-
-
Main page
-
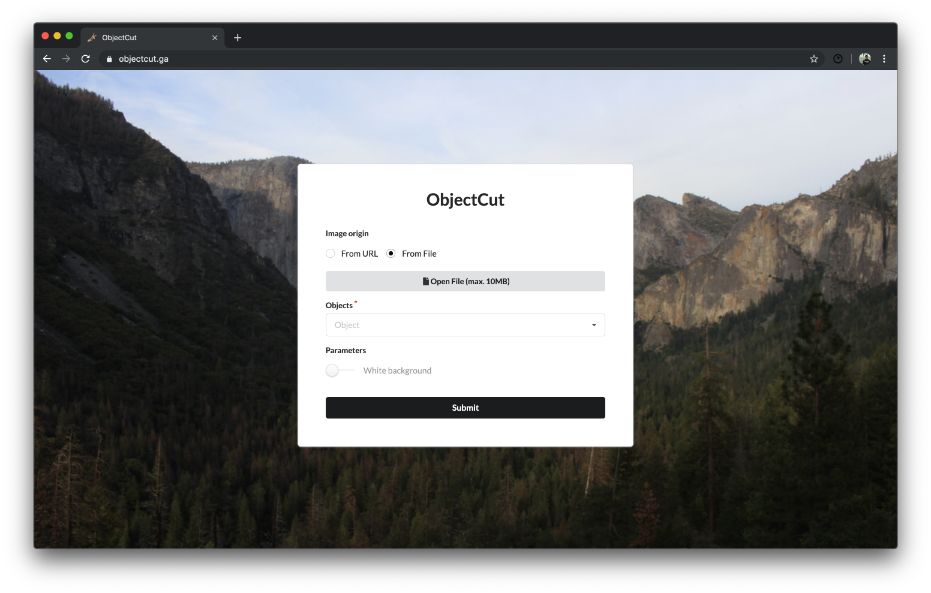
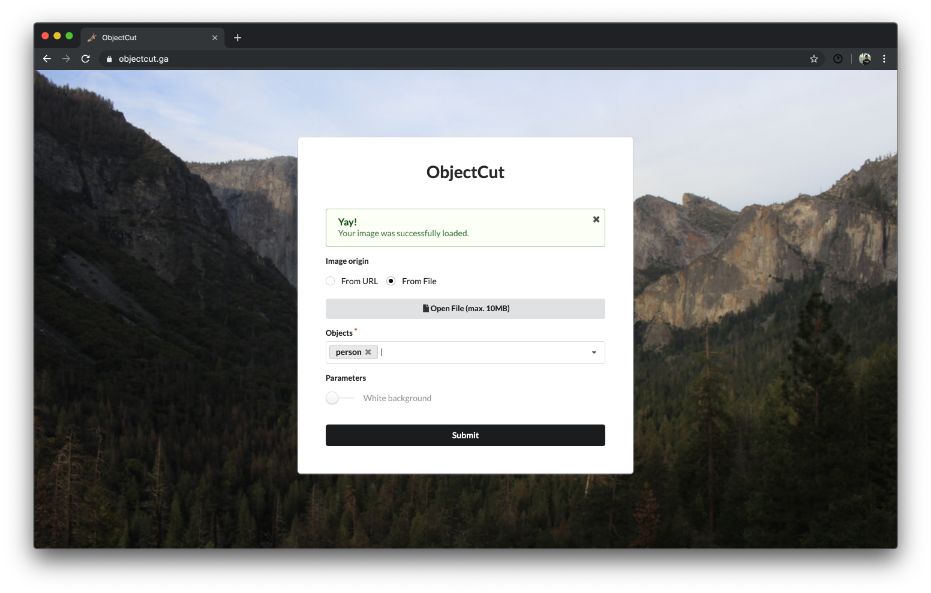
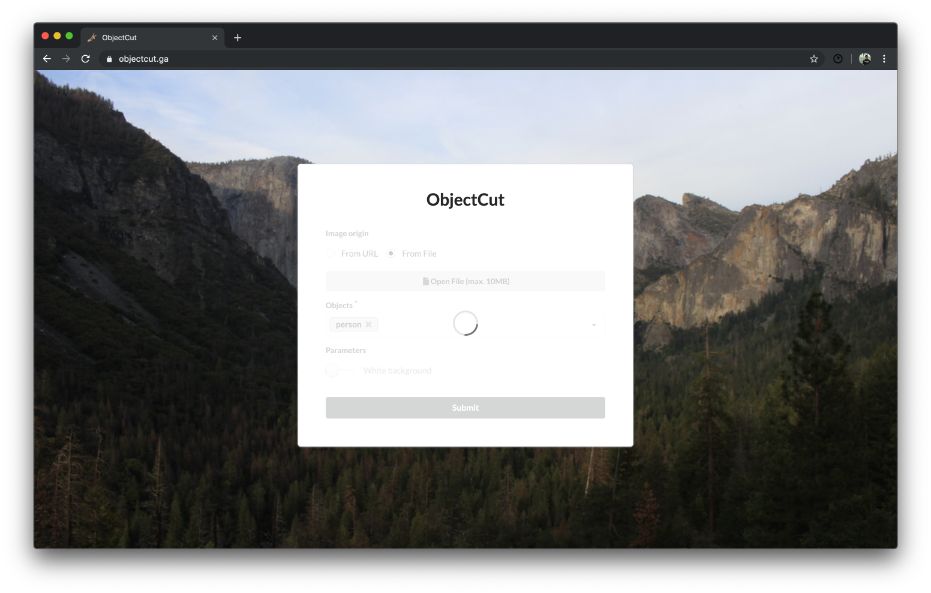
Uploading a file and typing some objects
-
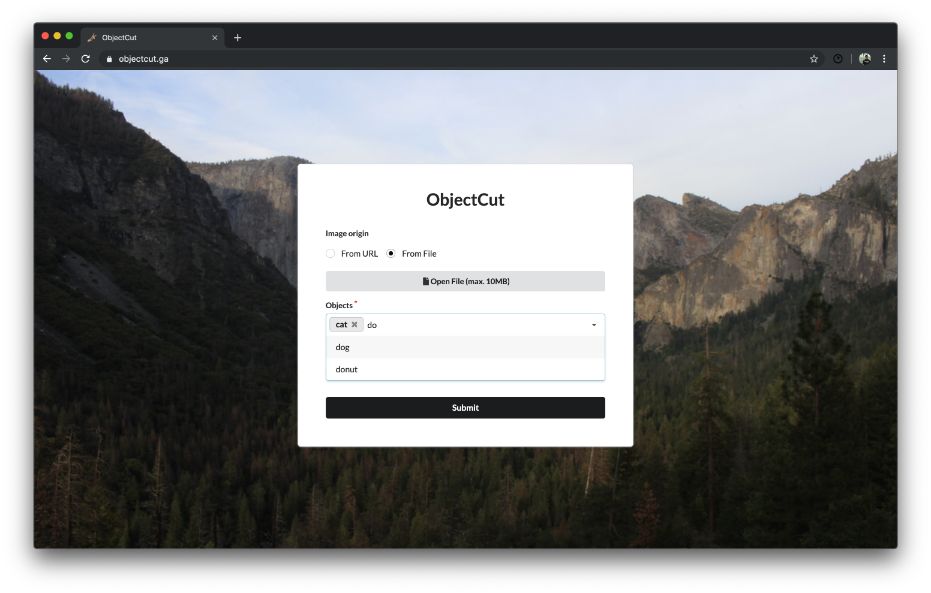
Possibility of typing multiple objects
-
Loading result
-
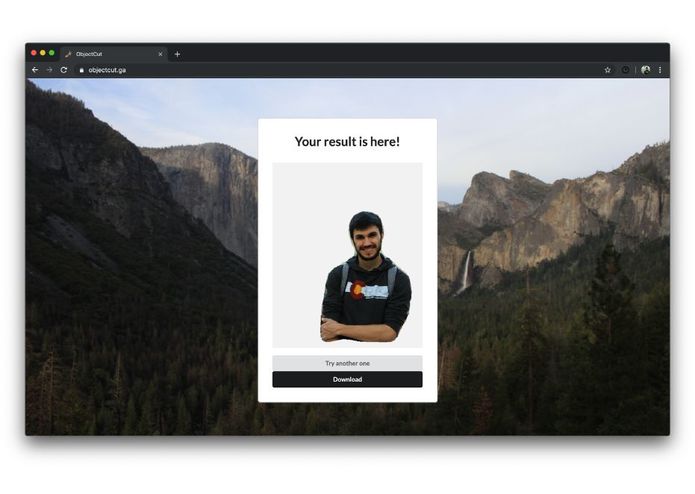
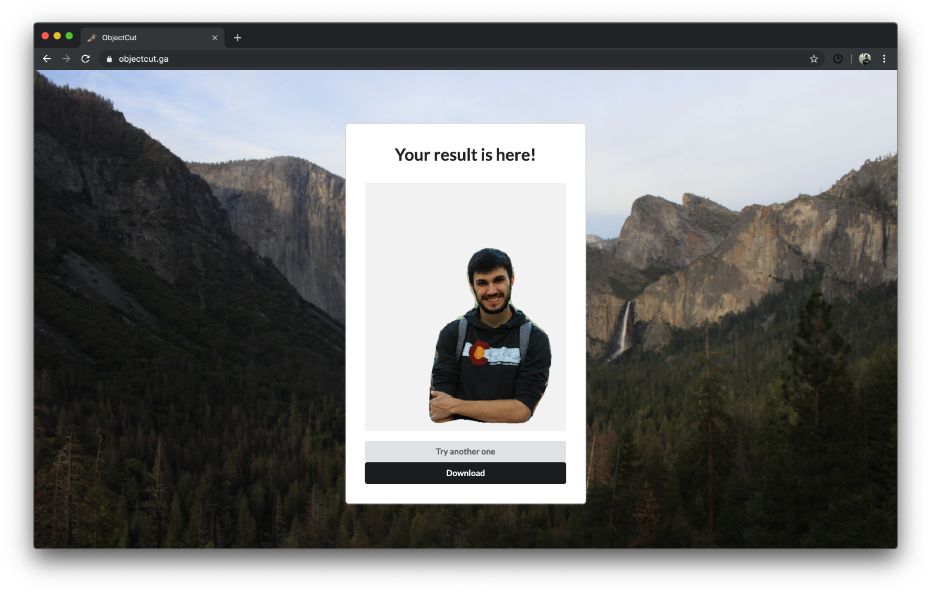
Image cropped
Inspiration
The inspiration came really from a moment where we needed to cut a person from a picture. We needed to make a simple extraction but we did not have the knowledge to do it or the tools (which most of them are not free like remove.bg, or what is more, not even available on Linux like Photoshop) so we decided to use Deep Learning to tackle this problem and allow to everybody do to extraction from a picture automatically.
What it does
It takes a picture, from an Internet accessible URL or an image itself uploading it, and a set of labels that are typed by the user, then we send that information to our API which then it runs a Mask-RCNN PyTorch model to extract the masks of each class. Then using that information we are able to create a mask that includes all the desired classes to extract those pixels and return it without background.
How we built it
Frontend and backend are very different components connected by API requests.
At frontend, we can see a simple HTML (with CSS and JS) that uses the library Semantic UI in order to use the UI components. This part has been deployed using GitHub pages using custom and free .ga domain below HTTPS protocol.
In the other side of the application, we have the backend which is implemented with Python 3.7. For creating the API that allows the communication between the two components, we have used Flask and OpenAPI (connected themselves with Connexion library), integrated with Docker compose. This API is hosted using uWSGI and Nginx in a small DigitalOcean droplet with a secure reverse proxy through a certbot certificate (needed for a secure connection between both components).
To deal with image stuff like resizes or deleting the background we use Pillow Python's library, then as a main core of the application we use torchvision and its Mask-RCNN model trained with the COCO dataset, an extension of Faster-RCNN which adds the masks of each class that has been detected.
The model has two main stages. Firstly, using a Region Proposal Network (RPN) it generates several region proposals where there might be an object. Then, secondly, it predicts the class of the object, refines the bounding box and generates the mask in pixel level based on the first stage proposal. Using this outputted mask then we can create the image desired by the user.
Challenges we ran into
First of all, one member of the team had never worked with PyTorch, and the other one did very little (with the 0.4 version) so it was kind a challenge to get out our comfort zone. Then, our main goal was to make something actually useful so we needed to develop a complete project, not only an script or a tool available only for tech people; that created several challenges like adding the functionality of the script to a website, also the website had to be intuitive and well-designed and everything had to work smoothly.
Since we decided to use GitHub pages, with a HTTPS protocol, for deploying the frontend we needed to deploy the API with the same protocol, which encrypting and certifying a domain was a thing that no one of the team did.
Accomplishments that we're proud of
We are really proud with the final project we have developed. It is really useful and probably we will use it in the future. Our goal was to build something that someone out of tech could use daily. Looking at the result, we think that we've achieved it.
What we learned
We have learnt how beautiful can be to insert Deep Learning to your solutions using PyTorch and all its facilities: torchvision, datasets, etc. Until we came up with an idea of the project we really dived into it and we were amazed by all the possibilities it opened. Also we learnt, a lot, about how to deploy a real product (in the real world) using tools as it's been explained such as uWSGI, Nginx, etc. This last was important since we wanted to create something useful for us and for the community.
What's next for ObjectCut
ObjectCut can only extract 91 classes since it is the COCO pretrained model but it would be a nice improvement to train it with more classes. Also another feature that could be interesting to implement would be to add the option to load your saved Mask-RCNN model in the website UI.








Log in or sign up for Devpost to join the conversation.