-
-
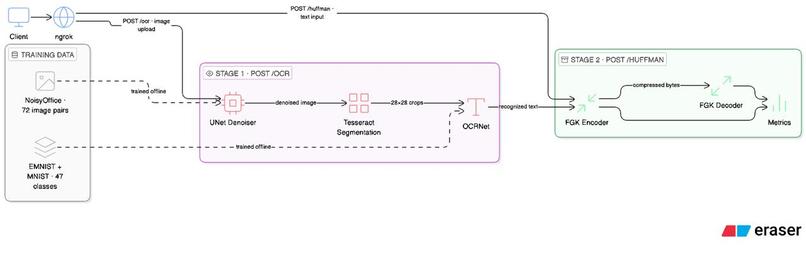
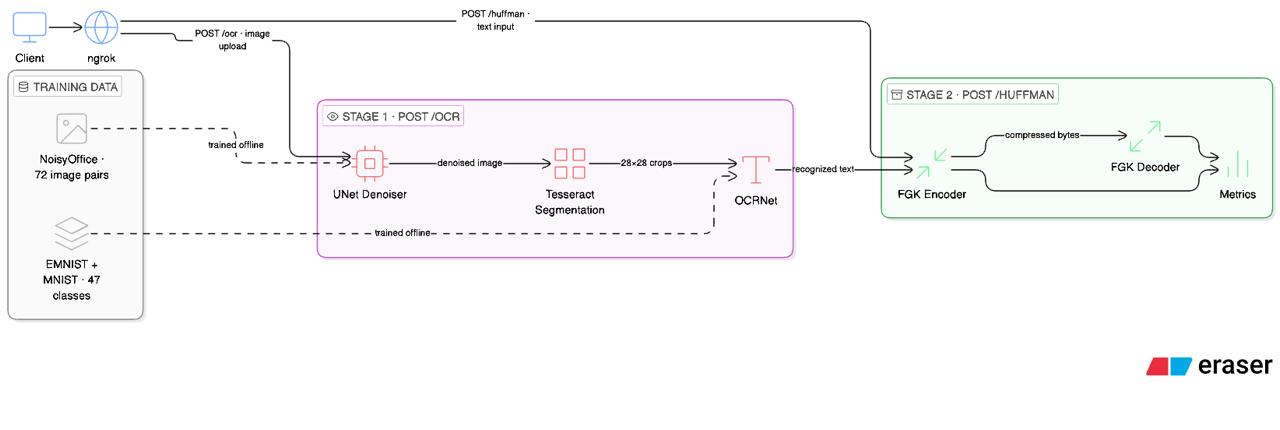
Architecture Diagram
Inspiration
We were handed a case that sounded simple: take a noisy scan, extract the text, compress it, decompress it back. Except the organizers gave us MNIST (digits only, clean) as the OCR dataset and NoisyOffice (printed English text, no transcription labels) as the noisy document dataset. Two datasets that do not fit together the way the brief implies.
That mismatch was the actual problem. Once we spotted the trap, that you cannot train a CNN to emit text directly from NoisyOffice because there are no text labels, the real design started. Every decision in the pipeline flows from that one realization.
What it does
Two microservices that talk to each other. Stage 1 takes a noisy image, runs it through a denoising U-Net, segments characters with OpenCV, and classifies each crop with a CNN trained on EMNIST Balanced (47 classes). Stage 2 takes the resulting string, compresses it with an FGK Adaptive Huffman encoder we wrote from scratch, decodes it back, and returns the round-trip result alongside compression metrics.
How we built it
The denoiser is a U-Net trained on 256x256 patches cropped from NoisyOffice's 72 pages, heavily augmented with flips, rotations, and extra synthetic noise. Patch-based training is what made 72 images workable. PSNR on the test split came in at 33.59 dB, clean enough that downstream segmentation stopped being a concern.
The OCR model is three conv blocks ($1 \to 32 \to 64 \to 128$), BatchNorm, dropout, 47-way softmax. The non-obvious part: EMNIST images are stored rotated 90 degrees and flipped because of how NIST digitized them. Train without fixing that and you get 97% accuracy on EMNIST and zero on anything real. A small transform at training and inference time fixed it. Final accuracy was 97.04% clean, 96.86% under Gaussian noise ($\sigma = 0.15$), and 96.81% under salt-and-pepper ($r = 0.05$). The noise robustness came almost free from augmentation during training.
The Huffman encoder was where the night got long. FGK maintains a sibling property across the tree after every symbol update, swapping nodes to preserve the invariant before incrementing weights. The encoder and decoder stay synchronized on identical tree state, so no frequency table ever goes on the wire. Wire format is a 4-byte original-length header followed by the packed bitstream. Four metrics are reported per request:
$$H = -\sum_s p(s) \log_2 p(s) \qquad L = \sum_s p(s) \cdot \ell(s) \qquad \eta = \frac{H}{L} \qquad r = \frac{\text{original bytes}}{\text{compressed bytes}}$$
Challenges we ran into
The spec said "noisy scanned document" and gave us MNIST. We spent the first hour convinced we were misreading it. Accepting the mismatch and designing around it, rather than fighting it, was the unlock.
The FGK implementation had a swap bug that only appeared after about 50 bytes on specific symbol distributions. Encoder and decoder would silently desync and every byte after the 40th decoded to garbage. Property-based round-trip tests caught it immediately. Without them we would have shipped broken code.
Short-input compression is also genuinely weak. The 4-byte header and per-symbol literal escapes dominate on strings under about 20 characters, pushing the ratio below 1x. This is a known property of order-0 adaptive coders, not a bug, but it is not the number you want on a results slide.
Accomplishments that we're proud of
Training a denoiser on 72 images and having it work. Implementing FGK Adaptive Huffman correctly from scratch, with 100% lossless round-trips across 11 property tests. Catching a subtle tree-sync bug before the demo because we wrote tests as we went. And being honest about the compression numbers instead of hiding the short-string cases behind a single cherry-picked result.
What we learned
Read dataset metadata before writing any code. Write property tests alongside the implementation, not after. And if your results have a known weakness, explain the math behind it.
What's next for OCR Huffman Pipeline
Joint fine-tuning of the denoiser and OCR so the denoiser learns to preserve the features the classifier actually needs. A Burrows-Wheeler transform in front of the Huffman coder for longer inputs to push compression ratios higher while keeping the no-libraries constraint. Broader noise coverage beyond NoisyOffice's four categories, including motion blur and JPEG artifacts.

Log in or sign up for Devpost to join the conversation.