-
-
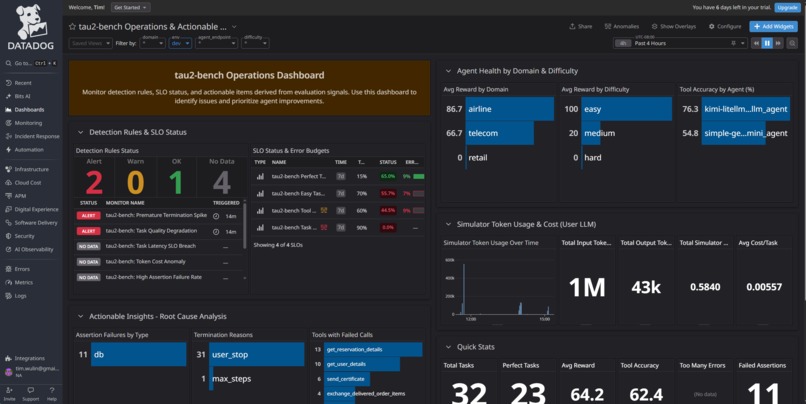
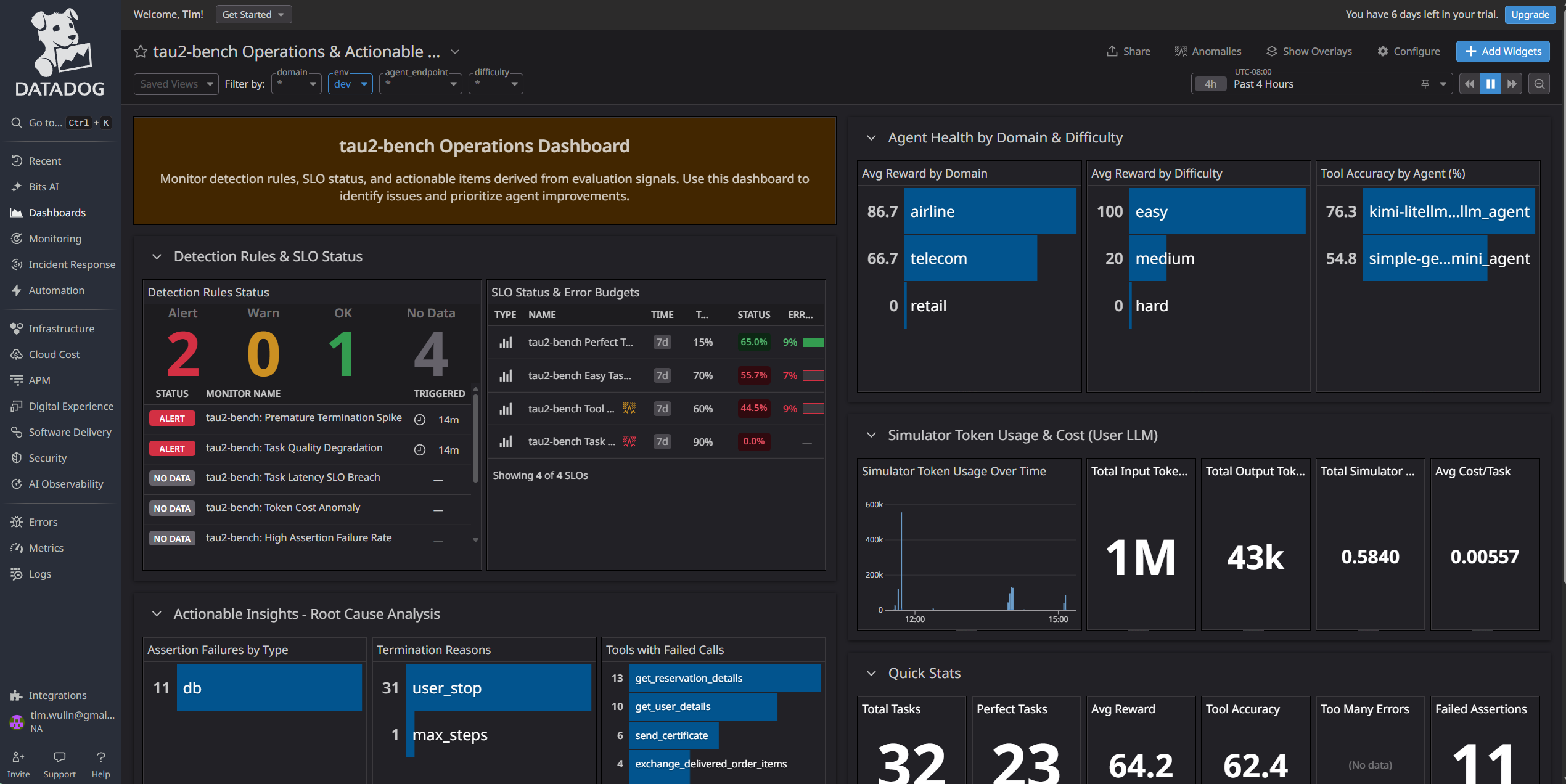
Dashboard - Agent Operations
-
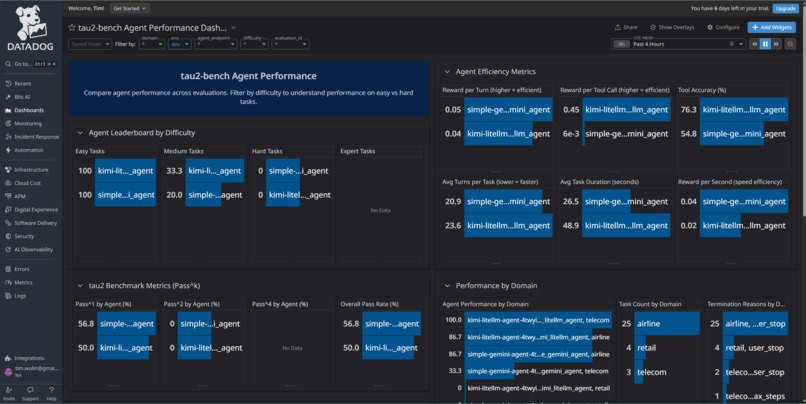
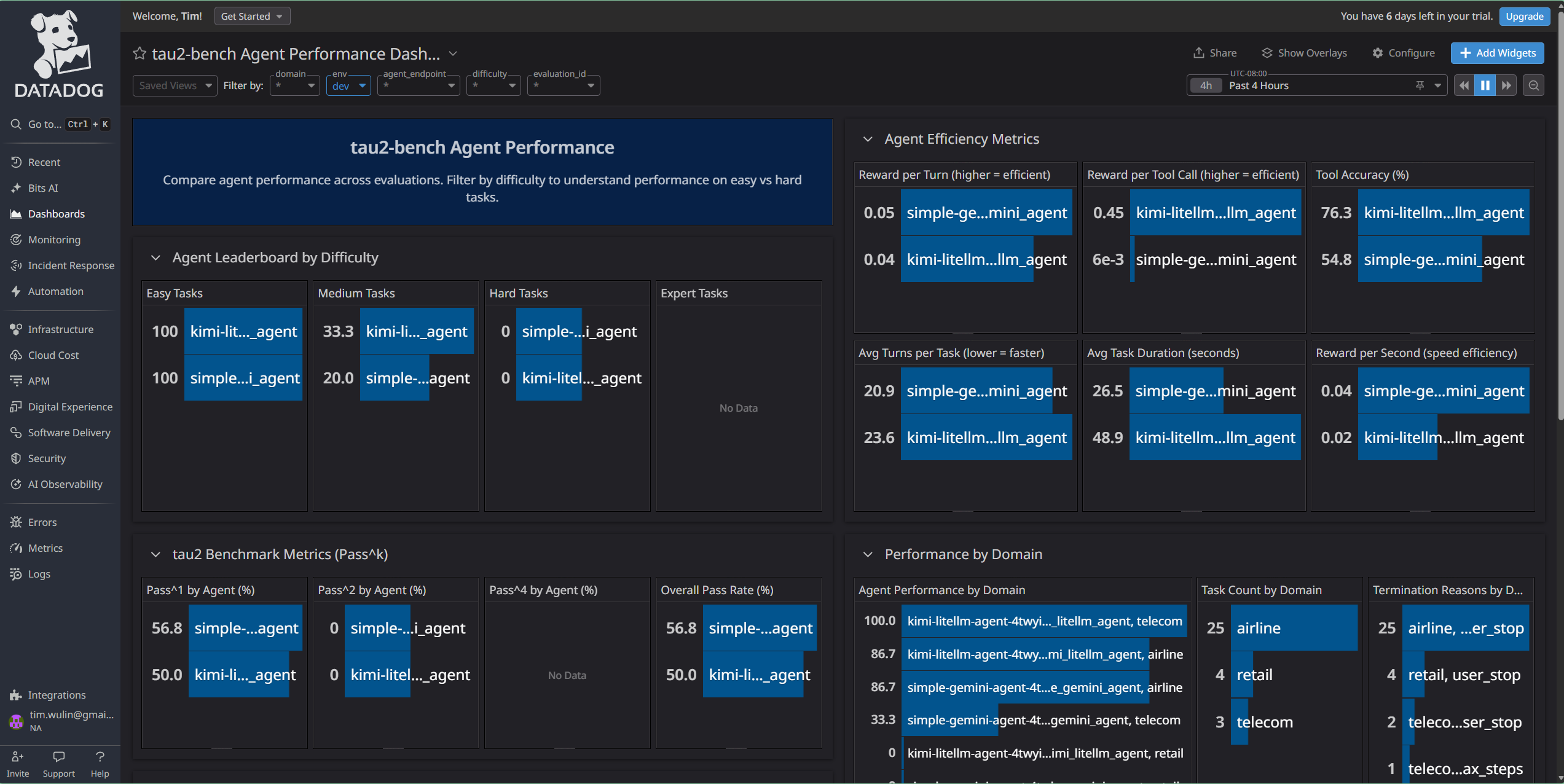
Dashboard - Agent Performance
-
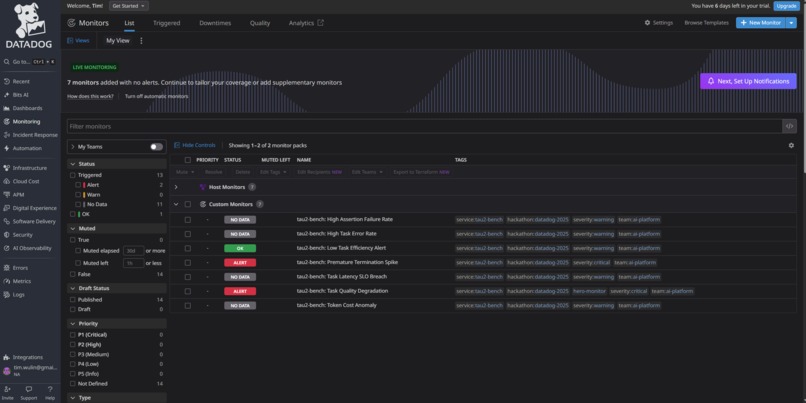
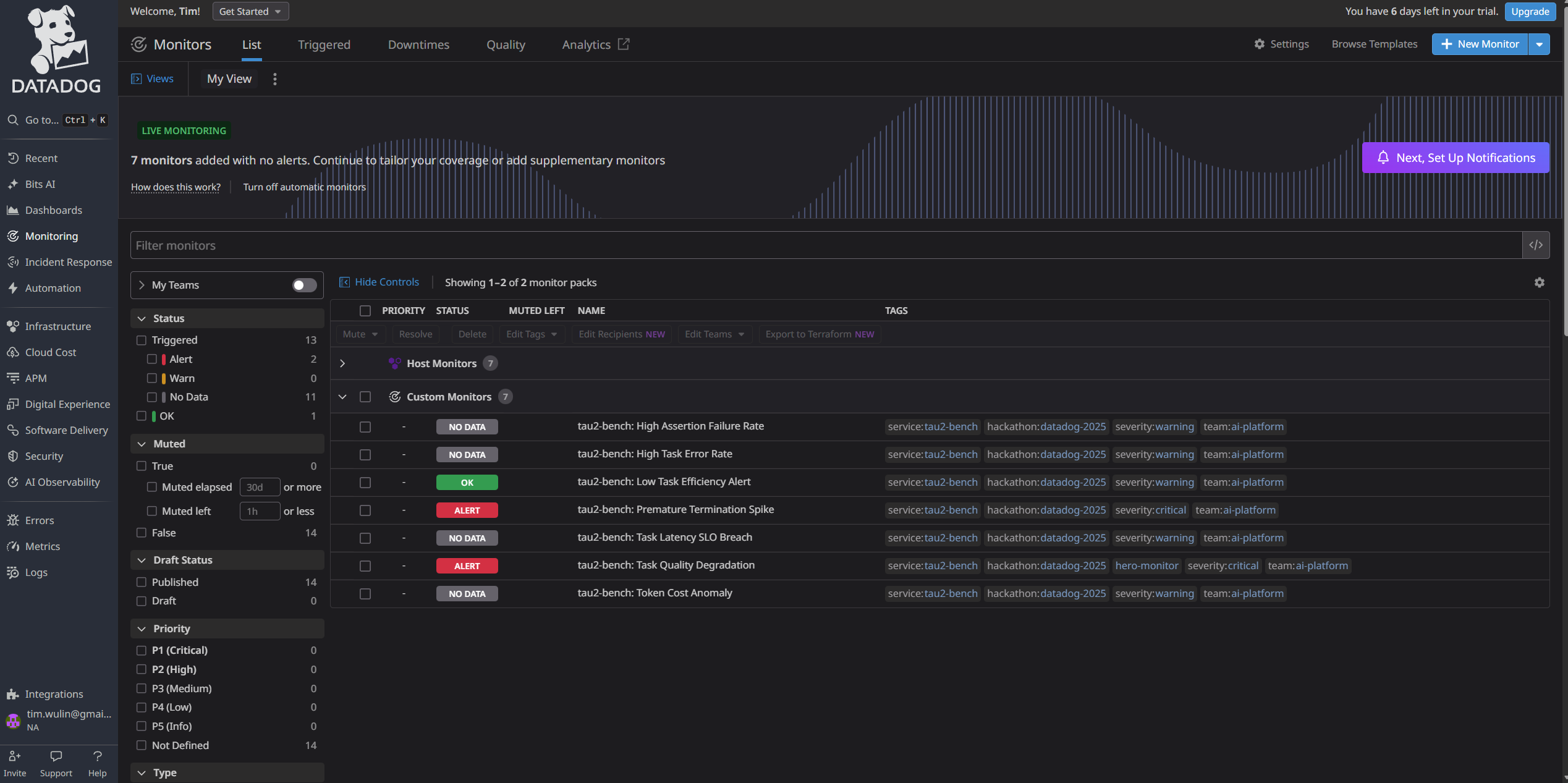
Monitors - List View
-
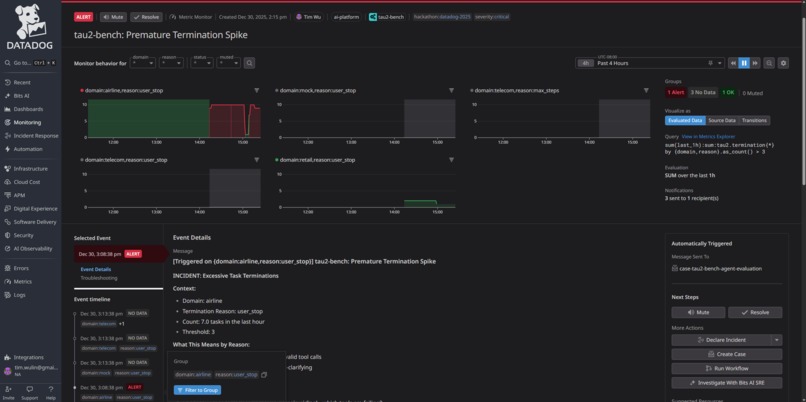
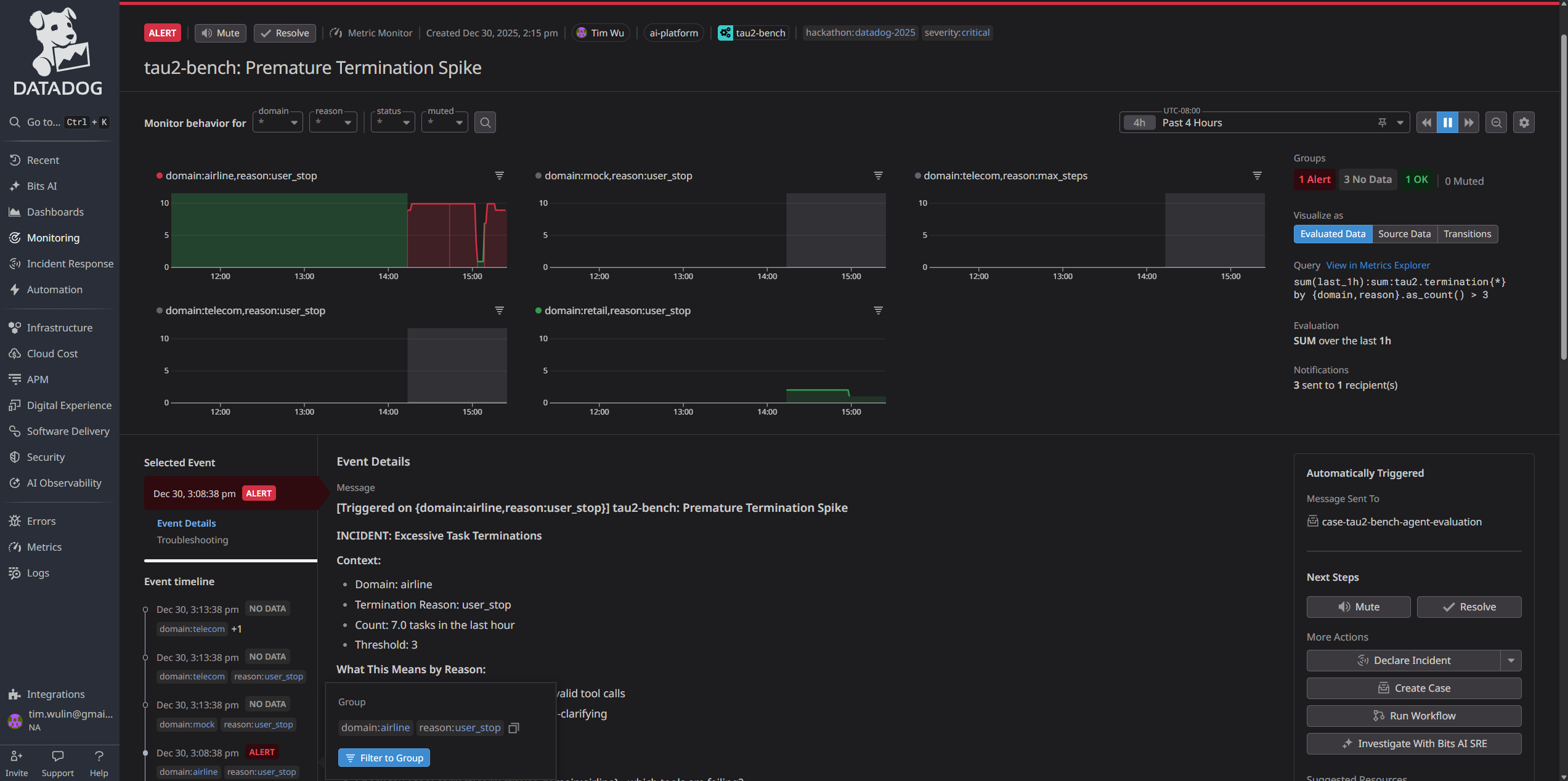
Monitors - Detailed View
-
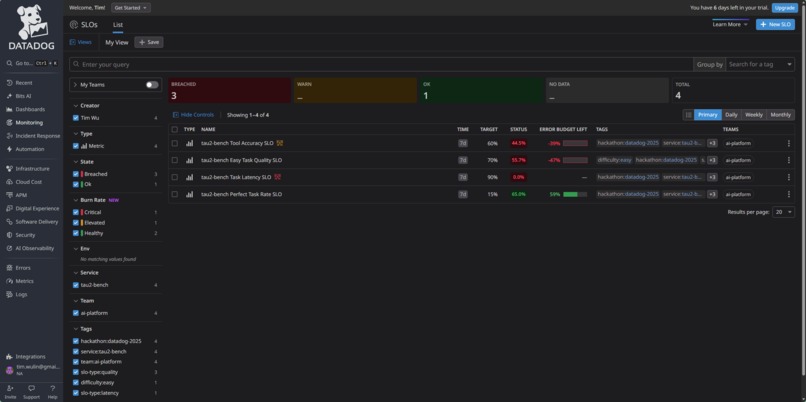
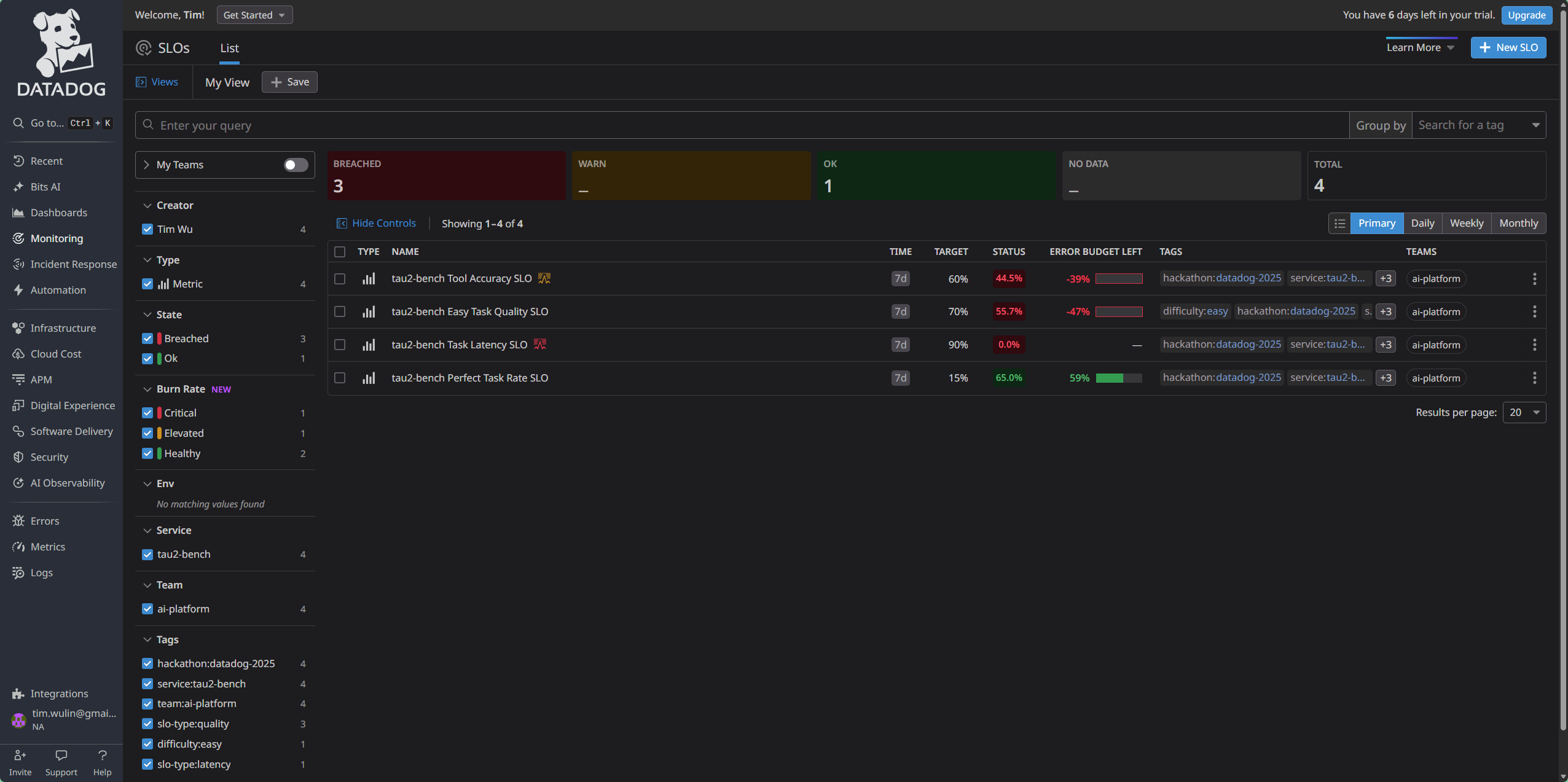
SLOs - List View
-
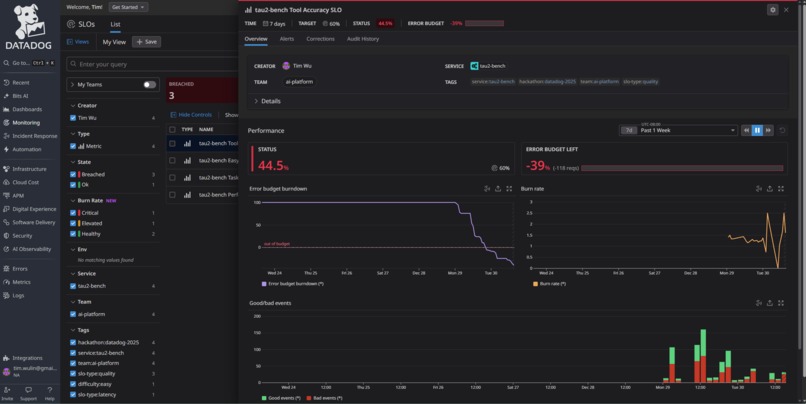
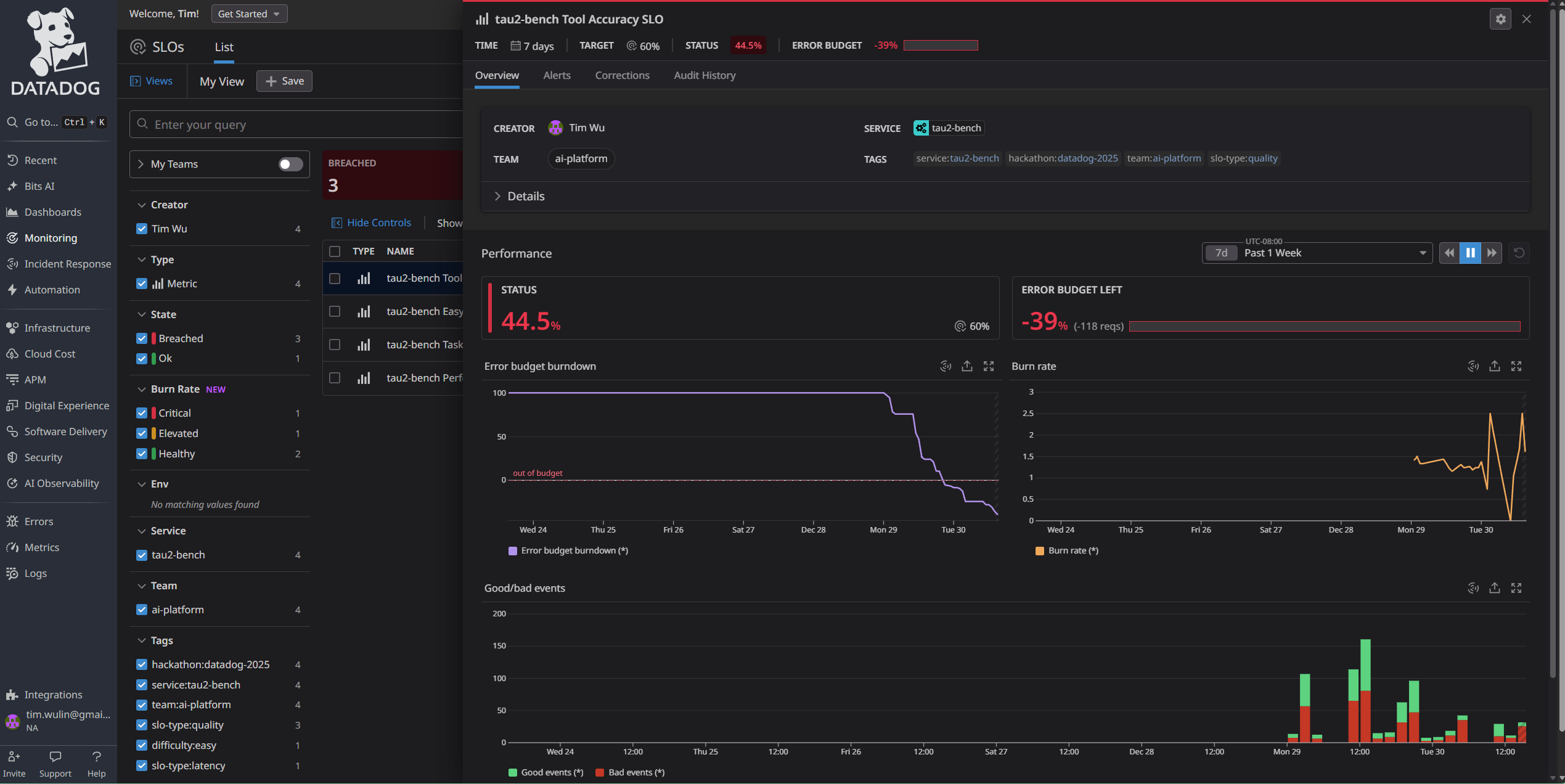
SLOs - Detailed View
-
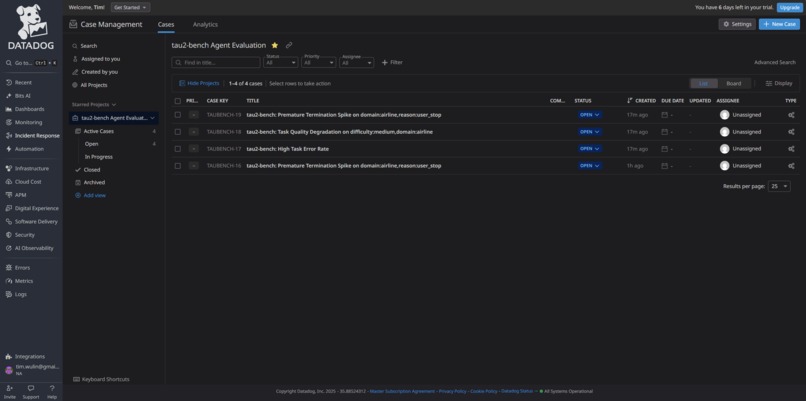
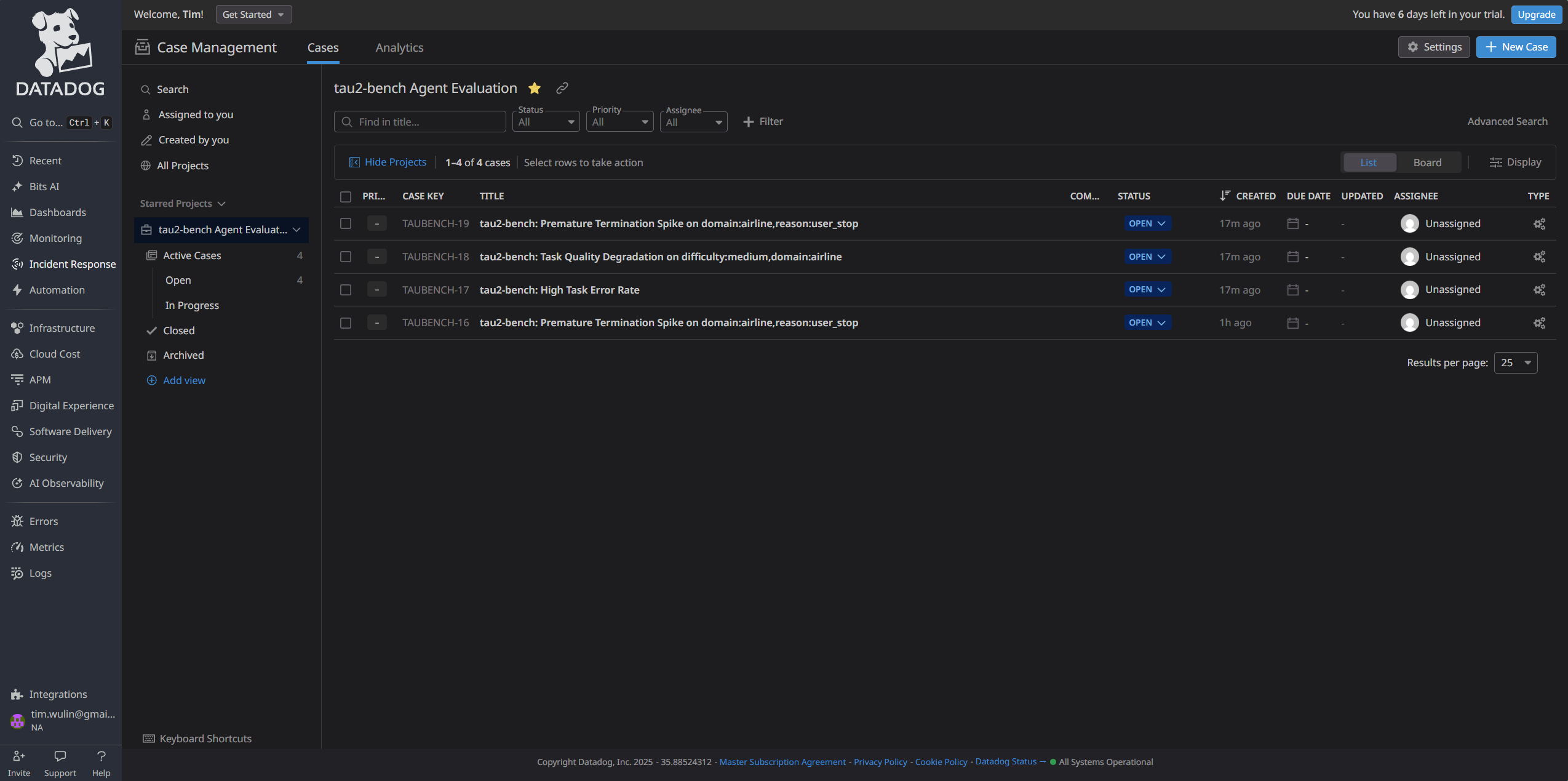
Case Management - List View
-
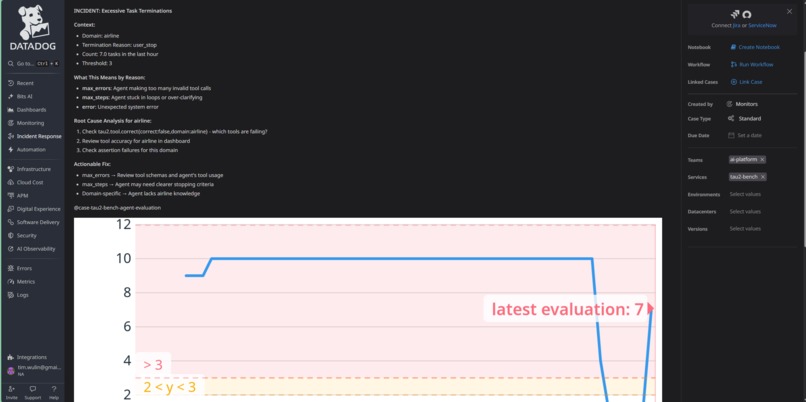
Case Management - Detailed View
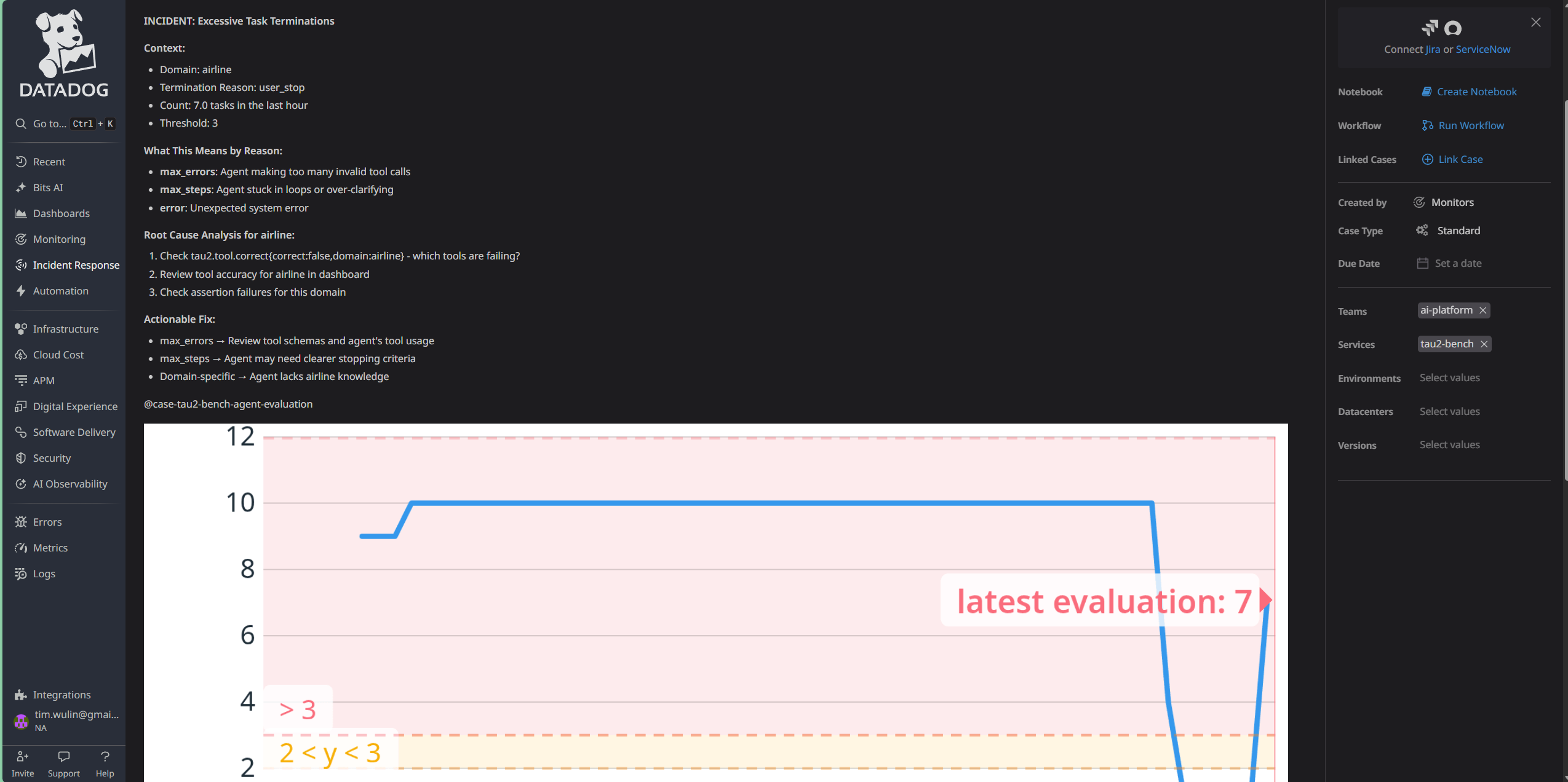
Inspiration
There has been a lot of dialogue surrounding benchmarks in the latter part of 2025. As the models have gotten better and better, it feels like currently established benchmarks have been providing less and less valuable signals. For an Agentic AI class at UC Berkeley, I developed an agent that could administer the tau2 benchmark to other agents through A2A. Given that the base tau2-bench project, and my agentified tau2-bench-agent, had no observability hooked in, I wanted to see if adding observability could enhance the agentic evaluation process. I felt that integrating my tau2-bench-agent project with Datadog would surface valuable insights that could help drive task quality and agent scaffold improvements.
What it does
Tau2Observe - An observability enabled tau2-bench-agent that uses Datadog to help trace LLM calls and surface tau2-bench evaluation metrics. Datadog helps to automatically define and trace LLM Observability metrics. We emit further custom metrics based on tau2-bench evaluations to Datadog via Datadog's API.
Tau2BenchAgent - The existing LLM application I am integrating with. Tau2BenchAgent is equipped with tools to be able to receive A2A requests and run tau2-bench evaluations for deployed agents.
How we built it
Overview
tau2-bench-agent integrates with Datadog through two paths: 1. Real-time Tracing (ddtrace with LLMObs) - Automatic instrumentation of LLM calls 2. Post-hoc Metrics (emit_metrics.py) - Evaluation results pushed to Datadog Metrics API
Process
Used Claude Code, DeepWiki, Gemini, and spec-kit (spec driven development tool), to assist with deep research, context gathering, and code implementation.
Once ddtrace was integrated with tau2-bench-agent, I created local tests to send metrics to Datadog and iteratively improve the dashboards. I chose baseline error rate metrics to define case-management notifications. I also iteratively improved LLM Observability traces by adding additional context and tags for evaluation traces and a2a-agent communication.
I created mock agents, similar to the tau2-bench-agent, using ADK to help with generating traffic and improving data diversity. I also created Dockerfile setups for each agent for containerization and deploy to Google Cloud Run.
Challenges we ran into
Dashboard Setup and Metrics
It's not straightforward trying to find, quantify, and visualize the exact data or metrics that you're looking for. It's also difficult to correlate metrics to real signals and surface actionable records. Clearly defining what to look for, correlating metrics, and driving next steps took a lot of data analysis and experimentation. With smaller amounts of dense data, it's easy to find wrong signals and miss critical edge cases.
LLM App Issues and GCP Integration
Integrating Datadog into tau2-bench-agent actually revealed some issues in how my agent was handling requests and loading environment variables. I also never ran a full deploy of the agent so initializing and debugging the GCP integration was a lengthy process.
Non-deterministic Development
I spent the longest amount of time debugging API rate limits and strange LLM response behavior. First, I ran into an issue with Google Cloud Run and my Gemini model. I was hitting a 429: Resource Exhausted error even though I didn't see any rate limits triggering with my Gemini API Key. Apparently, Gemini models are routed thru Vertex AI on Cloud Run and I had to explicitly disable it. Another issue I ran into was with the Gemini 2.0 Flash model running in tau2-bench. For some of the evaluations in tau2-bench, the Gemini 2.0 Flash model would return an empty response and error out the rest of the tasks. In the end, I switched to a more capable Gemini 3.0 Flash Preview and the issue was resolved.
Accomplishments that I'm proud of
Setting up the entire pipeline and Datadog integration in itself was a big accomplishment for me. It was so cool being able to see deployed agents being used and then seeing the traces appear in Datadog. I'm also really proud of the resulting Datadog dashboards; I feel like they're easy to understand and add a really impactful visualization to tau2 bench evaluations.
I'm also proud that on top of the Cloud Run deployment plus Datadog integration, I was able to fix a lot of issues in my tau2-bench-agent. I had to resolve async request issues, evaluation store persistence, and struggle with random LLM related errors that didn't show up in my local test suite.
What I learned
Integration always sounds easy but never is. I thought I could easily get Datadog tracing up-and-running on my tau2-bench-agent. But clearly, I was completely wrong. The integration, deploying, and debugging cycle ended up taking ~90% of the time. I didn't get to spend as much time refining the monitors and finding interesting ways to drive actionable steps or correlate different pieces of data.
I learned that you don't always know what you're looking for until you're looking at it. It's important to at least start visualizing some baseline sets of data to see what's there and get an idea of what isn't. The current tooling and documentation allow us to rapidly iterate on ideas that it doesn't make sense to get stuck trying to find the most complex of scenarios. After I started seeing data getting populated in the dashboards and the traces in the logs, I finally had a better mental image of what information I want to group and visualize.
What's next for Tau2Observe | Agentic Benchmark Observability
As I mentioned, most of the time was spent integrating, deploying, and debugging. I want to generate more diverse sets of evaluations against different agents and models. I want to build up more data to be able to figure out more relevant trends. For this particular iteration, I experimented with surfacing a "difficulty" metric for tau2 bench tasks. There is no inherent "difficulty" label for tasks, but I felt that it made sense to visualize agent performance by ensuring a clear separation between agents performing easy tasks vs. hard tasks. I think as models continue to get better, it's vitally important to constantly improve the benchmarks. I'm hoping that observability integrations with benchmarking tools becomes more widespread so that it becomes easier to improve benchmarks.

Log in or sign up for Devpost to join the conversation.