-
-
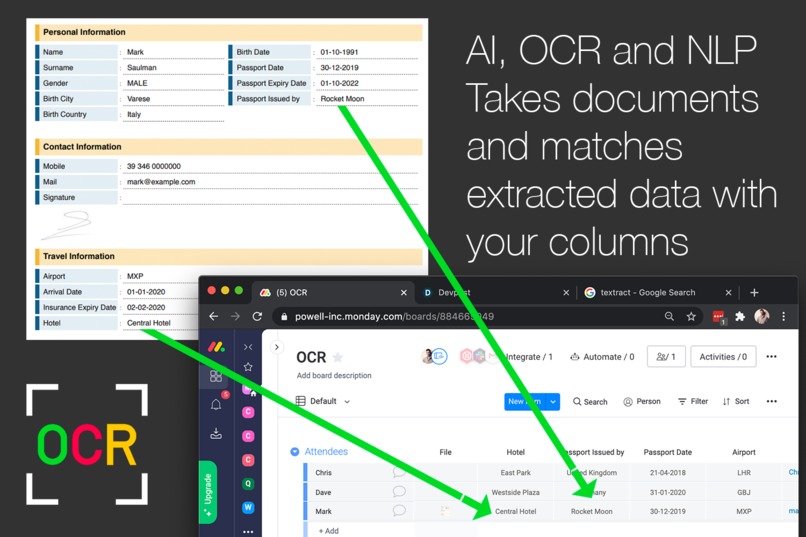
AI Matches and pushes fields across to the correct fields and columns
-

-
Easy to integrate


I am not sure which category this app is suitable for so have submitted to wildcard, but it has uses with creative & marketing, construction and CRM.
Inspiration
Manual data entry from a document is time consuming. There are often cases where you have lots of different types of data coming in and want to get it into a sanitised easy to use board. Here are some example uses cases:
- For Creative and Marketing if you have physically printed surveys that focus groups have used.
- Construction you have invoices and receipts that accompany shipments and deliveries, or maybe you have paperwork from the workers about their insurance, permits to work etc.
- CRM we can have printed forms customers filled in, physical documents like passports, web forms etc. all sources of customer information that we want to bring into one place.
- Finance and billing receipts for expense claims
There are many more but in all of these we have documents that contain data we want to extract. The key objectives we are looking at are:
- I want to be able to extract data from documents be they images, pdfs, text documents etc
- I may have multiple different types of document which contain the same data I want to submit eg. Passport, Driving license for customer info
- I want the correct data to be filled into the correct columns
- I want the process to be as easy as possible
What it does
OCR Populate is an intelligent data extraction tool from documents. It makes everything as simple as possible, simply configuring a recipe and uploading a file. The simplest UI often has the most sophisticated technology underneath to run it. For example Google's search bar is a single text field but understands context so becomes incredibly powerful.
When a user configures a recipe and selects a file column OCR Populate is triggered when any document is added to the column. This follows the following flow:
User uploads a file
OCR Populate is triggered
OCR Reads the document and extracts information which can be using OCR or file extraction depending on the document provided.
OCR Populate analyses the data - firstly looking for clues in the data such as data formats like emails, dates and labels.
OCR Populate - Then it looks at data formats such as if the field is a country or a name etc and classifies the data using AI.
OCR Populate then analyses the columns and existing data in your Monday board to establish data matches
OCR Populate then adds the information to the monday board.
User sees the data fields added to the board
A key aspect is that the user does not have to handle any data mapping and can upload different documents and images by item. For instance if we have a passport uploaded for one row and then a driving license for the next OCR Populate will extract both and map them to the correct fields.
How I built it
I built it using AWS Lambda, AWS Gateway, Tensorflow, Machine learning to build a recipe script that can process and handle the data extracted and set in Monday.
Challenges I ran into
The biggest challenges were building the ML and NLP so that the system can use machine learning to understand the data and to correctly assign the data. It required me to train the data formats on common data types for classification such as addresses, names, emails, phones etc.
Accomplishments that I'm proud of
I am proud of how fast, easy and flexible the tool is.
- Fast documents can be processed in as little as a few seconds.
- Easy there is no requirements around data mapping and setup is as easy as adding a recipe and uploading a file
- Flexible you can upload different types of documents and different types of documents and images all using the same integration.
What I learned
I learnt that I could deliver a really fast and accurate AI, OCR and NLP that makes the process of capturing data easy.
What's next for OCR Populate
The next stage for OCR Populate is to add a mobile app so you can take AI, OCR and NLP on the go.
Built With
- amazon-dynamodb
- amazon-web-services
- gateway
- lambda
- node.js
- tensorflow
- textract


Log in or sign up for Devpost to join the conversation.