-
-

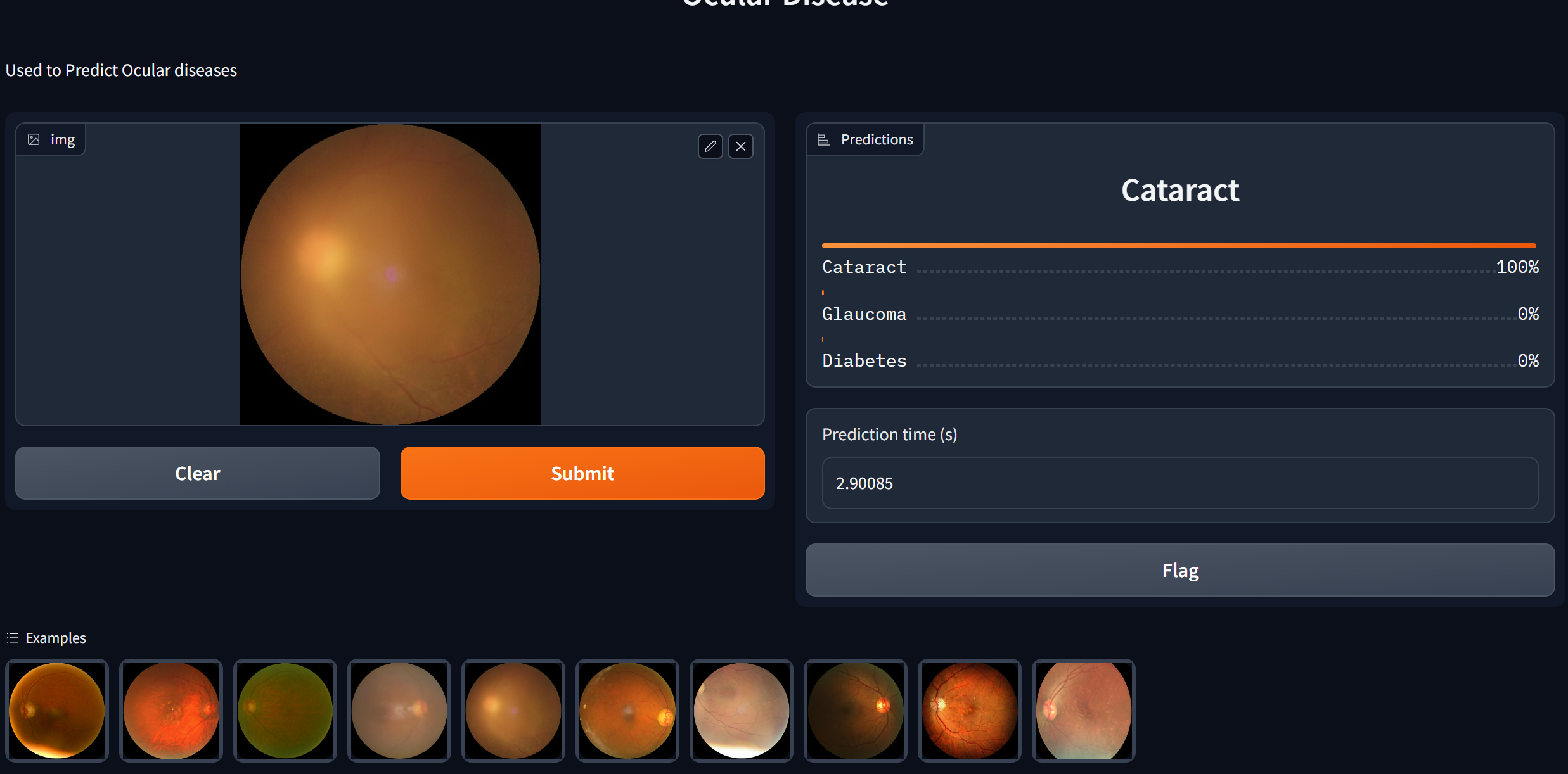
website image
Inspiration
A large amount of the population face issues related to eye health, we wanted to help to tackle this problem by providing a fast, efficient and accurate solution. We learnt that the average accuracy of doctors seeking to recognise these classes of diseases was around 46%, which we believed could be improved upon. This can be helpful especially to individuals who cannot access healthcare services easily.
What it does
Our project allows users to upload images to a portal, which can then predict the likelihood of them having a specific ocular disease. These users can be patients who have potential worries or concerns about their eye health or doctors who want support with their diagnosis process.
How we built it
The project was built using data sourced from Kaggle. This was then cleaned and prepared for the deep learning model. The model was built using PyTorch using the effnet b3 model, which was ranked as the one of the best models for this task. We then built data visualizations using Matplotlib and the confusion matrix, to find where the model was performing poorly to allow us to diagnose it. Lastly we used the gradio package to build a clean user interface to make it easy for patients and doctors to use.
Challenges we ran into
We faced several challenges including elements of the data visualizations, due to an unclean dataset. There were issues with overfitting, the model performed well on the training data but not on the trial data. Data augmentation was experimented with to resolve this problem, however this was computationally expensive. Eventually randomflip was selected for data augmentation - this improved the efficiency without being too computationally expensive, the solution was using larger models and loading pretrained weights. The dataset was also very unbalanced; we had tried to use a weighted cross entropy loss function, however the performance was poor. Therefore we opted for undersampling, allowing our model to reach 81.5% accuracy on the test set and 95% accuracy on the train set.
Accomplishments that we're proud of
- Being able to clean the data, reduced the effect of crashing
- Collaborating together was very exciting
- Working on something which can have a tangible benefit to people, especially people with less access to doctors / healthcare
- Visualizing the results and achieving an effective confusion matrix
- The performance improved from 61% to 81.5% (test set), base performance of a typical doctor is 46% so this can be really beneficial for doctors
What we learned
- How to cooperate as a team and divide tasks that suited individuals to boost efficiency.
- We learned a lot about time management within our individual tasks.
- We learned how to clean and deal with unbalanced datasets.
- We learned effective visualizations, which allowed us to understand the data
What's next for Ocular Disease Multi Classification
If we had more time, we would like to use more diverse data , because the average age was 60 which may lead to bias. We would also want a larger balanced dataset for the model to be able to learn features. We also wanted to build a way for doctors and patients to be able to interpret the model and how it came to those findings.
Built With
- cv2
- gradio
- matplotlib
- monai
- os
- pandas
- pathlib
- pil
- pytorch
- scikit-learn
- seaborn


Log in or sign up for Devpost to join the conversation.