-
-
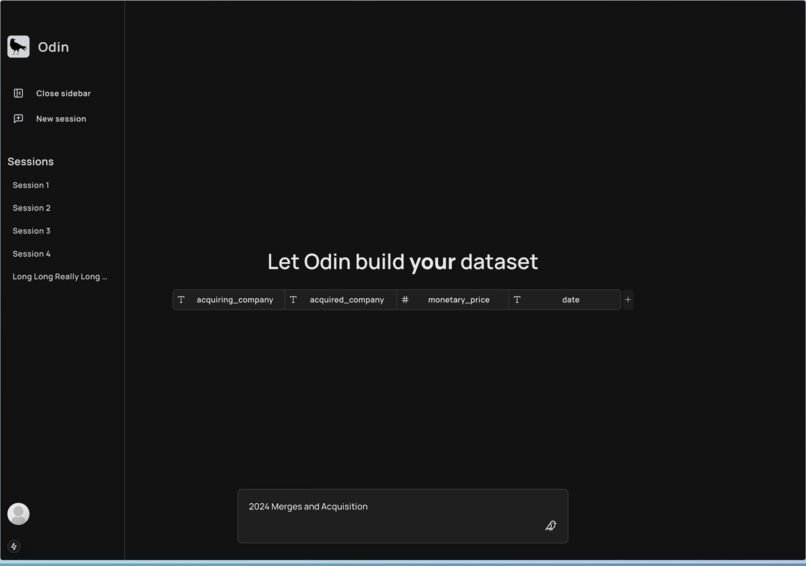
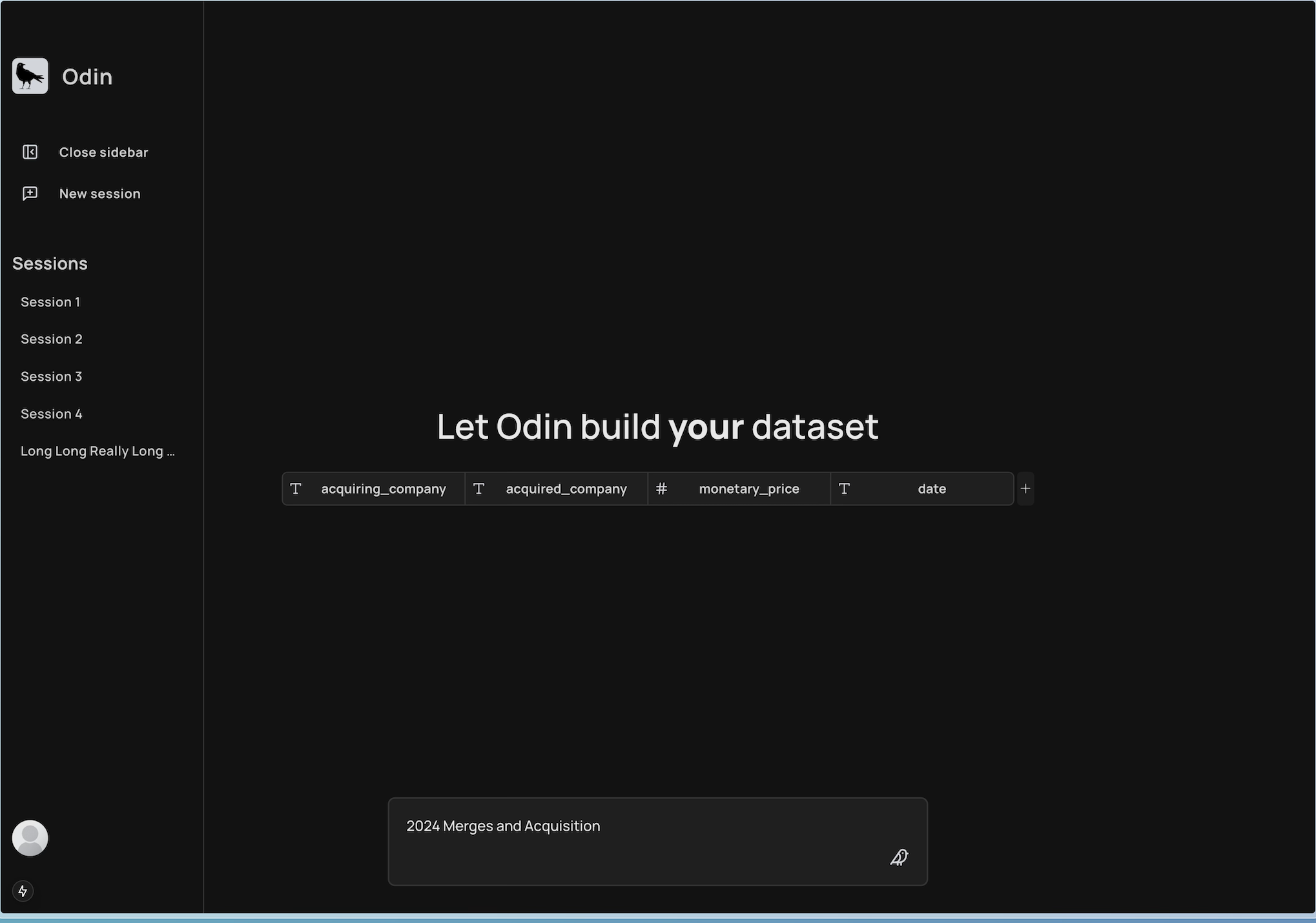
Odin Prompt Page
-
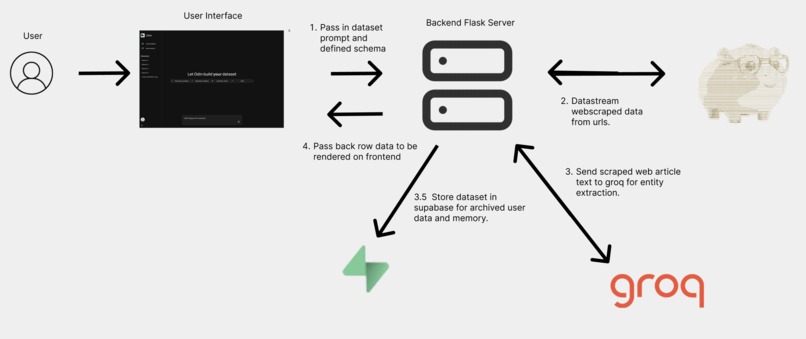
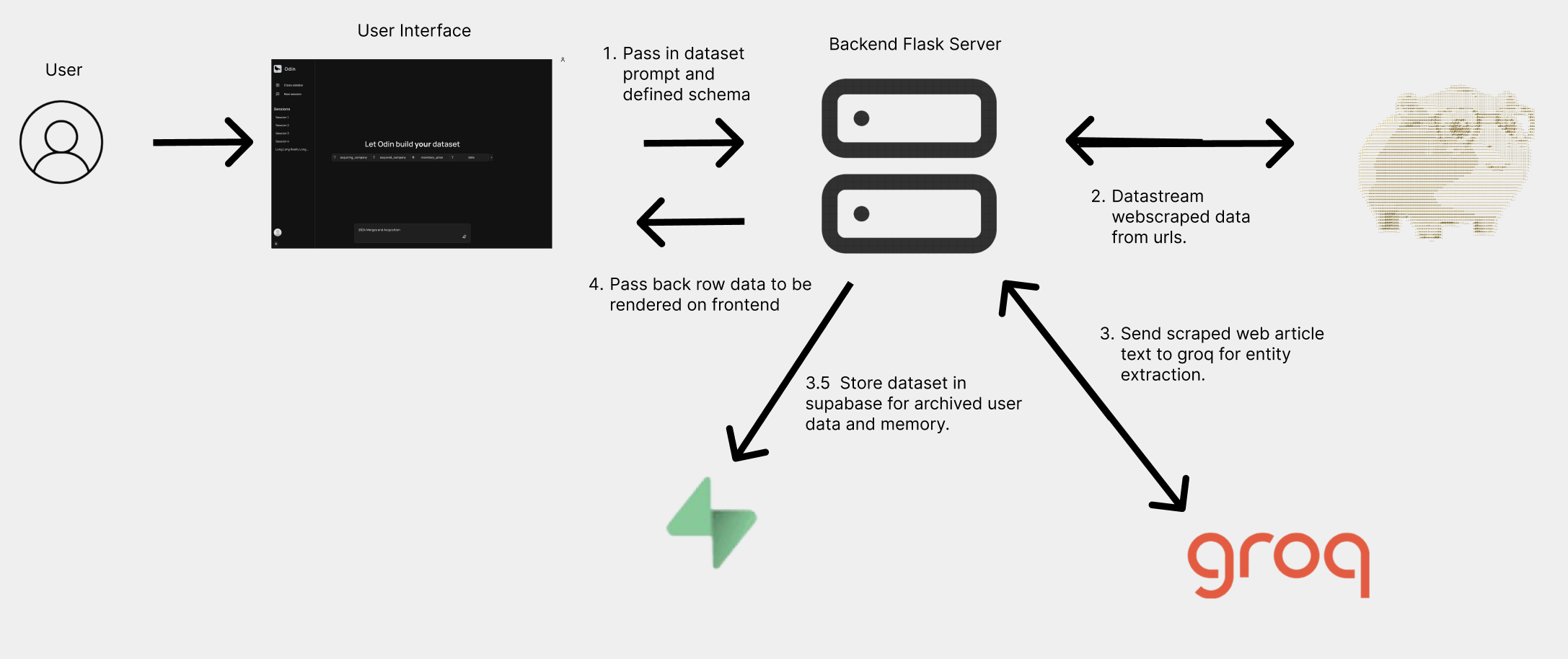
Project architecture
Inspiration
Collecting rich and up-to-date data is often tedious, fragmented, and difficult to scale. High-quality datasets are used everywhere from training ML models, running data analytics, test running small projects on Kaggle, etc, yet hard to retrieve and preserve. We wanted to build a tool that allows users to effortlessly generate structured real-information datasets from a single prompt.
What it does
From a single user-prompt and user-defined schema, our software will scrape the web in realtime and iteratively generate schema-defined row data. This could be anything from "build a dataset of recent merges & acquisitions" to "build a dataset on popular podcasts across the United States in 2010s".
How we built it
We extracted a relevant and recent textual data by using Scrapybara's web scraping abilities on web articles, and streamed it to our groq endpoint to extract quantitative row values out of the textual data.
Backend: Flask, Scrapybara for automated browsing & scraping, Groq for AI-powered entity extraction. Frontend: React for an interactive and dynamic UI. Database: Supabase to store the structured data for each user. Streaming: Real-time data flow from backend to frontend for a seamless user experience using Flask Response DataStream API.
Challenges we ran into
We had to do a lot of prompt engineering towards our Scrapybara instance to run efficiently across the web. Hosting the Flask Datastream across the backend to frontend and rendering components smoothly was also difficult. As we used many tools, calling API across the network came with many different types of access errors and we need to mediate.
Accomplishments that we're proud of
Successfully automating data collection from a simple prompt. Implementing Groq to extract structured insights from raw web data. Streaming enriched data to the frontend in real time. Building a fullstack application that is both functional and scalable.
What we learned
Best practices for ethical and efficient web scraping. Optimizing AI entity extraction for real-world applications. Handling real-time streaming of structured data in a fullstack application. The power of combining automation and AI for dataset generation.
What's next for Odin
Expanding support for more data sources beyond web scraping. Enhancing entity recognition with fine-tuned models. Improving UI/UX for a smoother user experience. Allowing users to export structured datasets in various formats (CSV, JSON, API). Exploring integrations with tools like Google Sheets or Notion for direct data syncing.











Log in or sign up for Devpost to join the conversation.