-
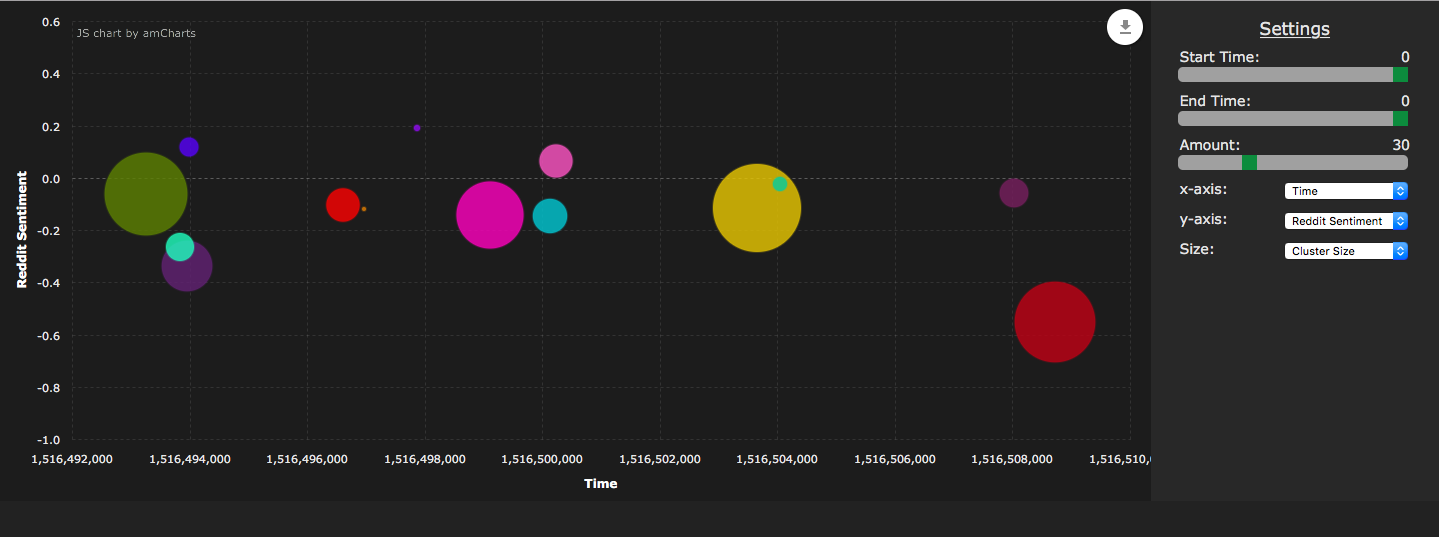
Time span
-
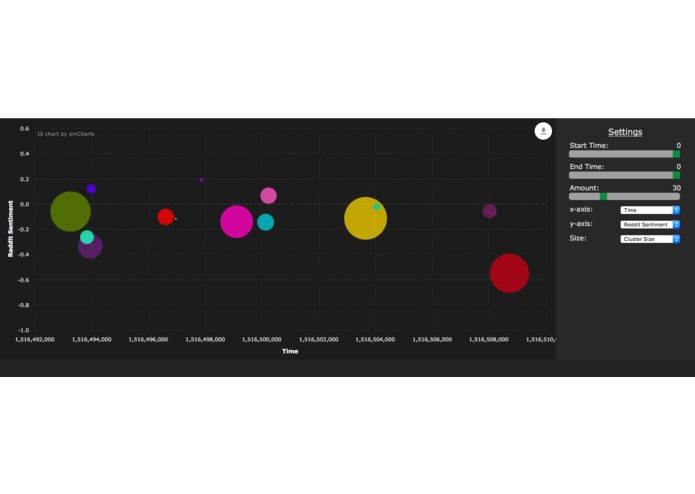
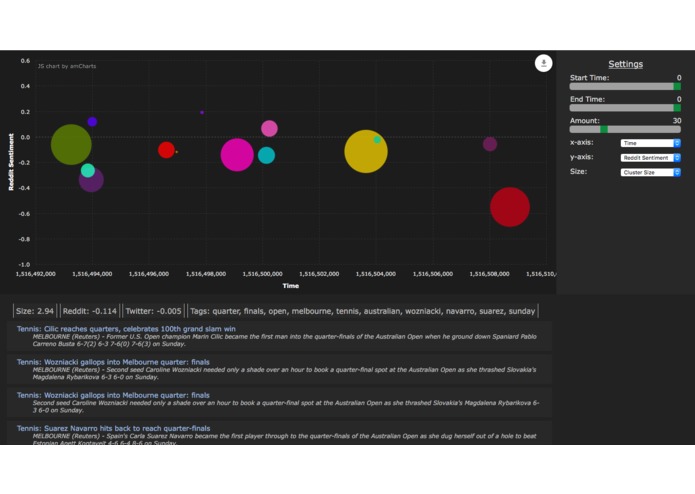
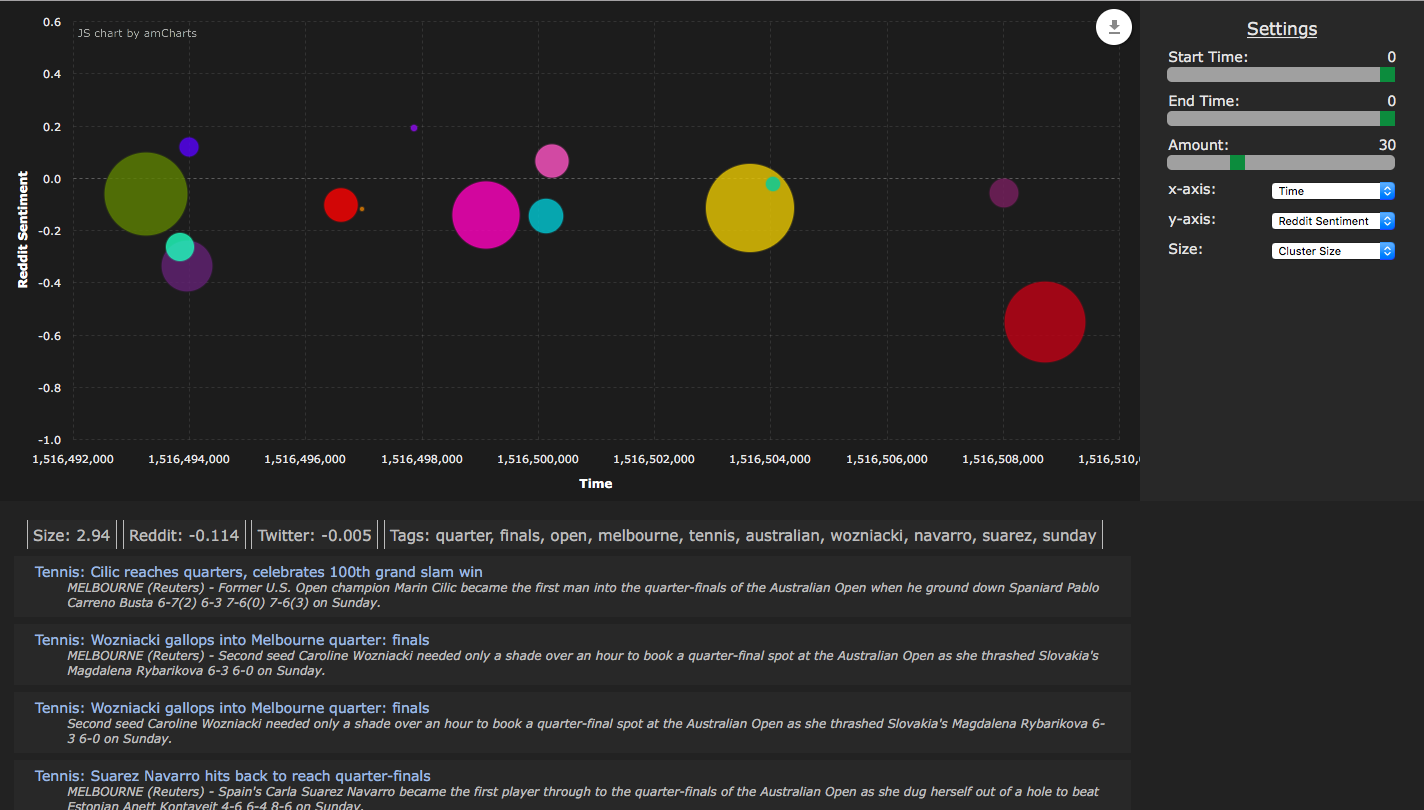
Basic display
-
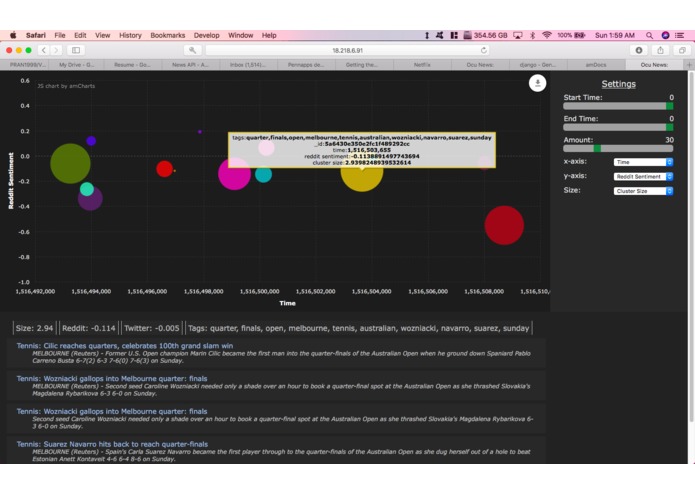
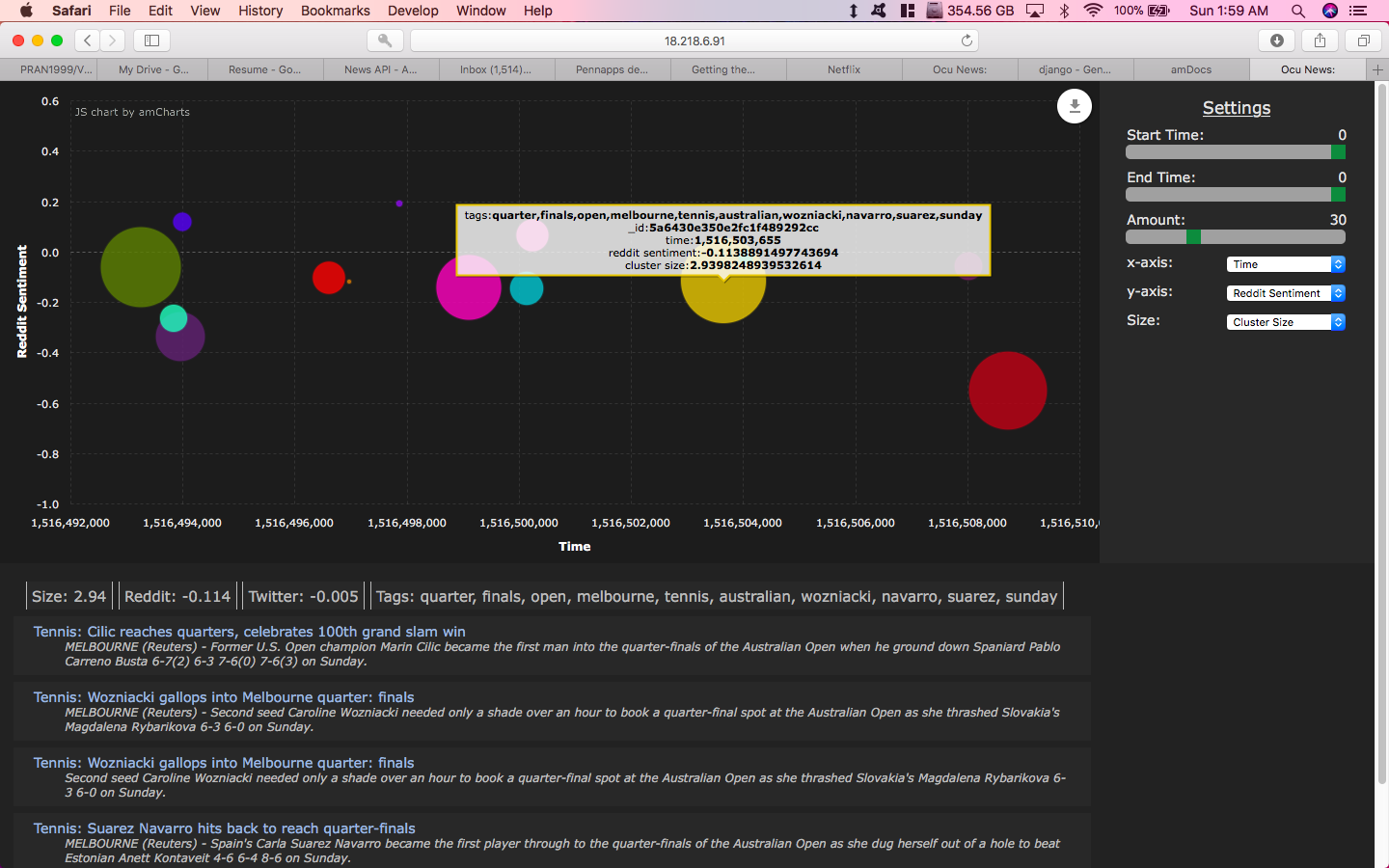
Hovering
-
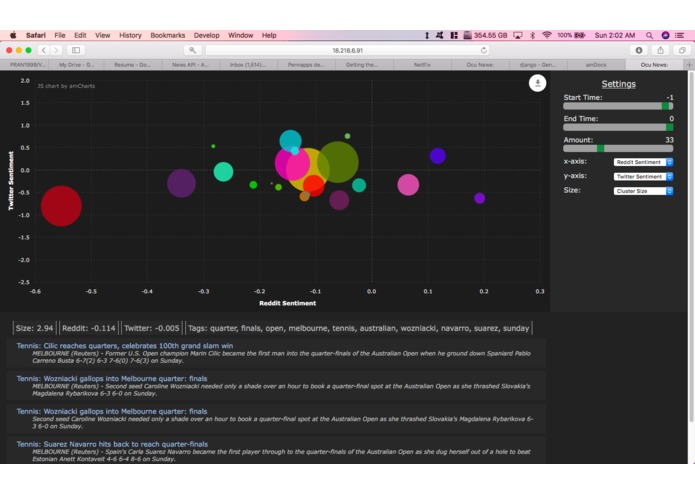
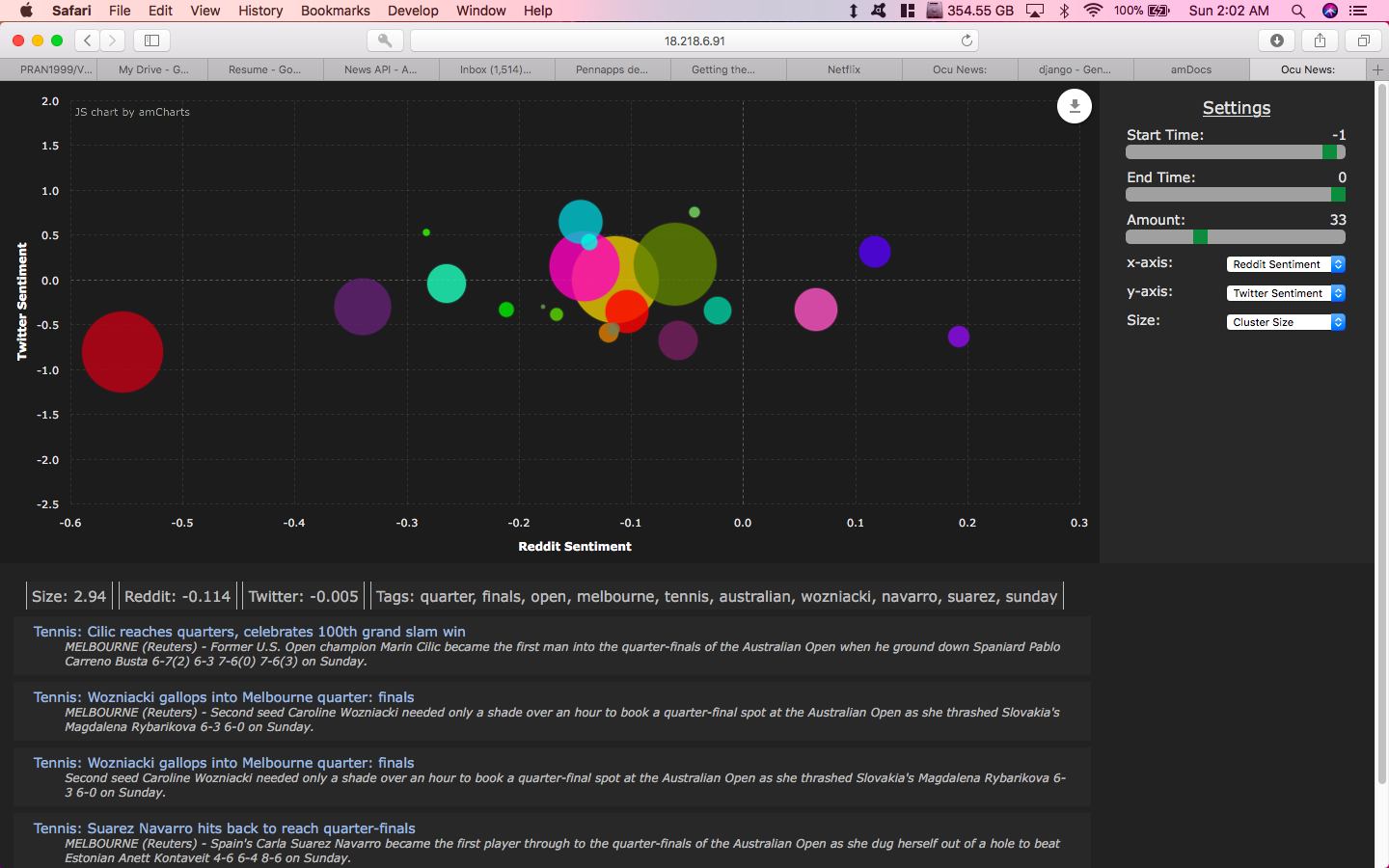
Tennis cluster
Inspiration
In recent years, the impact of 24-hour news and social media has increased greatly. Recent events have accelerated some of that, and it has made it easy to forget about one major incident because another will quickly take its place in our minds. As college students with an interest in looking at the big picture, we decided to try and visualize this data through both the amount of attention it garnered and the reaction to it on social media. So, OcuNews was born, and we hope it will help us understand the patterns and trends that drive today’s information driven age.
What it does
OcuNews gathers news articles, groups them, then goes through Reddit and Twitter for their “opinion” on the topic of the group. This not only allows easy viewing of social media’s take on the event, it also makes it easier to see overall important trends in the news: if just one outlet is publishing a story about an event, chances are it is not consequential overall. The app also displays the clusters through the interface implemented through Flask which graphs the data however the user specifies.
How I built it
The project is actually two separate processes that are only connected through the use of the same MongoDB database. On the client-side, a combination of Flask, JQuery, and AmCharts helps construct the interactive graph that we use to display the data. All data is pulled from MongoDB through the use of AJAX calls. The backend is built entirely in Python and relies on unsupervised machine learning to aggregate news data and cluster them according to certain keywords. Additionally, tf-idf protocols and sentiment analysis is used to analyze social media data from both Twitter and Reddit and assign a general public reaction to a topic. This data is then periodically written to MongoDB to be pulled as needed. All news data is pulled from the NewsAPI, all tweets from the Twitter API, and all Reddit comments from the Reddit API. Sklearn libraries are used to perform the k-means clustering while VaderSentiment provides the sentiment analysis.
Challenges I ran into
Gathering general events from news descriptions –– For one, it would have been difficult to write individual parsers for each news source we wanted to scrape from (assuming we wanted the full article). However, as it turns out, KMeans clustering is better for smaller documents since TF-IDF Vectorization essentially calculates text-similarity (which is better for smaller documents as opposed to larger ones), so we ended up using KMeans to cluster our documents. Analyzing the data –– we wanted to cluster documents so that documents in the same cluster pertain to the same/similar events. This was particularly difficult because it is not easy to determine an “optimal” number of clusters. Since this would’ve taken far too long and derailed us from actual progress, we decided to stick with 30 clusters since that seemed to provide the best overall clustering results. Appropriately visualizing data (such that it is not too dense yet not too sparse –– we wanted the data to actually take on it’s own meaning)
Accomplishments that I'm proud of
Having a completely working version of the app (and having it look good)! We're also really proud of the having implemented sentiment analysis and machine learning to obtain relevant information about social media and the news.
What I learned
In addition to learning more about python, flask, mongoDB, aws, we learned that spending time coming up with a complete idea and communicating a lot while building the app is very beneficial. Instead of wasting time finishing extemporaneous features, it’s much better to get a working proof of concept first; that way, if you find something is going to be much more difficult that anticipated, there is time to adjust the project.
What's next for OcuNews
There are a lot of different news sources that are not included in the current version of OcuNews. With more sources we can get a better overall sense for what official news outlets are saying. In addition, the clustering algorithm should be able to learn and incorporate user feedback for articles that are definitely linked. This would improve the grouping algorithm and better show trends in the media. Finally, with more data and user inputs, the events can be clustered by time and ultimately show cause and effect relationships between events going on in the world.
Built With
- amazon-web-services
- amcharts
- css
- flask
- html5
- javascript
- jquery
- mongodb
- python
- sentence-analysis
- sklearn
- tf-idf-vectorization



Log in or sign up for Devpost to join the conversation.