-
-
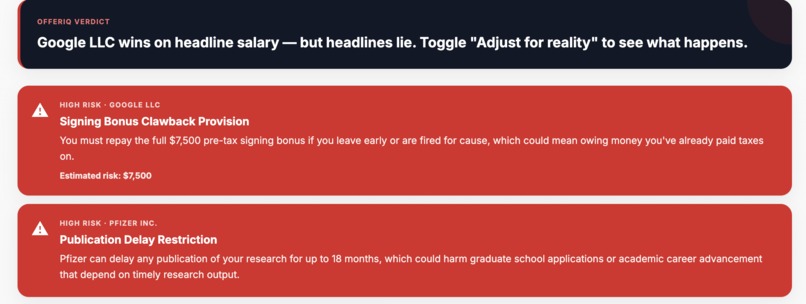
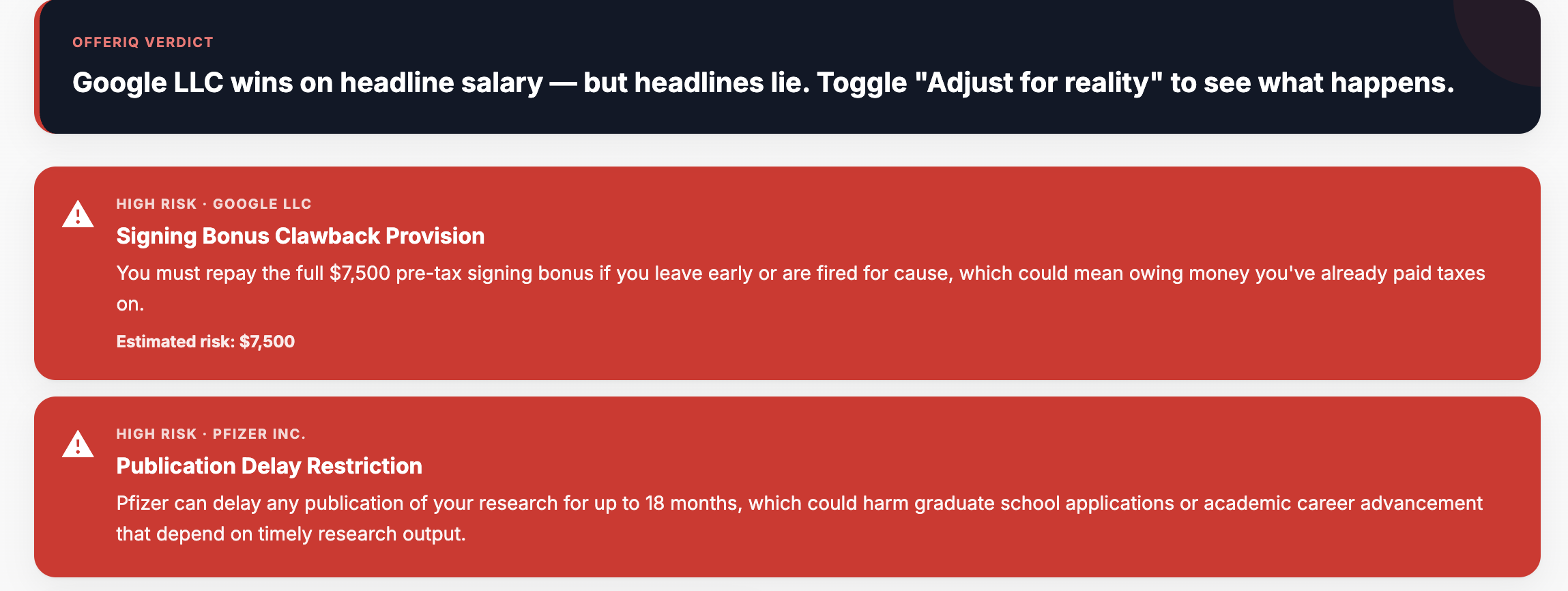
Cautions assocaited with each offer
-
Uploading Two offer letters side by side
-
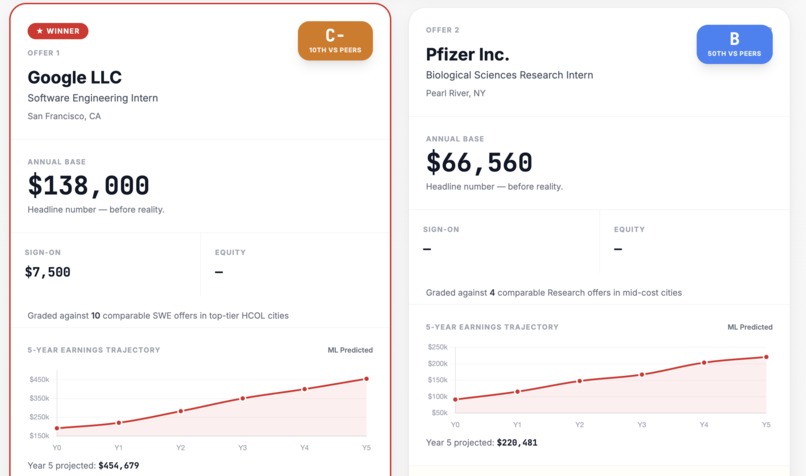
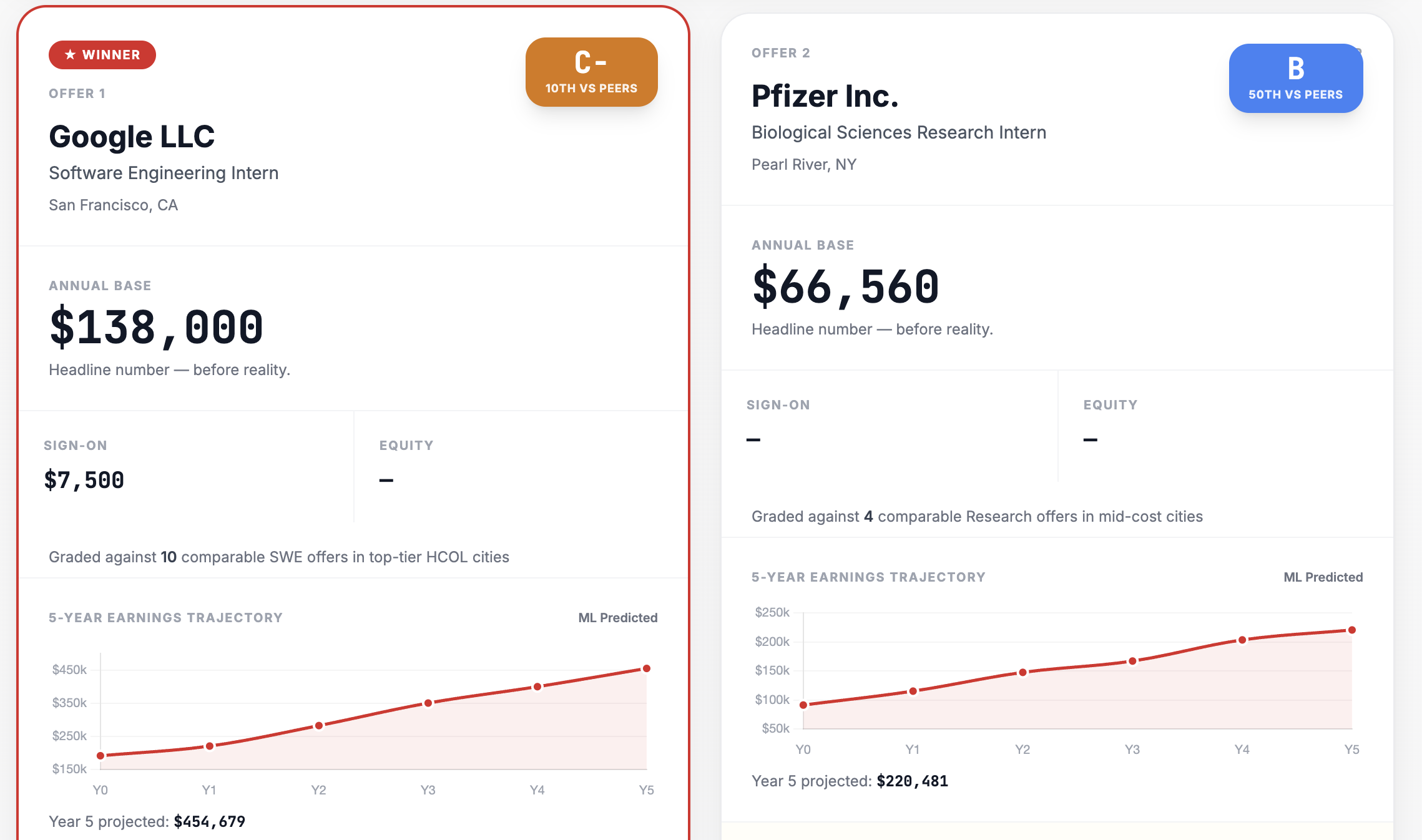
Real time comparison of two offers based on parsing
-
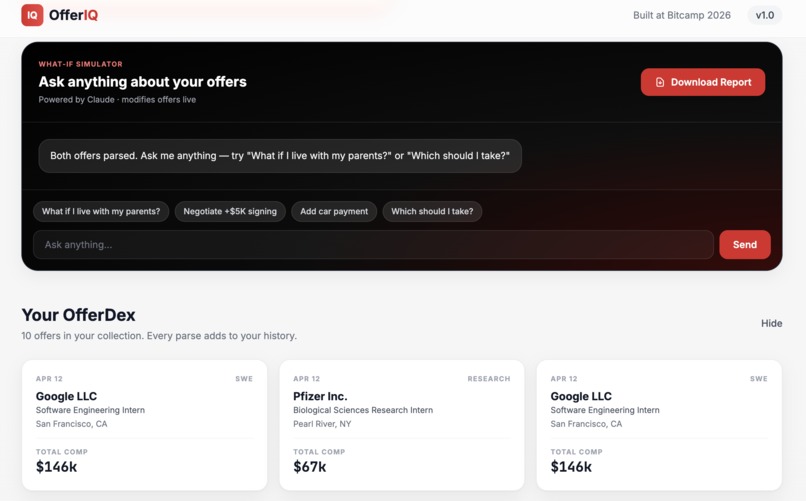
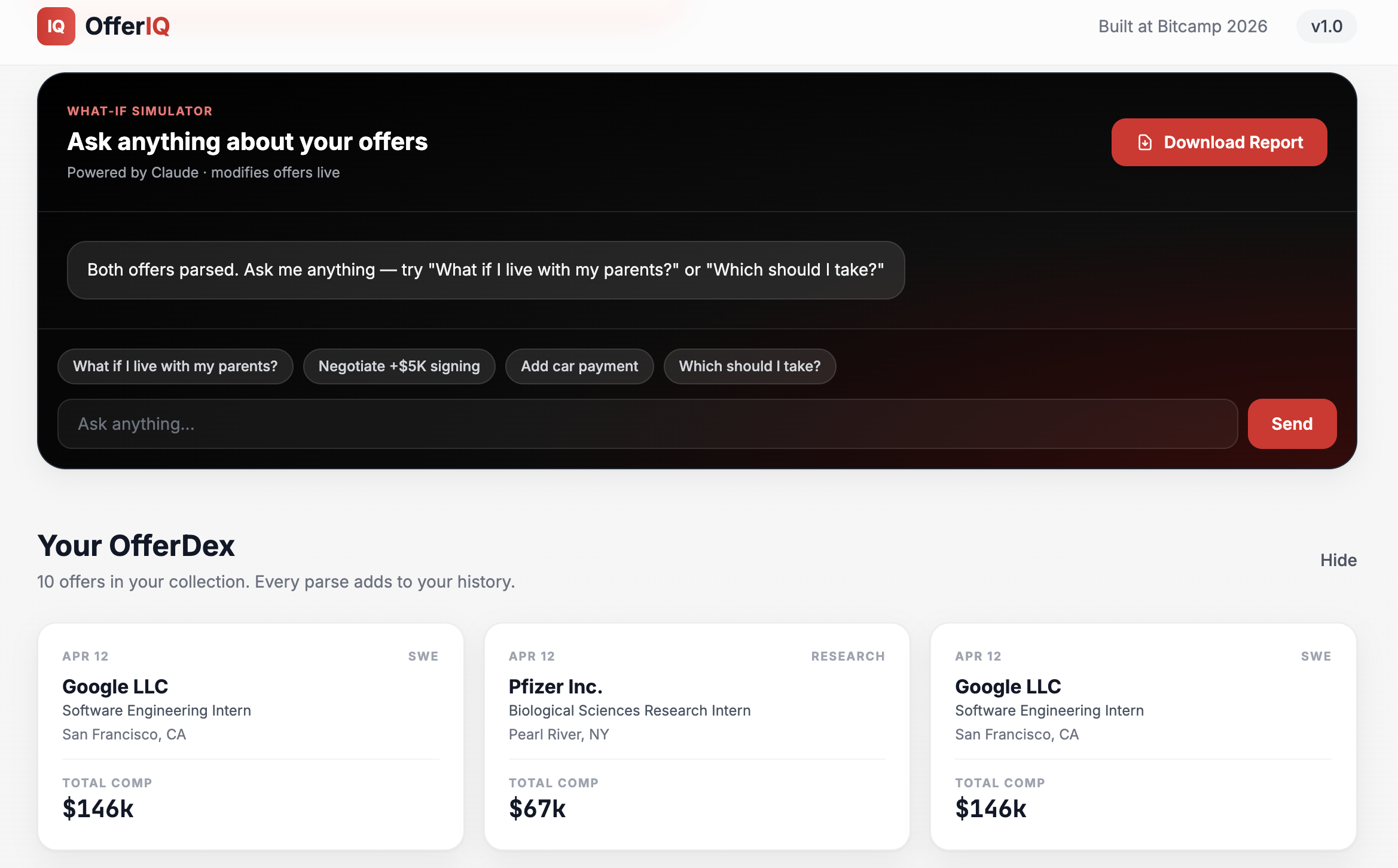
Chatbot to help assist in making decisions
Inspiration
I'm a freshman at UMD, and even this early, I've watched upperclassmen wrestle with offer letters they couldn't actually decode. The numbers at the top never match what lands in your bank account, and nobody reads to page 7 where the clawback clauses live. Levels.fyi shows aggregate data, Glassdoor shows reviews, Reddit gives anecdotes — but nothing actually reads your specific offer and tells you the truth. So I built the tool I'll need in two years, and every student around me needs it right now.
What it does
OfferIQ takes two offer letter PDFs and, in 30 seconds, tells you which one is actually better. It parses every number and clause with Claude, adjusts for federal tax, state tax, and rent across 29 cities, runs a second Claude call as a skeptical employment lawyer to surface hidden risks, predicts a 5-year earnings trajectory with a trained ML model, grades each offer against historical data with a peer-relative letter grade, and lets you ask any what-if question in a live chatbot that re-runs every system in real time. One click downloads a branded PDF Decision Report.
How we built it
Flask + SQLite backend, Tailwind frontend via a single Jinja2 template, Chart.js for live trajectories. The PDF parser uses pdfplumber + the Anthropic Claude API with a structured-extraction prompt. The red flag detector is a second Claude call with an employment-lawyer persona. The ML model is a scikit-learn GradientBoostingRegressor trained on 600+ real compensation data points across 7 company tiers and 9 role categories, achieving 0.85 test R². The chatbot uses Claude tool-use with three custom what-if tools that mutate offer state server-side. The PDF report is generated with fpdf2. Two Claude calls run in parallel to halve perceived latency.
Challenges we ran into
Claude tool-use was the hardest piece — the two-step call pattern (initial response → parse tool call → execute → feed result back → get natural-language reply) took real debugging to get clean. The PDF generator hit a subtle fpdf2 geometry bug where cumulative cursor drift from mixing relative positioning with ln=False pushed cells off the page margin; the fix was making every cell position fully explicit. Percentile grading kept misclassifying Capital One until I realized my role-classification heuristic was bucketing "Technology Development Program" into the wrong peer group.
Accomplishments that we're proud of
Shipping 7 composed features solo. The real win is that every system talks to every other system in real time — when the chatbot runs a tool, the cards re-render, the verdict flips, the ML chart regenerates, the winner badge moves, all from one user message. Most hackathon projects have features; this has composition. I'm also proud of the honesty of the ML — real model, real data, real R², defensible under any judge's questioning.
What we learned
Scope discipline is everything when you're solo. Every feature in OfferIQ is the simplest version that still lands its demo beat — the parser is a Claude call instead of a custom OCR pipeline, the ML is a pre-trained pickle instead of live retraining, the database is SQLite instead of Postgres, and there's no auth. That restraint is what let me actually finish. I also learned the art of composition layers: the moment in a demo where multiple systems visibly respond to a single action is worth more than any single impressive feature.
What's next for OfferIQ
A larger ML training set scraped live from Levels.fyi for tighter confidence intervals; a Leaflet map with cost-of-living and tax overlays; multi-user support with Auth0 so the OfferDex becomes a community resource with anonymized cross-user percentiles; and a negotiation simulator mode where the chatbot roleplays a recruiter.
Built With
- anthropic-claude-api
- chart.js
- claude-sonnet-4.5
- flask
- fpdf2
- html5
- javascript
- joblib
- numpy
- pandas
- pdfplumber
- python
- scikit-learn
- sqlite
- tailwindcss





Log in or sign up for Devpost to join the conversation.