-
-
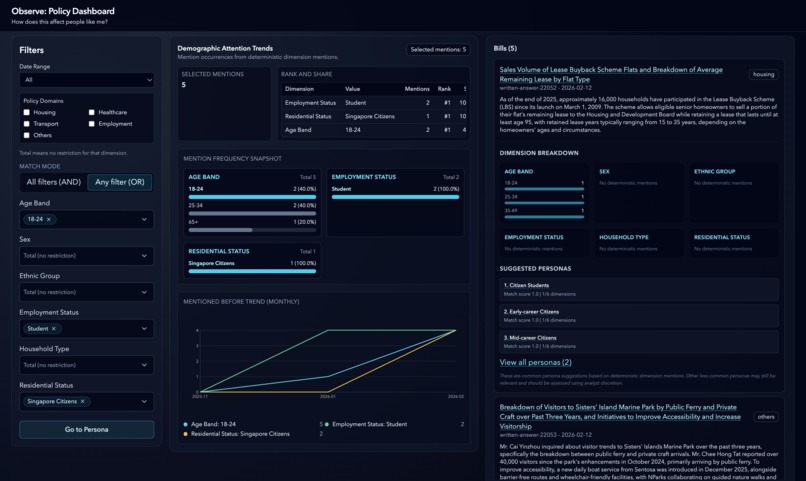
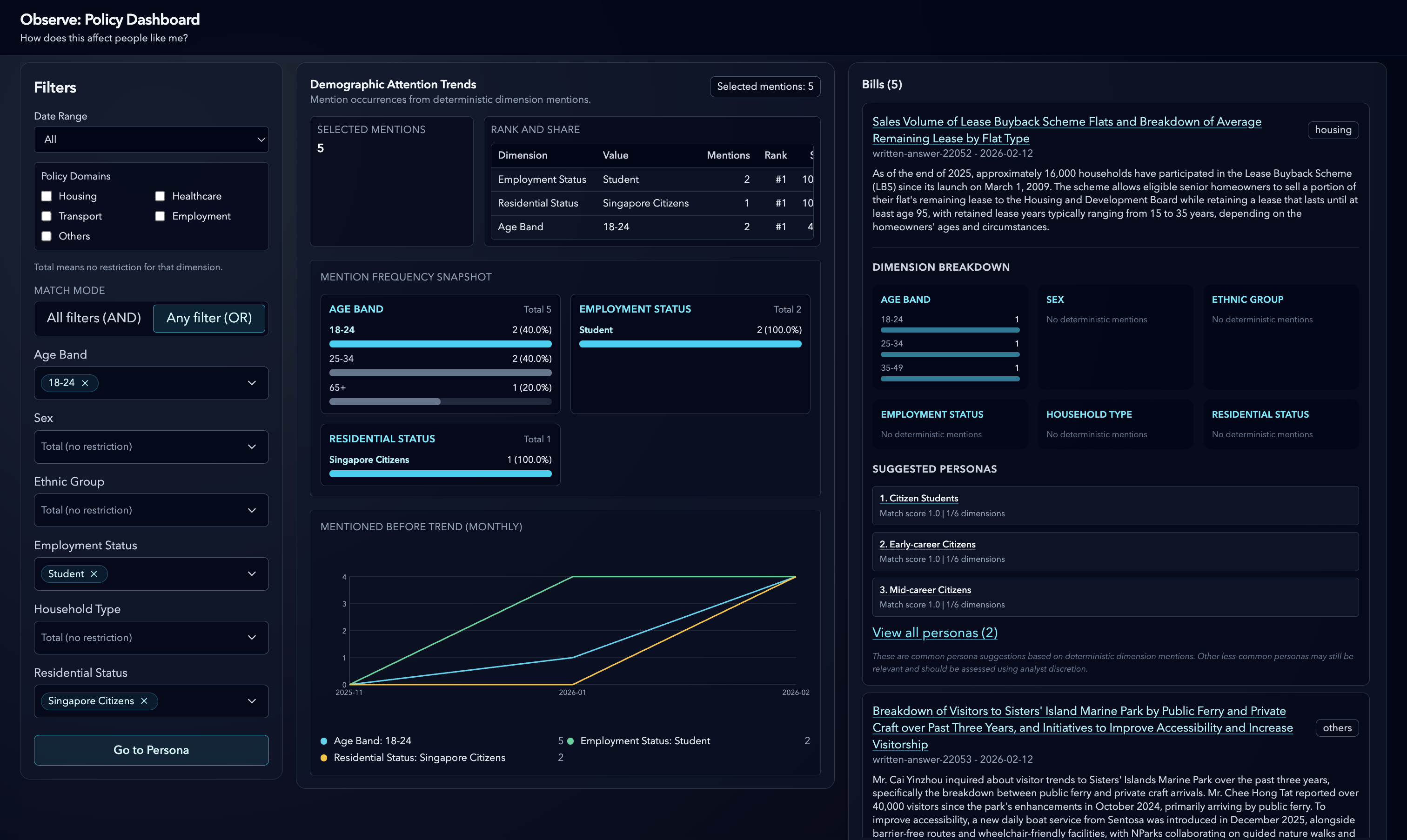
home page aka the landscape view
-
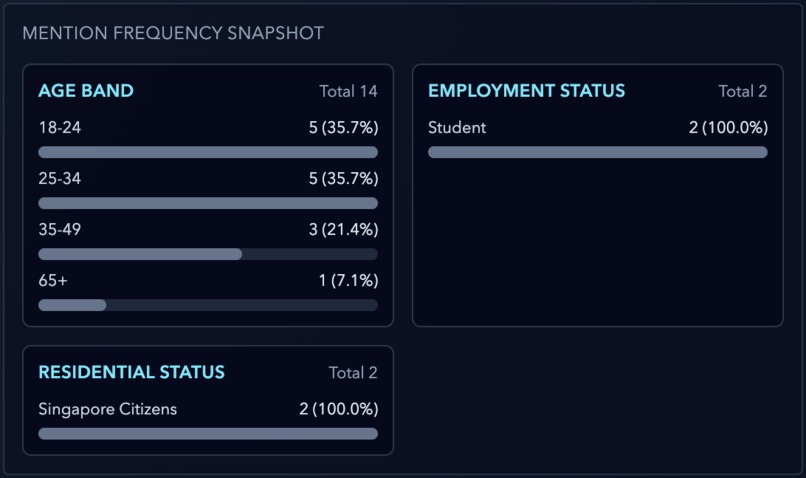
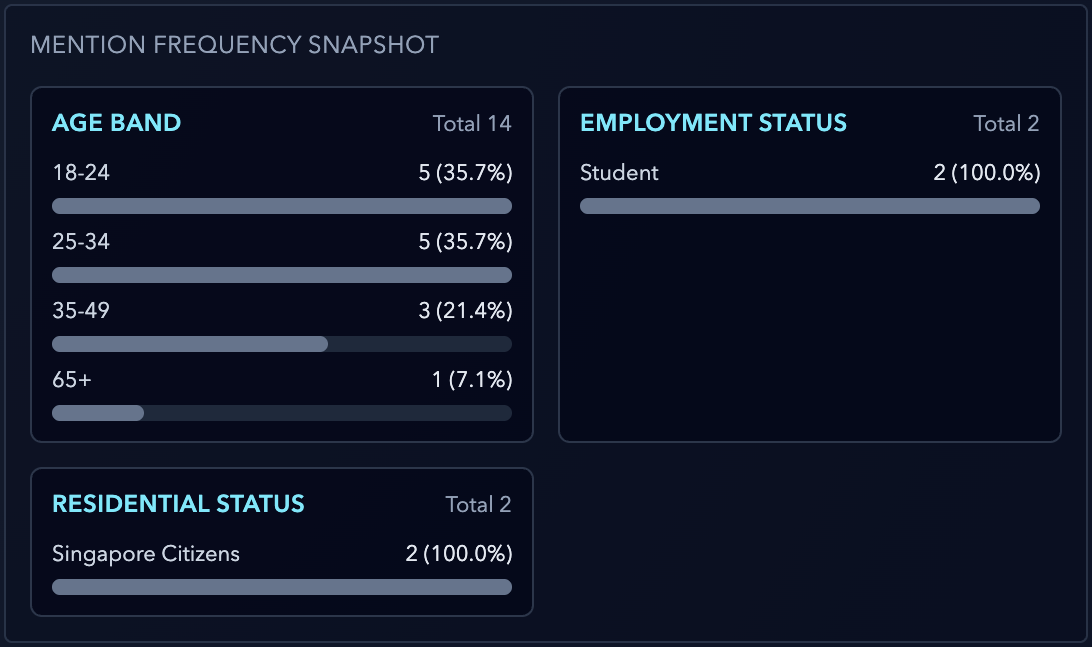
zoom in of snapshot mentions
-
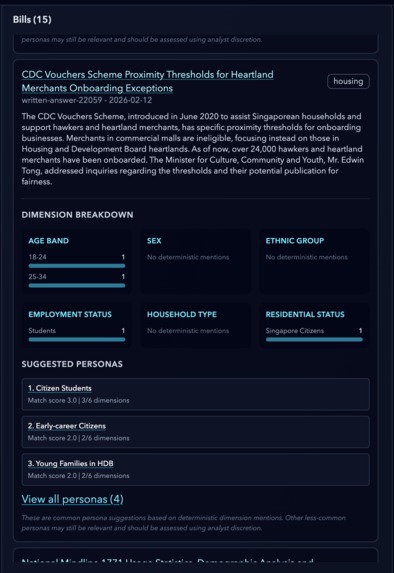
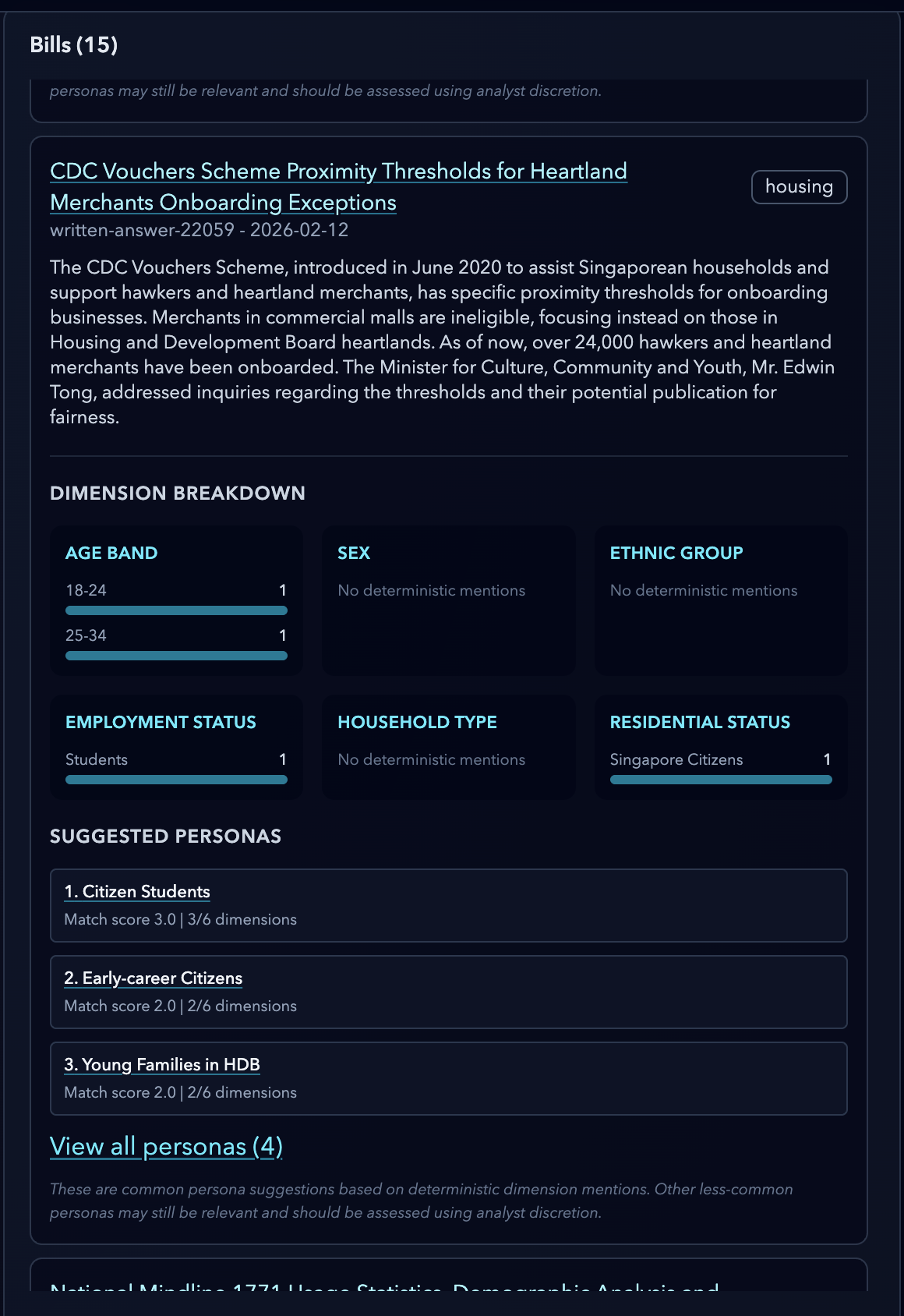
a view of a bill with different affected dimensions/characteristics
-
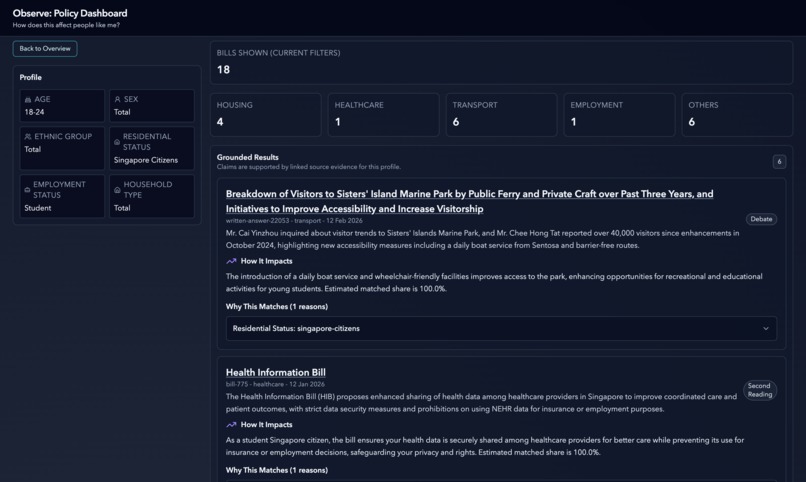
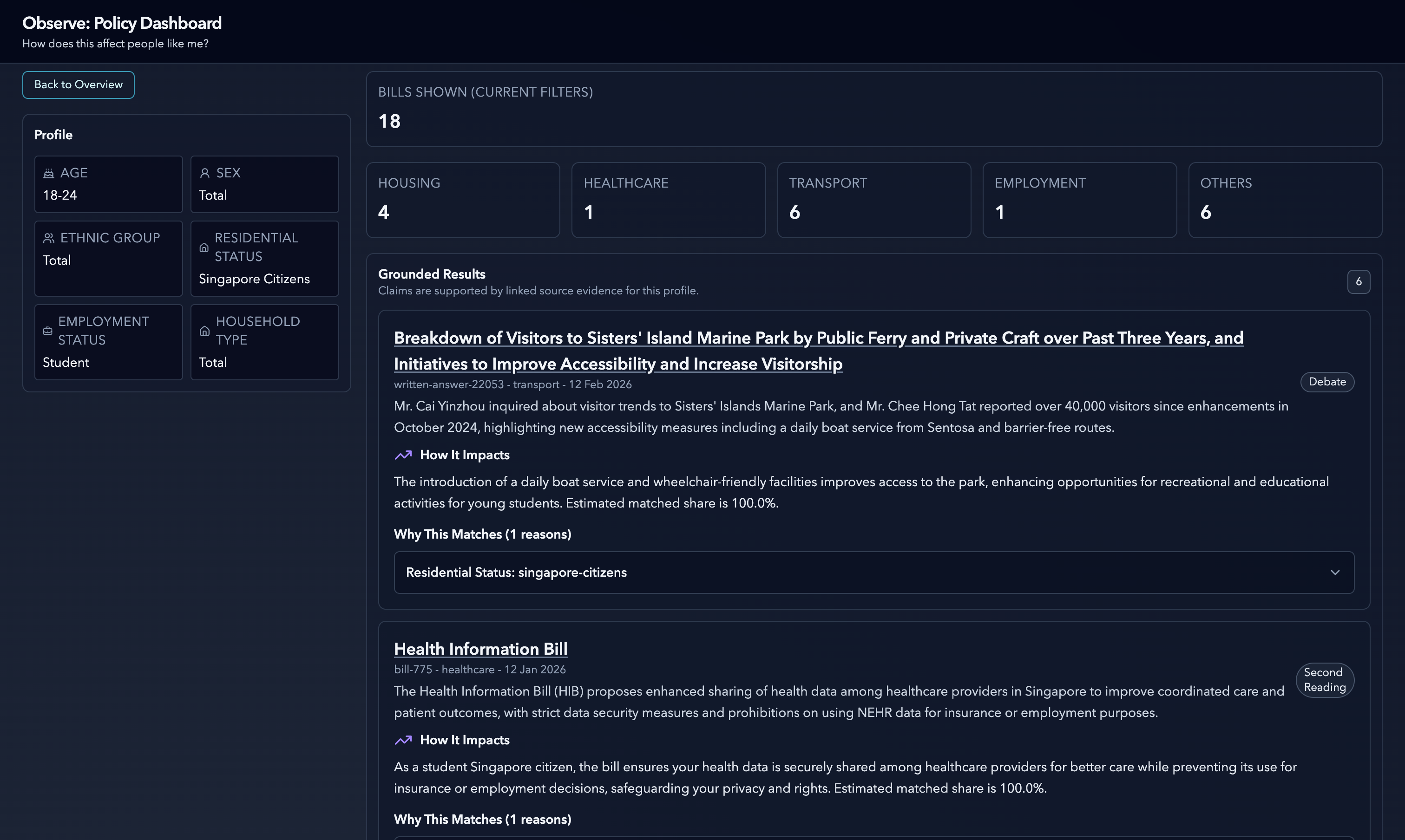
persona page after filter
Inspiration
In Singapore, parliamentary records (Hansard) contain rich information about how demographic groups are discussed in policy and legislation.
However, analysts often:
- Read documents in isolation
- Lack systematic tracking of demographic attention
- Cannot observe demographic attention trends over time
As a result, demographic monitoring is reactive instead of structured. We built Observe: Policy to provide a clear, evidence-backed signal layer across parliamentary discourse.
Selected Tracks: Open innovation track for any high-impact solution (for public good), and Artificial Intelligence and LLM applications.
What it does
Observe: Policy transforms unstructured parliamentary text into structured demographic policy signals.
It allows users to:
- Observe how different personas or characteristics are discussed
- Track demographic attention trends over time
- See policy relevance and likely impact for a selected persona
- Inspect source-backed evidence for transparency and trust
It acts as a demographic policy observability system that aggregates across bills and supports longitudinal persona-policy tracking. For policy analysts, Observe: policy enables demographic monitoring and early detection of attention imbalance. This provide transparency in demographic targeting patterns. It shifts analysis from manual reading to pattern observability.
For this project, the scope is intentionally focused on Second Reading bills and Written Answers. These sources are selected because they contain structured policy intent, ministerial clarifications, and articulated eligibility conditions. By concentrating on these formats, the system reduces noise from broader debate rhetoric and prioritises documents where demographic references are more explicitly stated.
How we built it
I built a hybrid architecture across ingestion, retrieval, synthesis, and dashboard delivery:
- Python ingestion worker normalizes Hansard text into canonical evidence units.
- Redis stores datasets and cached enrichment outputs.
- Go BFF handles persona encoding, pre-filtering, retrieval orchestration, and stable response contracts.
- Go enrichment service generates grounded narrative outputs with guardrails and deterministic fallback. A prewarm worker to fetch common persona to speed up loading time.
- React frontend renders insights and evidence details.
Data flow:
1. Data Ingestion Worker → Redis / Index
- Pulls raw Hansard policy records and normalizes them into canonical policy chunks.
- Runs deterministic NLP rules (age band, sex, ethnic group, employment, household type, residential status) to extract demographic signals.
- Builds evidence units and metadata used for persona-grounded retrieval.
- Materializes datasets into Redis (
dataset:*keys) so downstream services can serve low-latency queries.
2. Policy Enrichment Prewarm Worker → Enrichment Service
- Generates high-value cohort/policy combinations (hot paths) before user traffic arrives.
- Calls the policy enrichment service asynchronously to precompute grounded outputs.
- Enrichment service performs grounded synthesis with evidence checks and writes cacheable results and metadata back to Redis.
- If evidence coverage is weak or generation fails, it stores deterministic fallback-safe outputs.
3. BFF Query Path → Redis First, Service as Needed
- Frontend calls
POST /v1/impact/queryon the Go BFF. - BFF resolves persona input, runs deterministic pre-filtering, and checks Redis for cached grounded or fallback enrichment results.
- On cache miss or stale paths, BFF invokes the enrichment service, validates contract fields (
relevance_decision,grounding_status,impact_summary,evidence_items), and stores results in Redis. - BFF returns a stable response shape so clients can safely render both grounded and fallback states.
4. Frontend Serving Layer
- React frontend uses TanStack Query for request lifecycle management and caching.
- Landscape and Persona pages render the impact summary first, followed by evidence and provenance details.
- URL-driven filters and persona parameters make views shareable and reproducible.
- Frontend gracefully handles
grounding_status = fallback_deterministicwithout breaking user experience.
Pipeline order:
ingestion -> Redis datasets -> prewarm enrichment -> Redis enrichment cache -> BFF contract response -> FE rendering
Methodological Approach
I went with a hybrid extraction model. Considering how policy signals have low tolerance for error, it is important to not entirely rely on LLM. Hence I went for a deterministic method for detecting persona keywords in the policy using rules and structured parsing. LLM / generative AI is used for grounded narrative enrichment, with strict validation (bill_summary, why_you_match with evidence and paragraph and line) and deterministic fallbacks.
Tech stack
- Frontend: React 18, TypeScript, Vite, Tailwind, TanStack Query, Zustand
- Backend (BFF): Go (
net/http) - Backend (Policy Enrichment and Prewarm worker): Go (
net/http) - Persistence layer: Redis
- Data pipeline: Python ingestion worker
APIs used
- Singapore Hansard data source for policy debate content
- OpenAI for structured policy tagging and grounded synthesis, with deterministic fallback when output is invalid or unsupported
Challenges we ran into
- Understanding the target users' needs. I had to change the product direction several times and even the target user because it felt like a naive summarisation tool at the start. Eventually, I landed on signal tool for complementing the analysts.
- The process of chunking took me a while to get it out. But eventually the RAG works well and the paragraph and line are accurately fetched.
- It costs credits to run the LLM.
- Deterministic rules means that there is a need to cover as many keywords and regex as possible.
Accomplishments that we're proud of
- Delivered a working end-to-end system (ingestion -> retrieval -> enrichment -> dashboard), not just a UI prototype
- Implemented evidence-grounded outputs where users can see why a bill matches the persona from the provided excerpt
- Built persona-aware behavior where the same policy can produce different explainable outcomes for different users
What we learned
- Trust and provenance must be first-class product features
- Hybrid deterministic + LLM systems are stronger when fallback paths are explicit and tested
- Clear response contracts speed up frontend delivery and reduce integration risk
What's next for Observe: Policy
- Improve retrieval quality to increase grounded (non-fallback) coverage.
- Extend source and policy-domain coverage.
- Extend beyond Singapore.
Built With
- go
- openai
- python
- rag
- react
- redis
- tailwind
- tanstack
- typescript
- zod
- zustand

Log in or sign up for Devpost to join the conversation.