-
-

ObservAI logo
-
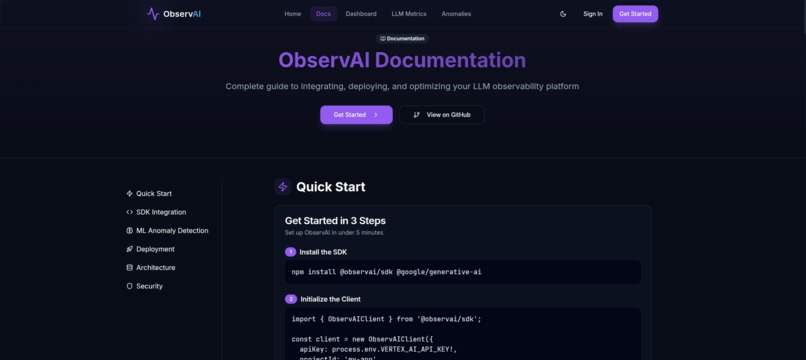
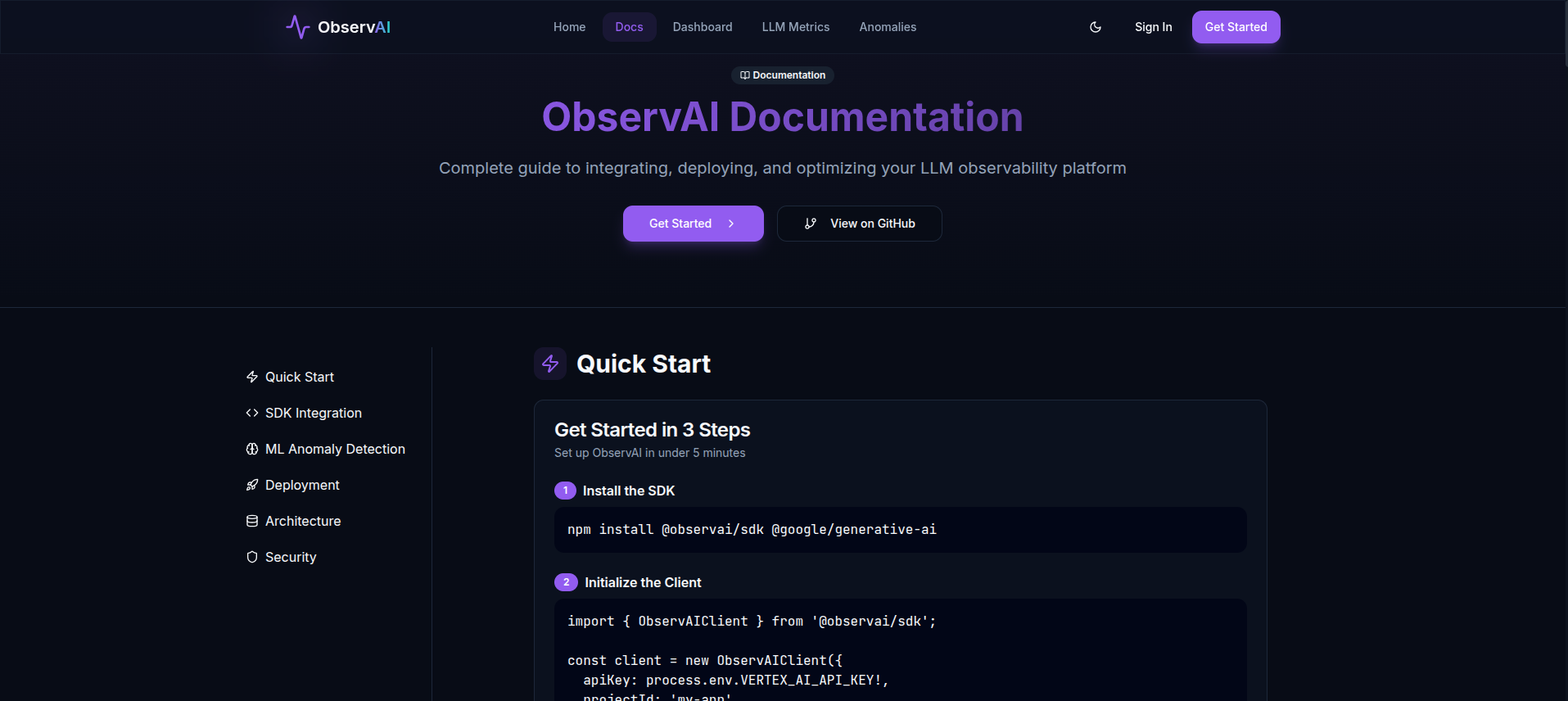
Docs Page
-
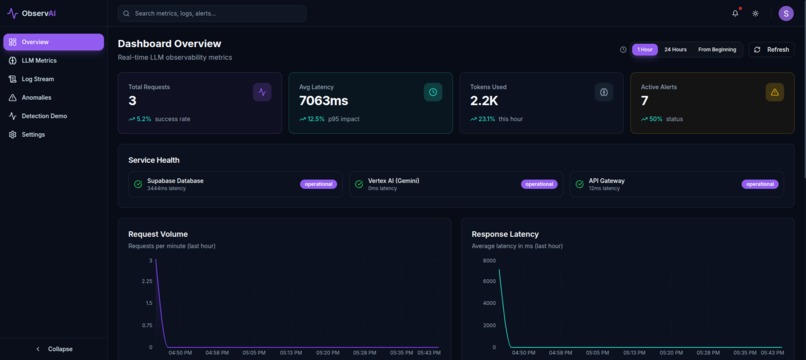
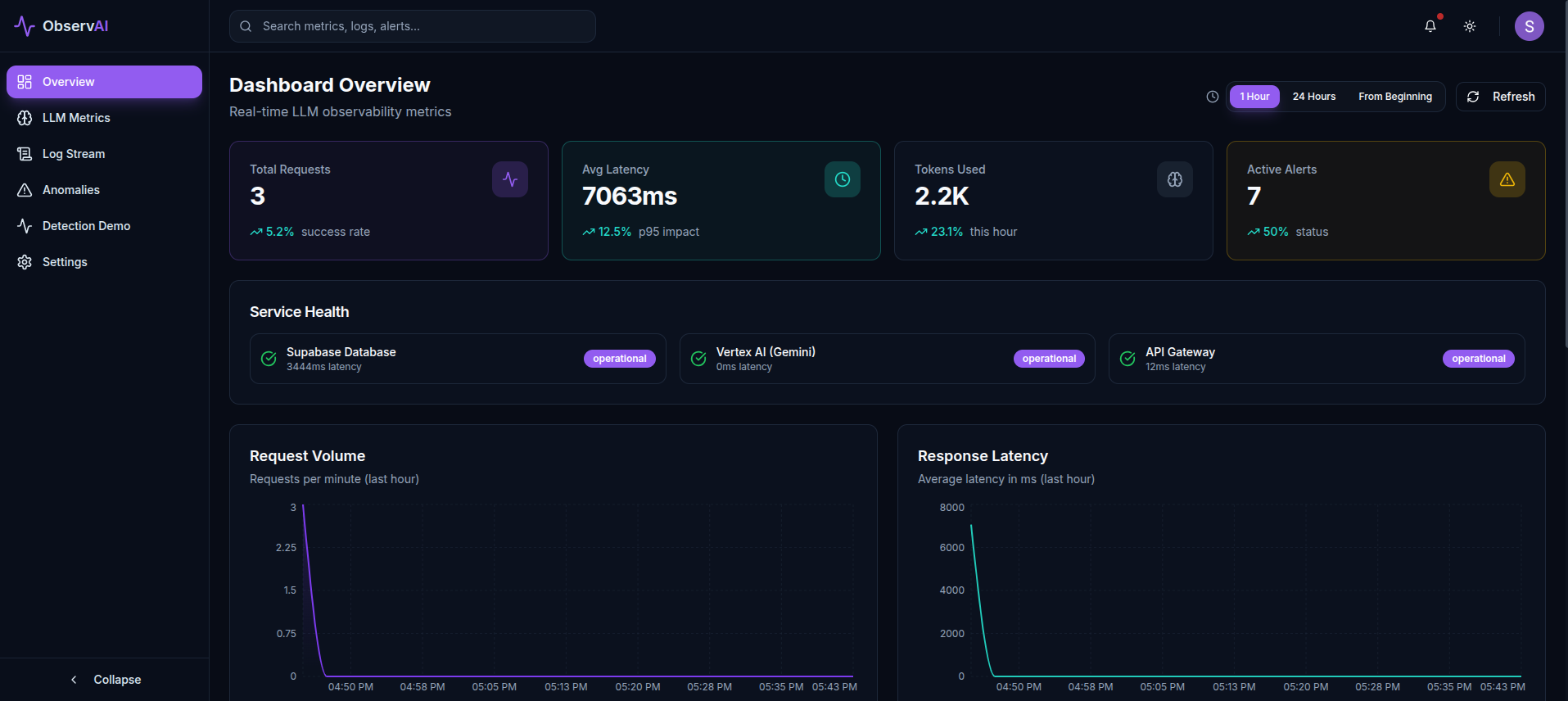
AI Observability Dashboard

🧠 Inspiration
While building production apps with Gemini / Vertex AI, I realized something scary:
LLMs fail silently.
Costs spike without warning, latency drifts over time, and hallucinations creep in — yet most teams ship without any visibility. Traditional observability tools stop at infra. LLMs are probabilistic systems, and they need a new layer of observability.
That gap is what inspired ObservAI.
🚀 What ObservAI Does
ObservAI is a zero-configuration LLM observability SDK for Gemini / Vertex AI.
It acts as a drop-in replacement for @google/genai and automatically tracks:
- 📊 Token usage & latency
- 💰 Real-time cost per request
- 🎯 Quality metrics (coherence, toxicity, hallucination risk)
- 🔄 Session & conversation context
All data is streamed to a backend for real-time analytics and alerts, without changing how developers write LLM code.
🏗️ How I Built It
Architecture overview:
$$ \text{User App} \rightarrow \text{ObservAI SDK} \rightarrow \text{Supabase Edge Function} \rightarrow \text{Postgres} \rightarrow \text{Dashboard} $$
This architecture ensures zero developer friction while enabling deep LLM observability.
SDK Layer
- Wrapped
@google/genai - Intercepted all LLM calls
- Collected metrics (tokens, latency, configs)
- Added batching + retry logic
- Wrapped
Quality Analysis
- Lightweight heuristic + NLP scoring
- Normalized scores between (0 \le x \le 1)
Ingestion Backend
- Supabase Edge Functions
- Batched writes with validation
- Anomaly detection hooks
Demo App
- Next.js frontend
- Simple UI to show why observability matters
- Live metrics displayed per request
⚠️ Challenges Faced
Non-intrusive design
Making observability invisible to developers while still capturing deep insights.Cost estimation accuracy
Mapping token counts to model-specific pricing reliably.Batching vs real-time tradeoff
Balancing latency overhead with efficient ingestion.Quality metrics without heavy models
Avoiding slow or expensive secondary LLM calls.
Each challenge pushed me to think like an infra engineer, not just an app developer.
📚 What I Learned
- LLMs should be treated as production systems, not APIs
- Observability is as critical for AI as it is for backend services
- Small SDK design decisions massively affect developer adoption
- Infra products must optimize for trust, performance, and simplicity
Most importantly, I learned how to design AI-native infrastructure.
🌱 What’s Next
- More models (OpenAI, Anthropic)
- Live dashboards & alerts
- Prompt regression detection
- Team & org-level analytics
ObservAI is built for teams shipping real AI to real users.
Built With
- gemini
- javascript
- node.js
- observai/sdk
- postgresql
- tailwind
- typescript
- vertexapi
- vite


Log in or sign up for Devpost to join the conversation.