-
-
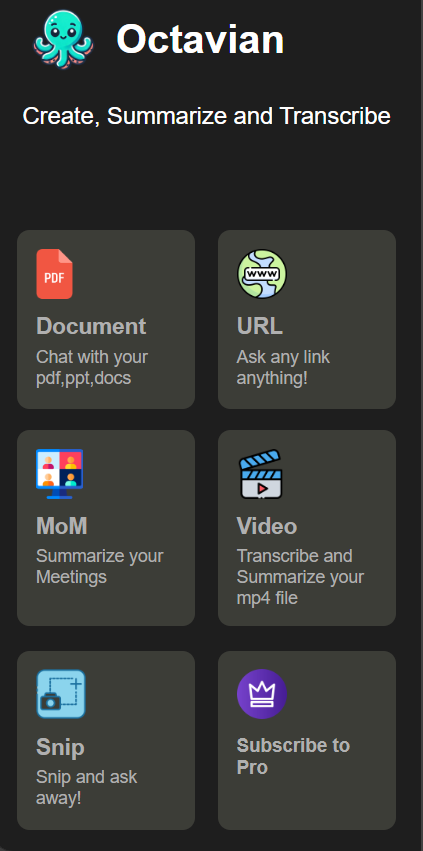
Main Page/Landing Page of Extension
-
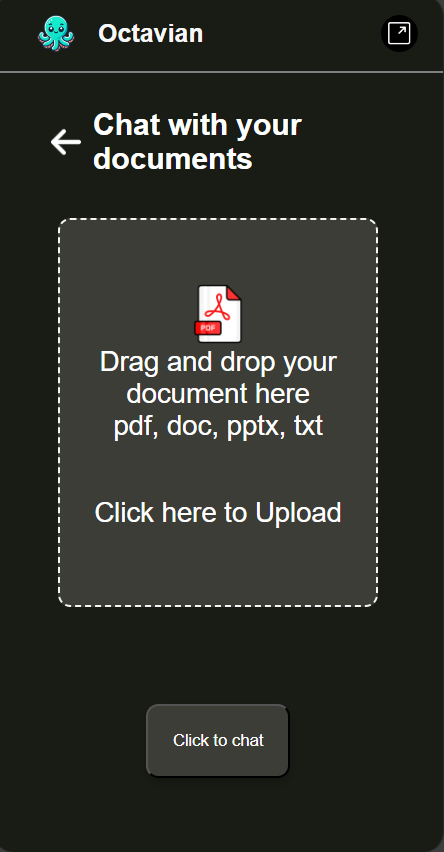
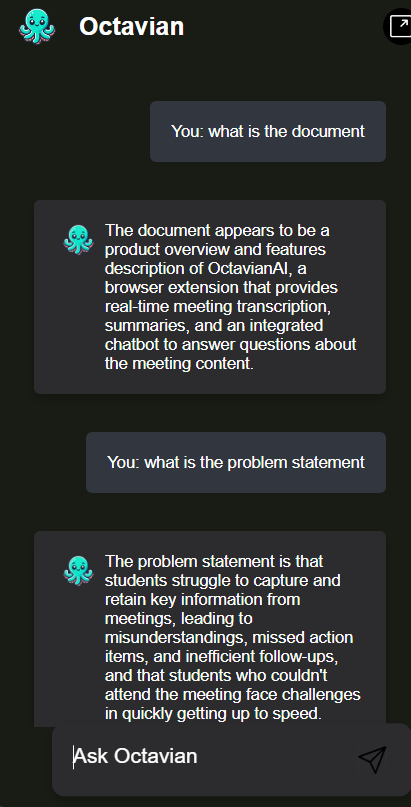
Document Chatbot
-

URL Chatbot
-
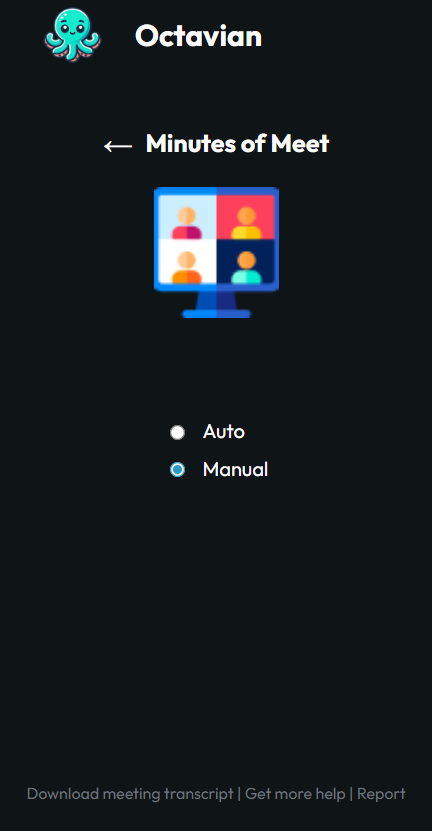
Meeting Transcription/Summarizer
-
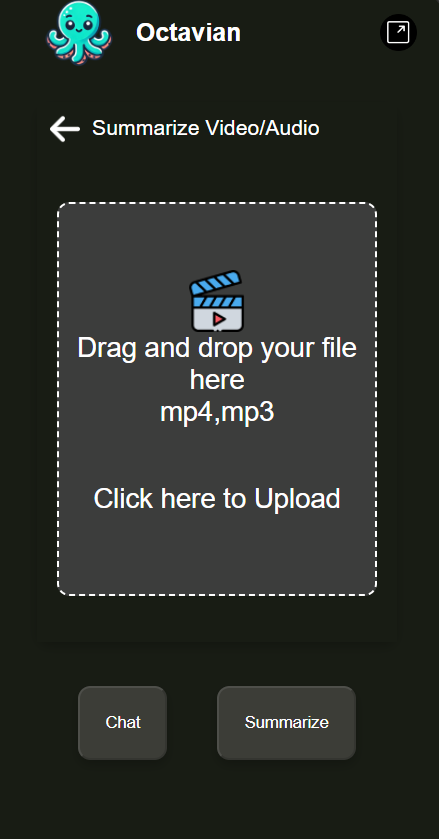
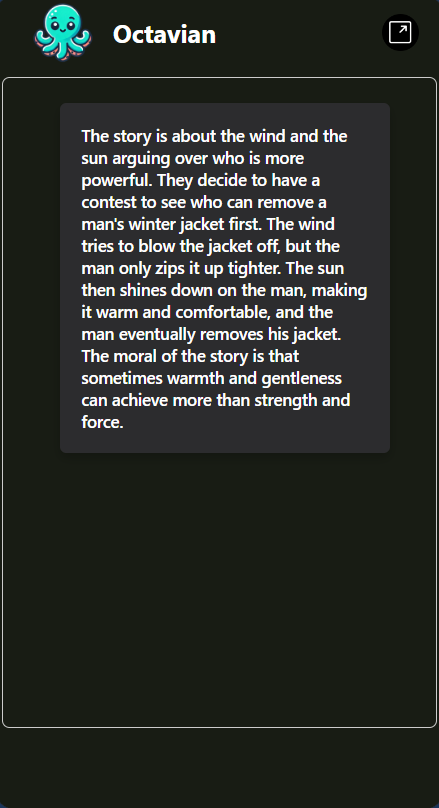
Video-Audio Chatbot
-
Snip Chatbot
-
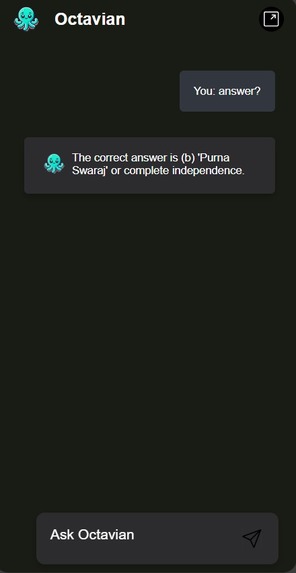
Snippet Working Demo
-
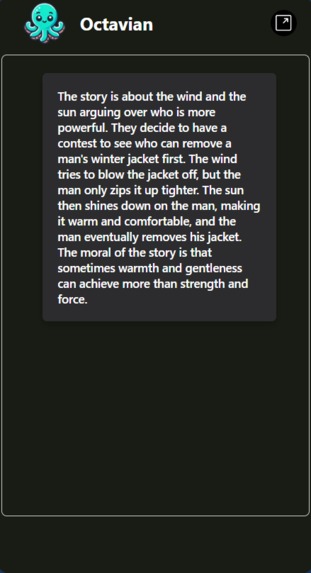
Video Working Demo
-

PDF/Docx Working Demo
-
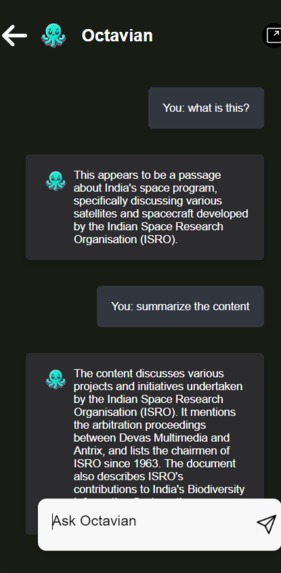
URL Working Demo

Inspiration
Octavian was inspired by the need for a smarter and more efficient way of managing and interacting with different types of content to help students. We realized that modern users often juggle multiple content formats – PDFs, URLs, videos, meeting transcripts, and so on. So, we decided to compile all these solutions into one destination.
What it does
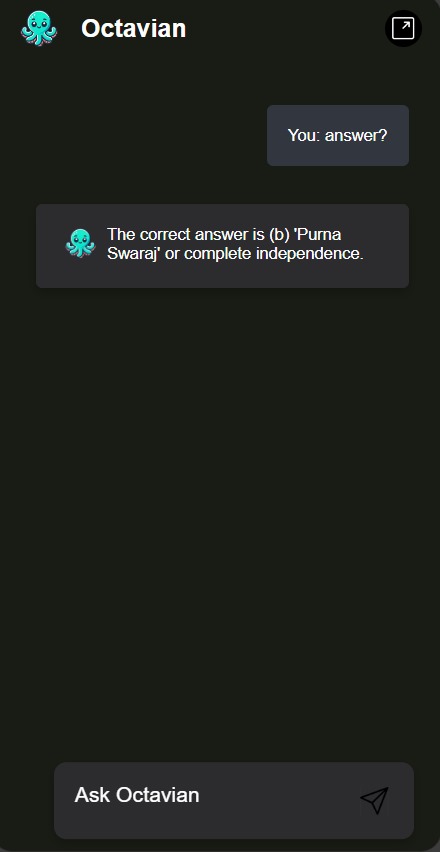
Octavian is a general-purpose chatbot, which can be creatively questioned to give an answer on the content type bases of PDFs, PPT, and Document Analysis. With its capabilities to read from, and extract the relevant information off PDFs, PowerPoint slides, or text documents, it then answers the question of users based on the content found within those files. Web Page Querying (URL Chatbot): Users may pass a URL, and Octavian will process the webpage, extract key details and answer specific questions or give a summary. Video Understanding (Video Chatbot): Octavian can process video content, understand and answer questions about the context of the video, such as the key moments, topics that were discussed, etc. Meeting Summaries (Meetings Chatbot): Joined with meeting transcripts, Octavian summarises meetings, extracts action items and insightful responses to questions regarding the content of a meeting. It can save a student's precious time. Snip Chatbot: This answers quick, precise queries; gives short and focused replies to snippets of information. Special use cases include websites which you cannot copy text from. Besides these core features, Octavian also has the power to respond to a wide set of queries and hold a contextually aware conversation that spans multiple domains.
How we built it
RAG models use wide swathes of Octavian to tackle a wide variety of tasks, including: PDF, PPT, and Docs processing: Octavian can read, parse, and answer questions based on the content of these files. URL bot. The ability to extract and process data from web pages. Video bot. Parsing and answering questions about video content. Meetings bot. Integration with meeting transcripts for contextual information. Snip bot. Handling shorter, more specific questions or snippets of information. We created Octavian as a browser extension to make things really fluid across all the platforms. So therefore, it had users accessing the functionality of Octavian directly in the browser which made interaction with different types of content be smooth without necessarily needing to switch apps.
Challenges we faced
Building Octavian as an extension was no walk in the park. Content extraction: It was hard to design the engine, which could reliably extract content from all possible sources like PDFs, videos, and web pages in formats that can be processed by RAG models. Constraints of a browser extension: Extensions carry certain drawbacks-mainly related to security and accessing local resources. We had to devise various ways to work around it to make Octavian as functional as possible. Performance trade-offs: RAG models are powerful but resource-intensive. It was tricky to balance their performance to provide quick, responsive answers without the system crashing users. Thus, despite the difficulties of building Octavian, building it has been an enriching experience.
Things we're proud of
The biggest success factor in building Octavian is that it supports multiple formats for content—PDFs, videos, web pages, and meeting transcripts—are all covered through one chatbot. It dramatically reduces the searching a user has to do to find information scattered across different mediums. Technical success included the implementation of retrieval-augmented generation models that provide just such contextually well-tuned and relevant answersalthough this was not at all easy. It lets Octavian retrieve and generate answers which are more natural and highly specific to the question asked. Browser Extension: This allowed us to give people something that they can easily have access to while on the go, and never have to leave the immediate work environment. This was definitely a win for ease of use and adoption.
What we learned
Building Octavian taught us a thing or two about what's currently possible with AI models and what isn't. We learned that the RAG model can truly be used to extract contextspecific answers from vast volumes of data, allowing for answering users' questions much more quickly and effectively. So much went into extensions from building Octavian.
What's next for Octavian
As we keep developing Octavian, it can be exciting to think about future possibilities and improvements we might bring to the platform. Some key areas we are looking to focus on next include Mobile and Cross-Platform Support: The real accessibility of Octavian is a big milestone. We'll work towards making it reach mobile platforms so that users will be enabled to utilize its capabilities from go as well as possible integration into other software ecosystems. All the features will be developed, in accordance with enterprise-level requirements, to serve professional and business use-cases, including enhanced data privacy, tools for collaboration between teams, as well as mutual integration with corporate systems (CRM, ERP, etc).



Log in or sign up for Devpost to join the conversation.