-
-
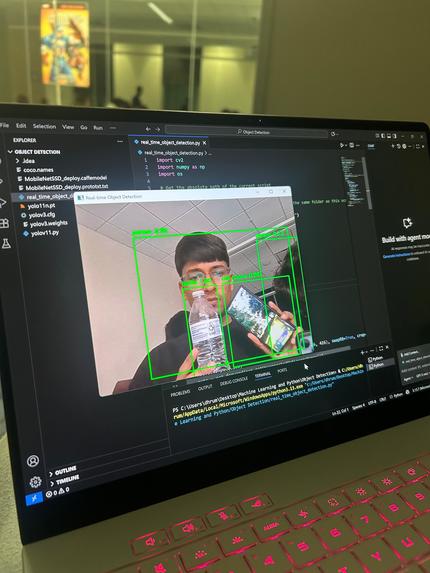
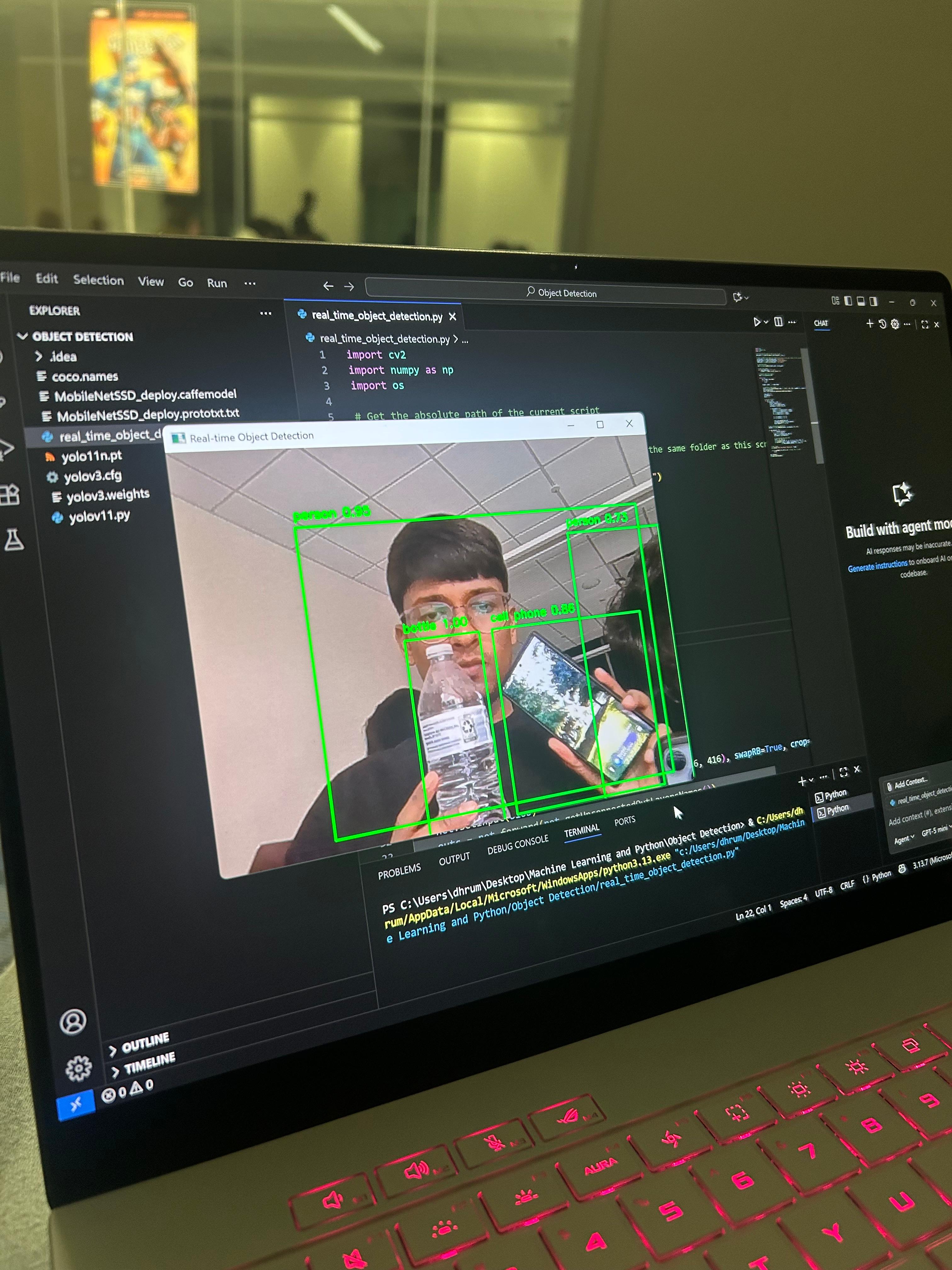
detecting person, bottle and cellphone
-
Inspiration
My inspiration for this project came directly from seeing the groundbreaking work of Elon Musk and Tesla. I was fascinated by how their vehicles could detect objects in real-time, essentially giving the car a sense of sight. This sparked a deep curiosity in me to understand how machines perceive the world, and I set out to build my own system that could "see" and identify objects through a simple webcam.
What it does
This project transforms a standard webcam into an intelligent eye. 👁️ It captures the live video feed and, in real-time, identifies and draws boxes around various objects it recognizes, labeling them with what they are (e.g., "person," "car," "cup").
How we built it
We built this system using Python as the primary programming language. We used the OpenCV library to capture and process the video frames from the webcam. The core of the object detection is powered by YOLOv3 ("You Only Look Once"), a pre-trained deep learning model renowned for its speed and accuracy, which we implemented to analyze each frame and identify objects
Challenges we ran into
Our main challenge was the sheer computational power required. Training the model took an extremely long time because the dataset is so large. Once built, running the detection in real-time pushed our GPU to its absolute limits, as it had to process the video and run the detection algorithm simultaneously. Managing software dependencies and optimizing the code for a smooth frame rate were also significant hurdles.
Accomplishments that we're proud of
We're incredibly proud of building a functional, end-to-end computer vision system from the ground up. Achieving smooth, real-time object detection on a live webcam feed was a major milestone. More importantly, we're proud of gaining a deep, practical understanding of a technology that is shaping the future, from self-driving cars to automation.
What we learned
This project was a crash course in applied artificial intelligence. We learned the fundamental principles of computer vision, the practical steps of implementing a deep learning model, and the critical role that hardware, especially a powerful GPU, plays in AI applications. We also learned the valuable lesson of managing large datasets and the patience required for model training.
What's next for Object Detection - OpenCV
The next logical step is customization and expansion. We plan to:
Train on a Custom Dataset: Teach the model to recognize specific objects unique to our needs, like particular tools, product models, or even specific people.
Improve Performance: Explore more recent models (like YOLOv7 or YOLOv8) or optimization techniques to increase the frame rate and accuracy.
Add Functionality: Integrate the detection system with other applications, such as triggering alerts when a specific object is detected or tracking the movement of objects across the screen.


Log in or sign up for Devpost to join the conversation.