-
-

Figure 1: Sample high-def MR2 multi-racial facial stimuli images
-
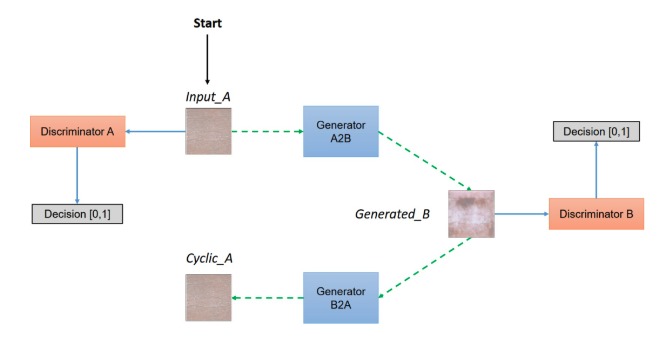
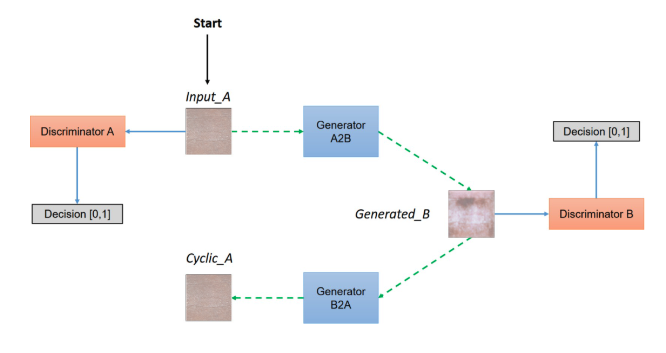
Figure 2: CycleGAN model architecture
-
Figure 3: Pix2Pix U-Net filter applied to source (top) and target (bottom) data.
-
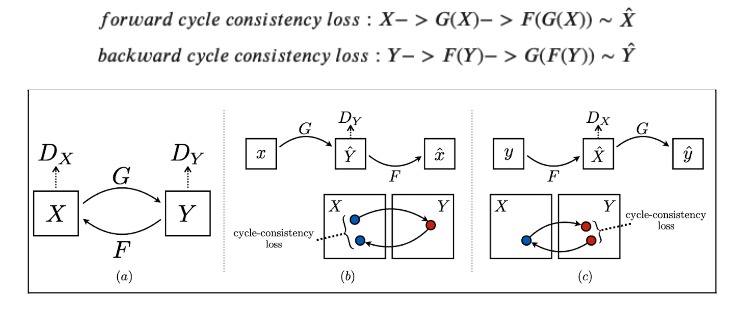
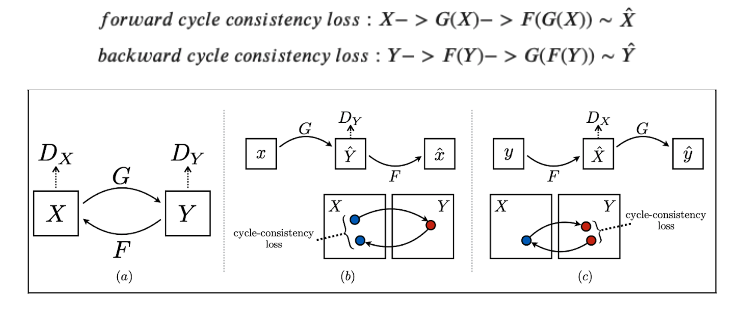
Figure 4: Cycle Consistency Loss (Tensorflow Illustration)
-
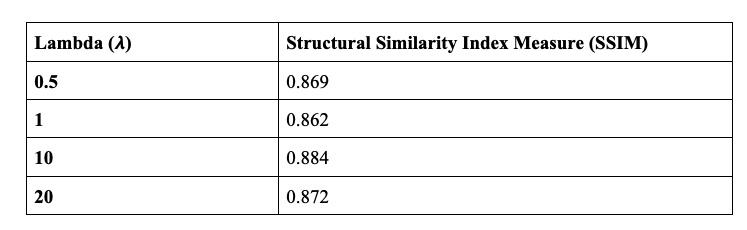
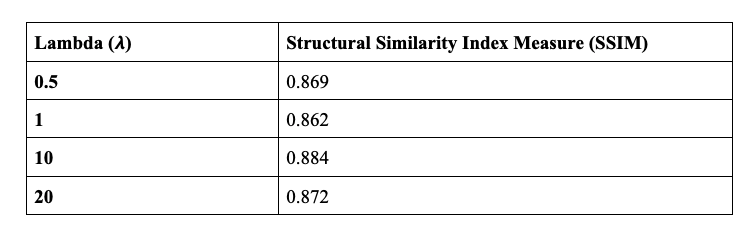
Table 1: Structural Similarity Index Measurements (SSIM) of Various Lambda Values between Input and Predicted images
-
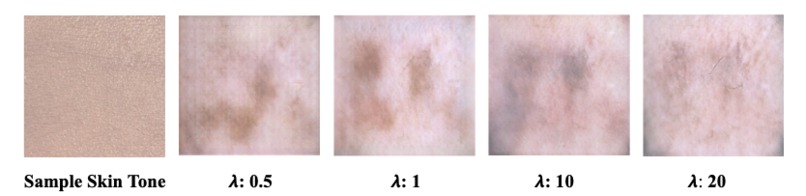
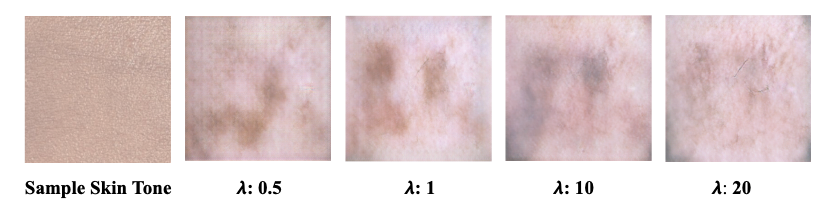
Figure 5: Input Image (skin tone) and Predicted Melanoma Lesions for various Lambda’s
-

Poster Presentation


Final Write-Up/Reflection
Introduction
Melanoma still remains the most lethal form of skin cancer today. With the increasing power of machine learning, the early diagnosis of melanoma has begun to shift from solely expert dermatological evaluation to including automation as well. In any machine learning context, there will be inherent biases according to the nature of the training dataset; whether it be class imbalances between different forms of dermatological lesions or the stage of development at which the pictures are taken, this will impact the predictive and diagnostic power of the model. The problem our group set out to address was the imbalance in skin tones found in one of the most widely used skin lesion datasets HAM10,000. While darker skin tones are considered to be less at risk for melanoma than their lighter counterparts, there remains an ethical and moral need to ensure that the AI systems are not disadvantaged at predicting the presence of melanoma in these under-represented populations. Another limitation in these datasets is the paucity of melanoma data points– predictive models are best optimized when working with large datasets. For this project, we have utilized the power of unpaired image-to-image translation using a CycleGAN model architecture to generate synthetic, multi-racial melanoma lesion data. Thus we hope to address the issues of data bias and data scarcity. The model is based on the paper Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (Zhu, et al).
Methodology
Data
For the skin tone data, we developed a database of skin tones through an image processing pipeline to extract skin patches from the MR2 dataset. This dataset is a multi-racial, mega-resolution database of facial stimuli, created in collaboration with the psychologists Nina Strohminger and Kurt Gray and the photographer Titus Brooks Heagins. It contains 74 full-color images of men and women of European, African, and East Asian descent. This dataset was chosen due to its diversity of skin tones and high resolution, an important factor given the medical nature of our project. For the skin lesion data, we used the HAM10000 dataset; the dataset came with metadata that we had to parse with the images. As such, a pipeline was developed that mapped image ids with the skin lesion type. A count of the melanoma class indicated 1113 melanoma samples.
Pre-processing
It was determined that the following cropping dimensions would extract forehead patches from the MR2 Dataset: [Left = 1380, Top = 850, Right = 1700, Bottom = 1150]. We decided that forehead patches would be the best patch area to extract due to it generally being devoid of hair, and other facial features that would produce external variabilities. These patches were further cropped into 256 x 256 patches.
Due to the minimal number of images available in the MR2 dataset (only 74 images), data augmentation was applied to further expand the dataset size. To this extent, we utilized Tensorflow’s data augmentation pipeline and generated a set of 3 other skin tones dataset with different saturation to simulate different skin tones. The tf.image.adjust_saturation function was applied with values of 1.3, 1.6, and 1.9. Similarly, the melanoma image samples were normalized and reshaped into 256 x 256 images. Lastly, we had to code two separate preprocessor pipelines to preprocess the skin lesions and the skin tones data to store the training and testing images in same-sized tensorflow dataset objects.
Model *Architecture *
The CycleGAN model paper is a derivation of Generative Adversarial Networks (GANs, Goodfellow, et al) and it builds on the “pix2pix” framework of Isola et al. The general idea behind unpaired image-to-image translation is to relate two data domains: X and Y. In our case, domain X represents the synthetic skin tone data and domain Y represents the melanoma data. Our architecture involves feeding in the skin tone data and melanoma lesion data, and with the use of generators and discriminators, predict how the lesion would appear on the input skin tone data. The generator used in this model is a modified U-Net which features an encoder that downsamples the images and a decoder that upsamples. In each block of the encoder there is a convolutional layer, a batch normalization step followed by a leaky ReLU. For the decoder portion, there is a transposed convolution, a batch normalization and dropout before applying ReLU. The U-Net generator also features skip connections to ensure the proper flow of gradients during backpropagation. As our goal was to generate synthetic skin lesions on a given arbitrary skin tone, it was crucial that the resultant image and the original skin tone image shared a certain level of structural similarity. In order to evaluate our predicted images, we utilized structural similarity index (SSIM) scores (Wang, et al). The SSIM is computed by taking into account the luminance, contrast and structural similarity of the images. Although the structural similarity index measurement has certain similarities with mean squared error (MSE), it does not estimate absolute errors. The general idea behind structural similarity is that it compares structural information between the original and generated image, that is pixels have strong interdependencies and these interdependencies carry valuable information pertaining to that image. Due to the medical nature of this project, we wanted to ensure image quality was maintained and that SSIM could be used as a proxy for the recapitulation of skin tone in the predicted images.
Loss Function The idea of a CycleGAN is to use unpaired, image-to-image translation. In order to enforce that the input and target have a meaningful relationship during training, the hallmark of this model architecture is the cycle-consistency loss. Cycle consistency ensures that the resulting image should be close to the original input. In our application, cycle consistency must be fine-tuned as we hypothesize that no cycle consistency would make the model have no reason to generate a new skin tone, and too much weight on cycle consistency will preclude adequate melanoma generation. For this reason, we fine-tuned the Lambda hyperparameter, the value which controls the weight of the cycle-consistency loss during training, to various values to compare the predicted images and their similarities to the original skin tone image.
Results
As mentioned earlier, we have tested various lambda hyperparameter values in the CycleGAN model to track and assess how lambda, which is utilized in the cycle consistency loss, affects the generated images. Due to the computational limitations, we were unable to fully train our model. Quantitatively evaluating the output of a CycleGAN is a non-trivial task; ideally, the use of professional dermatologists to blindly assess whether they believe the predicted images to be real or fake would be implemented. However, our research group did not have those resources at our disposal. The input skin tone makes up the largest proportion of the image scale and so assessing the SSI allows us to gauge how much the predicted image tends to recapitulate that skin tone. In the end, the optimal prediction (quantitatively) was achieved using 𝞴 = 10 (see Figure 5). However, our project is ultimately one that is qualitative in nature and the predicted images do not appear to pass clinical standards for incorporation into the leading skin lesion datasets.
Challenges
There were various challenges we encountered throughout this project. The data collection process and the execution of computationally-heavy code posed obstacles to our progress. Due to our inability to find a high-resolution multi-racial skin tone dataset, we had to generate our own skin tone data. Additionally, we trained the model on a local CPU due to complications arising from the created VM instance. The VM instance was created without a pre-loaded image, and thus there were not all the dependencies needed to run TensorFlow code and the accompanying installations– the error messages were indecipherable to us and we decided not to consume more of our time addressing this issue. We began to notice that regardless of the skin tone sample we used to generate a set of images, the output did not adequately capture the input skin tone. Interestingly, there was some diversity in the melanoma lesions generated depending on the sample chosen. The lack of diversity in the output is indicative of potential mode collapse– a common problem with GANs. To address this, we attempted to change our learning rate for the optimizer and even the optimizer itself to “RMSprop”, however, these attempts were unsuccessful.
Reflection
While we were excited to see that some predicted images contained realistic-looking lesions (to the amateur eye), we all agree that there is work to be done in using CycleGANs for debiasing melanoma lesions data. It is still uncertain whether this model is the ideal candidate for addressing the issue of skin tone bias in dermatological lesions datasets. We believe a future direction could look at implementing a Wasserstein-cycleGAN with a more mode collapse resistant loss function. It could also be that what we observed was not a mode collapse but simply a limitation of the CycleGAN architecture in the synthesis of novel skin tone melanoma lesions. We hope that future work can build upon our research with more intensive computational power and generate even higher resolution synthetic images. Furthermore, another limitation was the source of data. A promising future direction could be for clinicians and ML researchers to create a larger and more diverse dataset of melanoma at various stages and skin tones respectively to aid in the continual process of debiasing skin lesion datasets.
Built With
- keras
- python


Log in or sign up for Devpost to join the conversation.