-
-
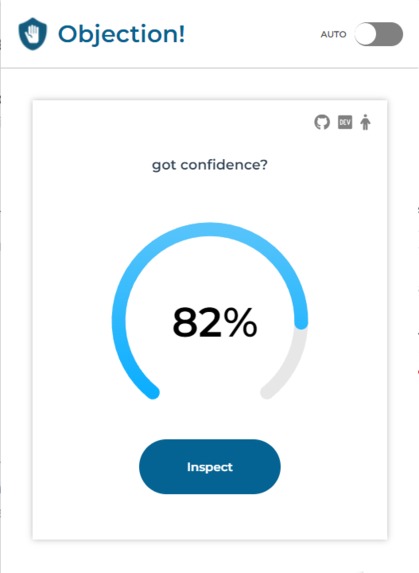
An article deemed to be credible with 82% confidence.
-
a toggle between automatic + manual
-
screenshot of our client codebase!
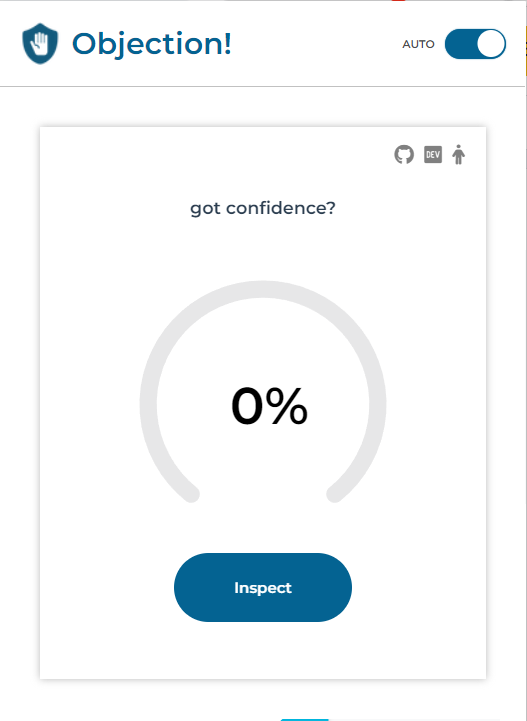
Objection!
Demystifying disinformation for a better truth.
Inspiration
Fake news is everywhere.
In an age of information overflow, we constantly have to filter between the right and the wrong, the truth and the lies, and the real and fake. We know about the existence of fake news, yet its prevalence continues to grow. We see it on TikTok, Twitter, Reddit, and even the largest news outlets. Every source has biases and agendas in some areas.
With its magnitude, disinformation poses an immense threat to not just businesses & officials, but everyone.
The recent trends of cancel-culture, political polarization, and crypto scams make this clear. We took on the challenge of building software that can restore societal trust and mend deep-rooted divisions.

Overview
Objection! is a reliable and efficient web extension that accurately identifies disinformation amongst a sea of disinformation texts. With a press of a button, users can get an accurate evaluation of a source’s credibility on a scale of 1 to 100 based on a machine learning model trained with over 50,000 articles.
Features + Tech
- Designed and built a convolutional LSTM for processing tokenized vectors.
- Performed preprocessing using Keras' tokenization + regex decluttering techniques.
- Developed NLP classification model that can accurately predict disinformation of text with >98% accuracy.
- Deployed our classification model to Google Cloud Run, a serverless architecture for GCP.
- Built an API using Flask to connect to our model with pytest + bash-friendly support.
- Dockerized our API and leveraged our workflow using Github Actions + GCP integration.
- Built Chrome extension with Vite as a development environment bundler to speed development + ES6/npm compatibility.
- Developed auxiliary web parsing functions into our learning model workflow + classification integration.

Client:
- Chromium
- Vite
- npm
- ES6 + HTML/CSS
API:
- Flask
- Docker
- Google Cloud Run
- Tensorflow
- Keras
Issues + Breakthroughs
Robustness vs. speed. As a team, we learned through struggling with an immense shortage of time while having a keen eye on the reliability and durability of our learning algorithms towards extraneous + irregular data. Expanding to our ideation process, we had to conduct execution decisions on what features would fully encompass our vision without posing a significant risk to our efficiencies as developers and designers. Machine Learning. We’ve also been relatively new to the logistics and construction of machine/deep learning, and diving into a natural language process problem head-first led to ventures deep in academic research and many scrapped architectures. However, we remain confident after enduring through multiple iterations to finally amass a classification model capable of predictions with competitive confidence rates– a product of our relentless endurance and tenacity. Dependencies. Due to having a diverse tech stack, we faced many issues with package dependencies. At some point, our API could only be locally hosted without issue on some machine architectures, so we needed to approach cloud-based deployment + dockerization in order to reduce the impact of machine-dependent development and test the integration of the model in the API. Tokenization + sample size. We had problems with our machine learning model as well, as it predicted extraneous (outside) datas at undesirably low confidence levels. We solved this by converting our text into tokens before funneling into our model to ensure it would fit tokens to the test data. Since we started small with our test cases, our resulting matrix was getting zeroed out because the tokens were not being fixed based on the test data.
Next Steps
We want to first expand our reach at a technical standpoint, and develop compatibility for multiple web browsers (Firefox, Opera, Safari), but also to prioritize accessibility by launching as a mobile application for iOS and Android platforms. We hope in future ventures to also develop a more personalized application for user-catered profiling and a flexible, yet reliable archiving of a user’s past history with high-risk articles. Within this app, users can directly integrate into a social network in which their views on articles’ credibility can be shared amongst others with the freedom to report/spread awareness. In the future, we look to extend the use of our extension to more sources and academic research. For example, we seek to explore disinformation within social media, tackling the ‘source’ where it often spreads rampantly.
We believe that Objection! will pave the way for a more honest and embracing community, with boundless amounts of potential for mitigating sources and acts of information and communication.
Built With
- chromium
- css
- docker
- flask
- github-jobs
- google-cloud
- google-cloud-run
- html
- javascript
- keras
- lstm
- natural-language-processing
- npm
- tensorflow
- vite





Log in or sign up for Devpost to join the conversation.