-
-
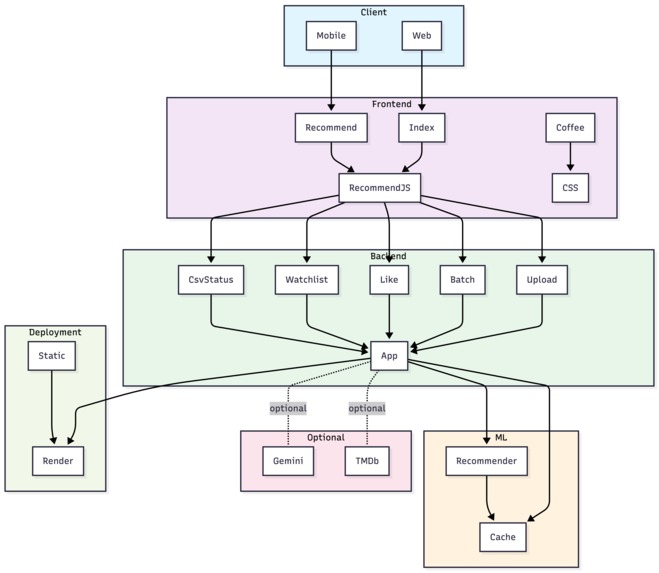
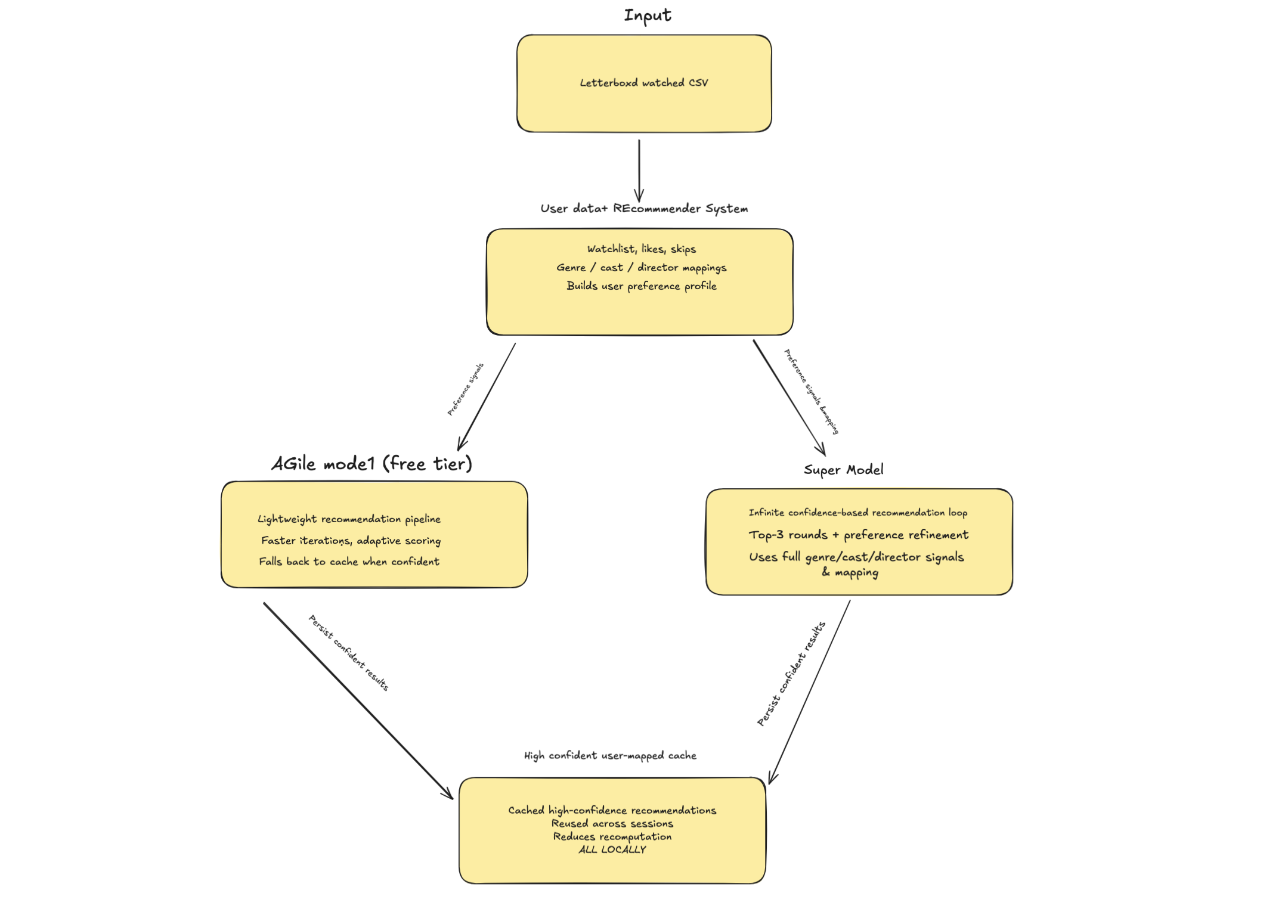
System Architecture
-
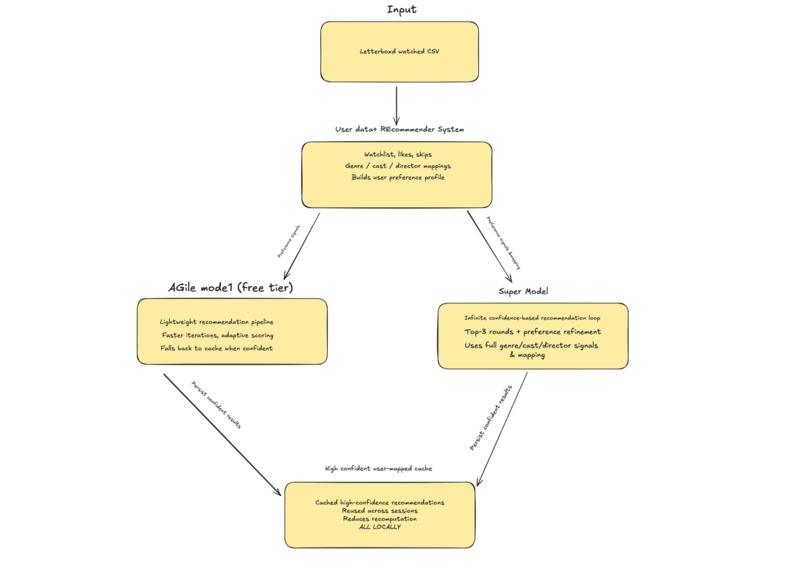
high level logic
-
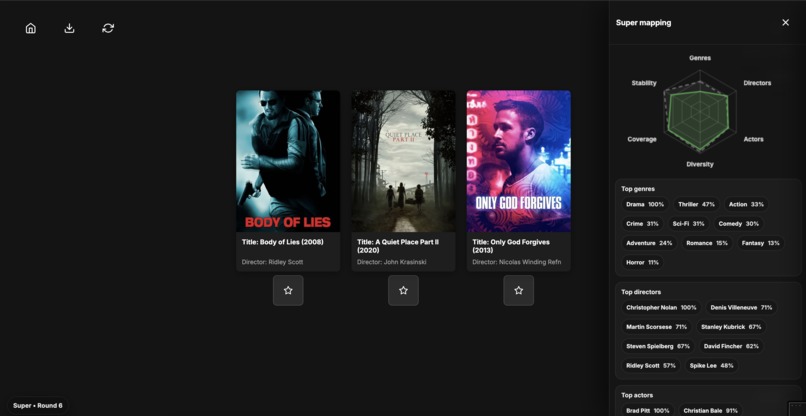
Movie genre Mapping
Inspiration
Odyssey was inspired by a simple frustration: streaming platforms rely on opaque recommendation algorithms that often miss personal taste, while browsing massive catalogs is exhausting. Users are rarely told why something is recommended.
The idea was to reverse that flow. Instead of passively consuming recommendations, users actively provide their own watch history and receive personalized, explainable suggestions in an interactive format. Odyssey is about control, transparency, and discovery.
What it does
Odyssey is an AI-powered movie recommendation platform driven by user-provided watch history.
Users upload a CSV file (IMDb, Netflix, or similar). Odyssey parses and normalizes the data, builds a temporary user profile, and generates recommendations in batches. Users can like or skip movies, maintain a watchlist, and explore recommendations through a responsive, animated interface.
It supports two modes:
- Regular mode – Local recommendation engine using a curated IMDb dataset
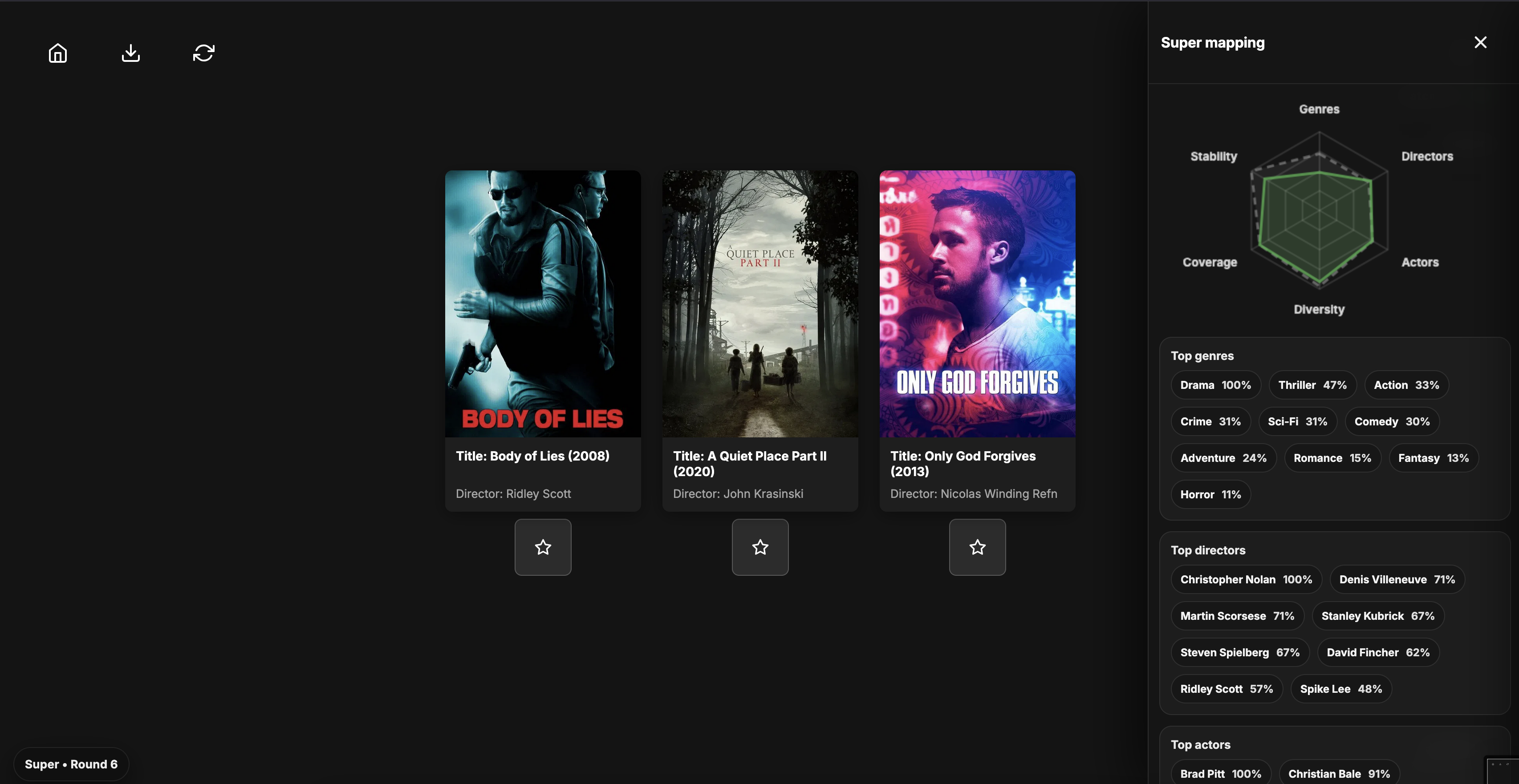
- Super mode – Gemini-powered recommendations with natural language reasoning and explainable mappings
How we built it
Odyssey uses a modular full-stack architecture.
On the backend, a Flask server exposes REST endpoints for CSV uploads, recommendation batches, and watchlist management. A local recommender scores candidate movies using genre overlap, director similarity, and actor co-occurrence. In Super mode, Gemini augments results with contextual reasoning.
On the frontend, the app is written in vanilla JavaScript and operates as a state machine. Recommendations are fetched in batches and stored in sessionStorage as a rolling queue. The UI includes a 3-card carousel with flip animations, a collapsible watchlist sidebar, and a canvas-based radar chart to visualize preference alignment.
Challenges we ran into
Recommendation algorithm design
We lacked traditional collaborative-filtering data. The solution was a hybrid scoring function:
$$ Score = w_1 \cdot GenreMatch + w_2 \cdot DirectorMatch + w_3 \cdot ActorMatch $$
Where:
- GenreMatch uses Jaccard similarity on genres
- DirectorMatch checks for overlap
- ActorMatch uses Jaccard similarity on actors
State persistence
Batch recommendations had to survive navigation. We stored the queue and interaction state in sessionStorage as structured JSON.
CSV inconsistencies
Watch histories vary widely. We built a flexible parser that detects column names, handles missing fields, and normalizes movie identifiers.
Unreliable LLM output
Gemini sometimes wraps JSON in markdown or extra text. We implemented a bracket-depth scanner to extract valid JSON safely.
Performance bottlenecks
Video backgrounds and animations initially caused jank. Lazy loading, GPU-accelerated transforms, and canvas rendering resolved this.
Deployment
Flask deployment required proper WSGI configuration, environment variable management, and static file handling on Render.
Accomplishments that we're proud of
- Built a full-stack recommendation engine without frontend frameworks
- Created an explainable AI recommendation flow
- Implemented resilient AI integration with robust error handling
- Designed a smooth, animated UI with persistent state
- Deployed and scaled the platform with CDN-backed media delivery
What we learned
We learned that vanilla JavaScript can scale cleanly with disciplined state management, that AI integrations require defensive engineering, and that clean data pipelines are critical to meaningful recommendations. Performance and explainability are not optional—they directly impact user trust.
What's next for Odyssey
Next steps include integrating real-time platform APIs, improving recommendations with lightweight embeddings, expanding Super mode explanations, and adding social features like shared watchlists. Long term, Odyssey aims to become a transparent, user-owned discovery engine for personalized content.

Log in or sign up for Devpost to join the conversation.