-
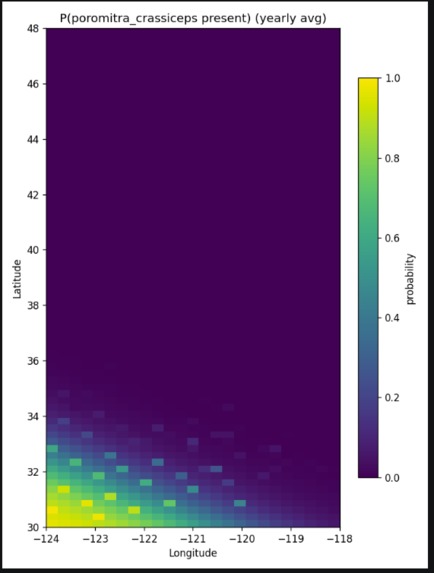
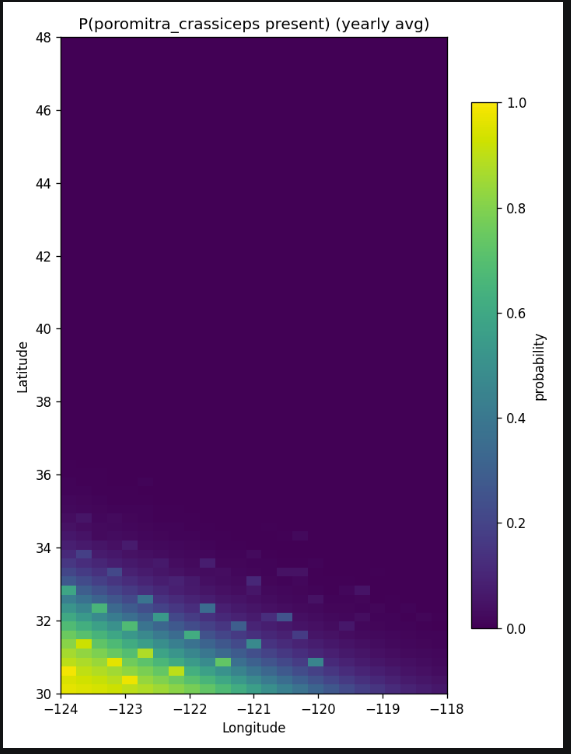
This picture shows the probability distribution of Poromitra crassiceps (a deep-sea bigscale fish)
Inspiration Commercial fishing is one of the oldest industries in the world, yet most fishermen still decide where to go based on experience and instinct. Meanwhile, the California Current is instrumented better than ever — Argo floats, satellites, and coastal moorings generate continuous oceanographic data that's publicly available but completely inaccessible to a fisherman at 5am deciding where to spend the next 12 hours of fuel. OceanIQ was built to close that gap.
What It Does OceanIQ is an AI-powered fishing intelligence platform for the California Current. It pulls real-time ocean data from satellites, autonomous floats, and coastal moorings, runs it through two ML models, and surfaces the results as a dashboard fishermen can actually use. The first model forecasts how ocean conditions will evolve over the next 7 days. The second translates those conditions into species probability scores for 10 commercially significant species. The output is an interactive map showing where fish are likely to be, what conditions look like today versus later in the week, and real-time alerts for anomalous ocean events like unexpected upwellings or low-oxygen zones.
How We Built It We harmonized five independent scientific datasets — NASA MUR SST, MODIS chlorophyll, CMEMS GLORYS12 ocean reanalysis, Argo float profiles, and Scripps' CalCOFI program — onto a shared 0.25-degree daily grid covering the California Current. For species training data we combined CalCOFI larval fish counts, iNaturalist research-grade sightings, and the NOAA West Coast Groundfish Trawl Survey. Model 1 is an ensemble of calibrated XGBoost classifiers, one per species, trained on historical observations joined to ocean conditions. Model 2 is a Prophet time-series model (with a Temporal Fusion Transformer ready for production) that forecasts 7 days of SST and chlorophyll from a 30-day rolling window. At inference time they run in sequence — the forecaster feeds predicted conditions directly into the species model. We also built an Isolation Forest anomaly detector that flags statistically unusual conditions as dashboard alerts.
Challenges We Ran Into Getting five datasets onto a common grid was harder than expected — each came from a different institution, at a different resolution, with a different approach to missing data. MODIS has cloud gaps. Argo floats surface on irregular 10-day cycles. CalCOFI runs quarterly cruises. Every merging decision required careful thought about how much gap-filling was scientifically defensible. The species label problem was equally tricky. Most sources are presence-only — an absence just means no one looked, not that the fish weren't there. Only NOAA trawl zero catches are true confirmed absences. We had to track that distinction throughout the entire pipeline. We also had to use strict temporal holdout validation rather than random splits to avoid leakage from the strong autocorrelation in ocean conditions.
Accomplishments That We're Proud Of The model's species predictions concentrate around known upwelling zones at the right times of year — that's the biology working, not an artifact. We're proud that the science held up. We're also proud of the two-model architecture. Separating forecasting from classification means each model improves independently, uncertainty propagates cleanly, and the system stays interpretable. A fisherman can see not just "high Albacore probability Wednesday" but "because SST is forecast to drop to 14°C and chlorophyll is trending up."
What We Learned The gap between scientific data availability and practical usability is enormous. Every dataset we used is public and free, yet none of it is in a form anyone outside oceanography could act on. Building that bridge turned out to be most of the work. We also learned that domain knowledge matters as much as modeling. The upwelling index, the SST-chlorophyll interaction feature, the 30-day lookback window — none of those came from the data. They came from understanding the biology of the California Current. ML amplifies good features; it doesn't replace the need to understand what you're predicting.
Accomplishments That We're Proud Of The model's species predictions concentrate around known upwelling zones at the right times of year — that's the biology working, not an artifact. We're proud that the science held up. We're also proud of the two-model architecture. Separating forecasting from classification means each model improves independently, uncertainty propagates cleanly, and the system stays interpretable. A fisherman can see not just "high Albacore probability Wednesday" but "because SST is forecast to drop to 14°C and chlorophyll is trending up."
What's Next for OceanIQ The most important next step is the data flywheel — fishermen reporting catches back into the platform, feeding directly into retraining and improving predictions for every user. The more fleets use it, the better it gets for all of them. Beyond that: extending coverage to Oregon and Washington, incorporating ENSO data as a long-range seasonal signal, and deploying the full TFT forecasting model whose attention weights can show fishermen exactly which ocean variables are driving each prediction. The near-term commercial target is fishing cooperatives — groups of 20 to 100 vessels that share costs and information. A cooperative gets fleet-level route optimization and shared alerts that no single boat could generate alone. That's the wedge into the market.Sonnet 4.6
Built With
- accuracy-metrics)-numpy
- argo
- argopy
- calcofi
- cmems
- copernicus
- fastapi
- gbif
- gradient-boosting
- html5
- https
- inaturalist
- javascript
- modis
- modis-chlorophyll
- ncei
- noaa
- nwfsc
- pandas
- pydantic
- python
- roc-auc

Log in or sign up for Devpost to join the conversation.