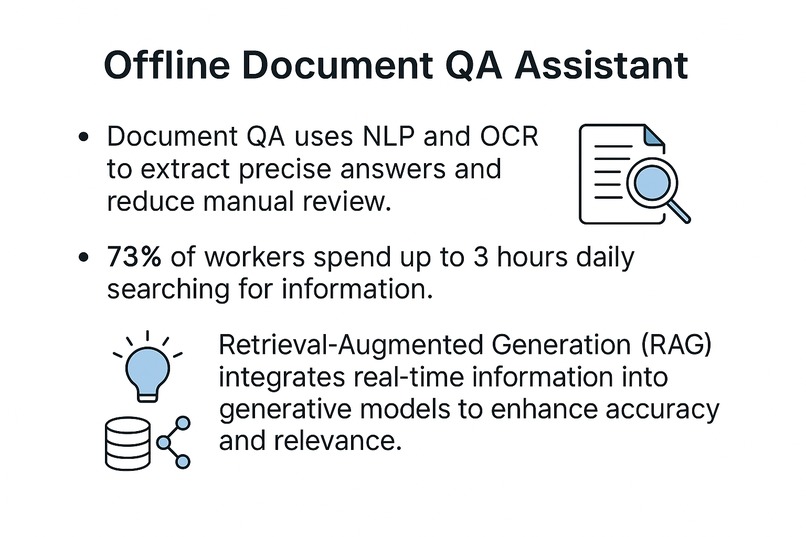
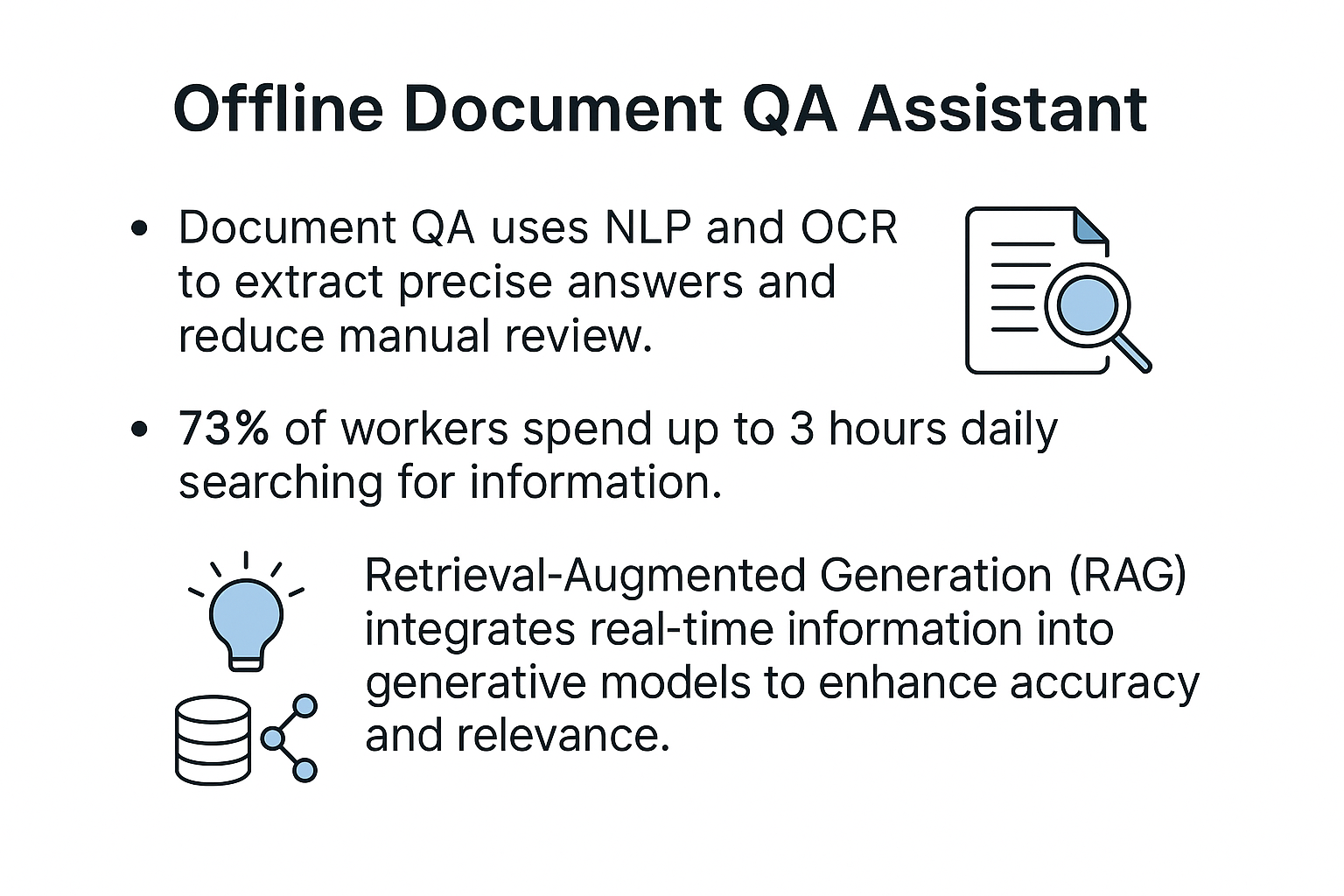
NLP/OCR لاستخراج إجابات دقيقة وتقليل المراجعة؛ 73% يقضون نحو 3 ساعات في البحث؛ RAG يدمج معلومات فورية لتحسين الدقة. المصدر: ShareFile
-

Scientific visual of offline AI assistant summarizing local documents using GPT-OSS with retrieval-augmented generation.
-

AI assistant analyzing local documents offline to generate answers and summaries.
-
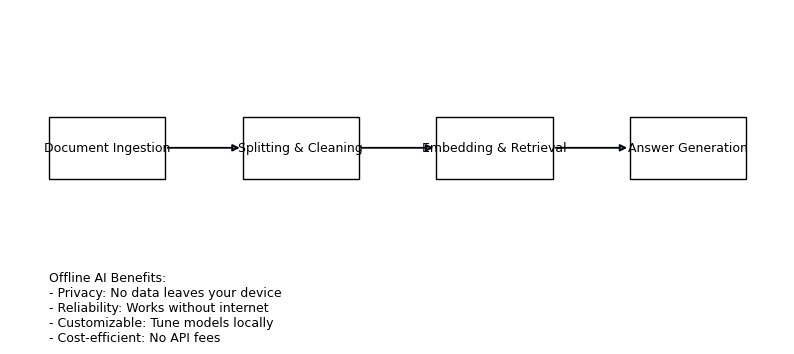
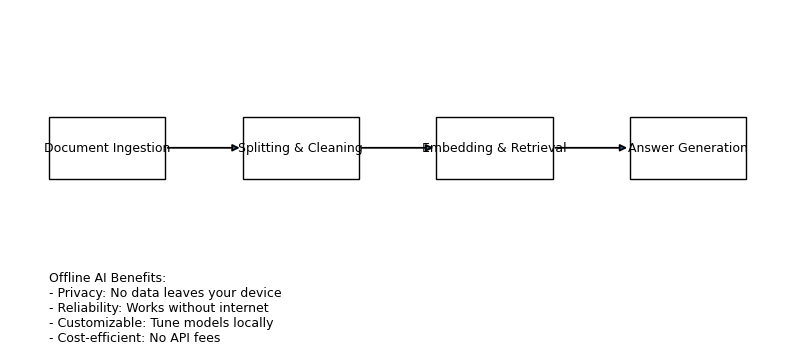
Pipeline: ingest → split & clean → embed & retrieve → generate answers. Offline AI adds privacy, reliability & cost-efficiency.


Inspiration
Modern language models achieve impressive performance, but relying on remote APIs raises privacy concerns for sensitive documents. Recent research on retrieval-augmented generation (RAG) shows that combining a language model with a document retriever can improve factual accuracy and reduce hallucinations by grounding answers in source material. We wanted to explore how far open-source models could push this paradigm offline.
What it does
Offline Document QA Assistant ingests a collection of local documents (PDFs, reports and articles) and builds a vector index over their contents. When a user asks a question, the assistant performs semantic search to retrieve the most relevant passages and then uses the open-source gpt-oss model to generate an answer conditioned on those passages. Because the model is grounded in retrieved context, it produces concise summaries and answers backed by evidence from the user’s own documents. No internet connection or external API is required, so confidential data never leaves the device.
How we built it
We implemented a Python application using the Hugging Face Transformers library to run the gpt-oss-20b model locally on an RTX 4090 GPU. A pre-processing pipeline converts documents to plain text, cleans them and splits them into overlapping chunks. These chunks are embedded into a local vector store using FAISS. At query time we use maximum inner product search to find the top-k chunks, construct a retrieval-augmented prompt and feed it to gpt-oss. This architecture follows the RAG approach described by Lewis et al. (2020), which has been empirically shown to improve answer factuality by grounding responses in retrieved documents. The command-line interface is modular, allowing different loaders, embedders and retrievers to be swapped in, and it can run entirely offline.

Log in or sign up for Devpost to join the conversation.