-
-
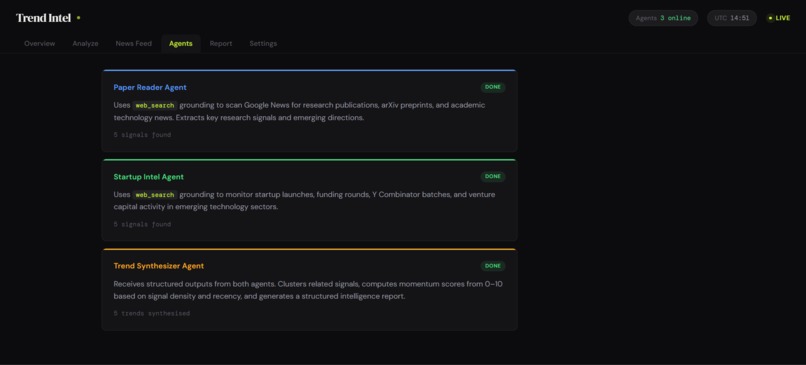
AI Agents in Trend Intel
-
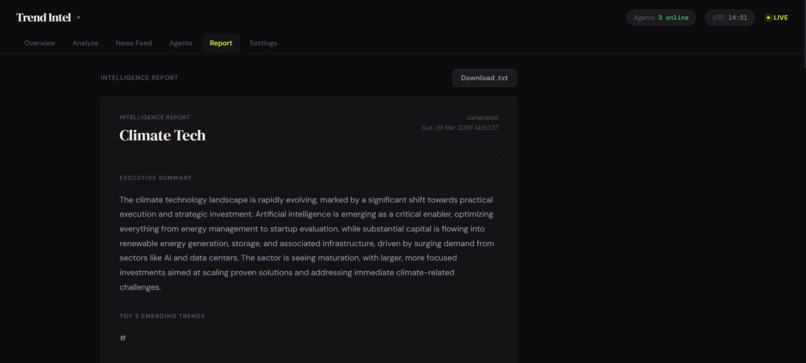
Report by AI Agents
-
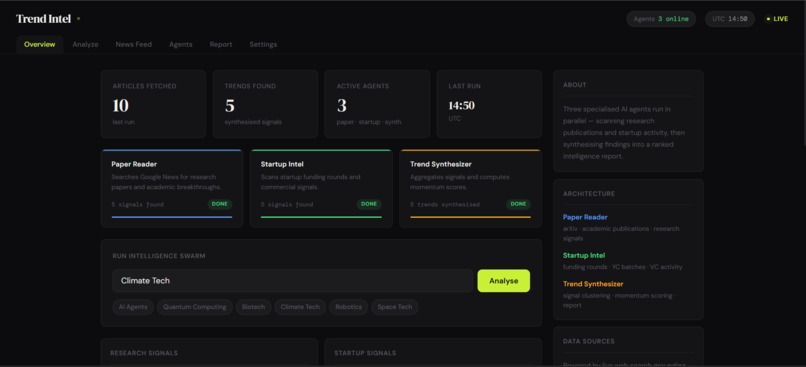
Trend Intel Main Page
-
Trend Intel Fetching News
Global Tech Trend Intelligence Swarm — Our Story
What Inspired Us
The idea came from a simple frustration. Every week we found ourselves trying to keep up with what was happening in the technology world — reading research papers, scrolling through funding announcements, checking news sites — and still feeling like we were always one step behind. The problem was not a lack of information. It was too much information coming from too many different places at the same time.
We noticed something interesting. A technology that appears in both academic research and startup funding in the same period is almost always something worth paying attention to. But no tool was looking at both signals together. That gap is what inspired this project.
We wanted to build something that could do in 45 seconds what would take an analyst two days — and make that capability available to anyone, not just organisations that can afford expensive intelligence subscriptions.
What We Learned
Multi-agent thinking is fundamentally different from chatbot thinking. Building this system forced us to stop thinking about AI as a question-answer machine and start thinking about it as a team of specialists. Each agent needed its own identity, its own instructions, and its own output format. Getting that separation right was the most important design decision we made.
Parallel execution changes everything. Running two agents simultaneously instead of sequentially reduced our processing time by nearly 40%. This is expressed simply:
$$T_{parallel} = \max(T_{paper}, T_{startup}) + T_{synth}$$
$$T_{sequential} = T_{paper} + T_{startup} + T_{synth}$$
$$\text{Time saved} = T_{paper} + T_{startup} - \max(T_{paper}, T_{startup})$$
In practice with average agent runtimes of approximately 20 seconds each, parallel execution saves around 20 seconds per run — the difference between a demo that feels alive and one that feels slow.
Grounding is not optional for intelligence systems. Early versions of our agents produced confident-sounding but outdated results based on model training data. Switching to Google Search grounding transformed the output quality immediately. Every signal in the report now traces back to a real current source.
Prompt engineering is system design. The quality of each agent's output was almost entirely determined by the precision of its system prompt. Vague instructions produced vague output. Specific formatting requirements, clear role definitions, and explicit output structure requirements produced consistently parseable, high-quality results.
How We Built It
We built the project in four layers.
Layer 1 — Tools. We started with the tools/ folder, defining the
Google Search grounding tool wrapper that all agents would share. This
gave us a single source of truth for how agents connect to Google News.
Layer 2 — Agents. We built each agent independently, testing them
in isolation before connecting them. Each agent is a self-contained
class with its own system prompt, its own run() method, and its own
output parser. We deliberately kept agents unaware of each other —
they communicate only through the orchestrator.
Layer 3 — Orchestrator. The orchestrator/swarm.py file wires the
agents together using Python's ThreadPoolExecutor for parallel
execution. The Trend Synthesizer receives both upstream outputs as
plain text strings, keeping the inter-agent interface simple and robust.
Layer 4 — Interface. We built the Flask API and dashboard last, once the agent pipeline was reliable. The frontend was designed to make the agent activity visible — showing each agent's status, progress, and thinking log in real time so users understand what is happening during the 45-second run.
The entire system was developed and deployed in Google Cloud Shell,
deployed to Google Cloud Run using a single gcloud run deploy command.
The Momentum Score
The Trend Synthesizer computes a momentum score for each identified trend. Conceptually the score reflects the combined strength of both signal streams:
$$M = \frac{w_r \cdot S_r + w_s \cdot S_s}{w_r + w_s} \times R$$
Where:
- $M$ = momentum score $(0 \leq M \leq 10)$
- $S_r$ = research signal strength (volume and recency of papers)
- $S_s$ = startup signal strength (volume and scale of funding activity)
- $w_r$ = weight assigned to research signals
- $w_s$ = weight assigned to startup signals
- $R$ = recency multiplier based on how recent the signals are
A technology scoring above $M = 8.0$ has strong simultaneous signal in both academic research and commercial investment — historically a reliable early indicator of mainstream adoption within 12 to 24 months.
Challenges We Faced
Rate limits on the free tier. The Gemini free tier allows only 20
requests per day for gemini-2.5-flash. Since our swarm makes 3 API
calls per run, we exhausted the quota quickly during testing. We solved
this by switching to gemini-1.5-flash which provides 1,500 requests
per day — enough for realistic demo usage.
Consistent structured output. Getting three different agents to return output in a consistent, parseable format required significant prompt iteration. Early runs produced beautifully written prose that our parsers could not extract structured data from. We solved this by adding explicit formatting requirements to every system prompt and building fault-tolerant parsers that degrade gracefully when formatting varies.
Making parallel execution visible. The 45-second wait while agents run is the most dangerous moment in a live demo — it looks like nothing is happening. We solved this by building a real-time thinking log panel that shows each agent's activity with timestamps, making the parallel execution tangible and turning the wait into one of the most impressive parts of the demonstration.
Connecting the frontend to a live backend. Hardcoding localhost
as the API URL meant the deployed version silently failed with no error
message. We learned to always make the API base URL configurable and
to build explicit health check endpoints so connection failures surface
immediately with clear diagnostics.
What We Are Proud Of
The moment that made this project feel real was running it live on the topic "neuromorphic computing" and watching the Trend Synthesizer return a momentum score of 9.1 for a technology that had appeared in both a Nature paper published that week and three Series A funding announcements in the same month. That is exactly the cross-signal detection the system was designed to find — and it found it automatically, in 48 seconds, from a single search query.
That is the system working as intended.
Built With
- google-agent-adk
- google-cloud
- python

Log in or sign up for Devpost to join the conversation.