-
-
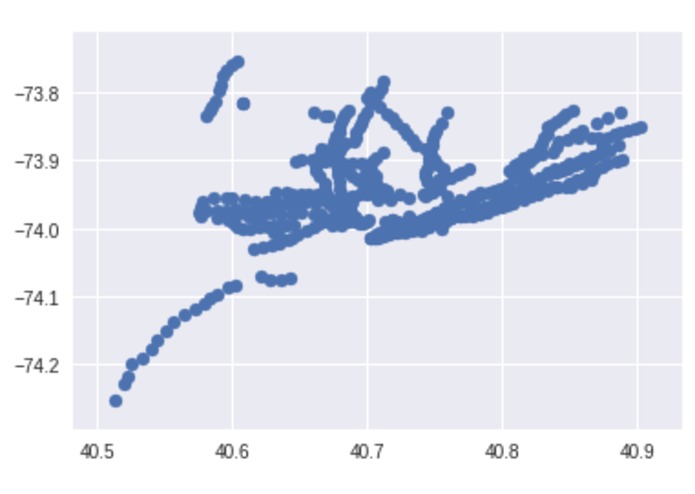
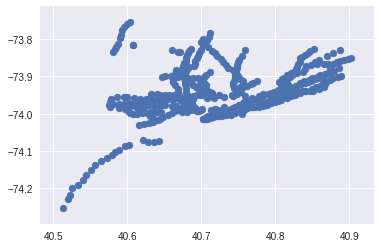
Distribution of Subway Stations in NYC
-
Picture of the Notebook
Inspiration
I wanted to test my knowledge of breadth-first search from the algorithms book I am learning from and to test my data wrangling knowledge. In order to learn machine learning, one must have a good foundation in data science. Additionally, I use the NYC MTA nearly everyday in order to commute to school or other places within the Tri-State Area.
What it does
It is supposed to give you the minimal amount of transfers that you can take to get from one station to the next. However, I didn't have enough time to finish it. Thus, it currently returns all the unique subway lines from the CSV file, the stops of each individual line, the transfers of each stop and a scatter plot showing the distribution of subway stops based on their latitude and longitude.
How I built it
I looked online for a CSV file that contained all the subway stations in the MTA and data wrangled it using the pandas library in Python to isolate two items: the stops for each individual train in the MTA and the transfers a person can make from each stop. I would have combined the two factors but there wasn't enough time. For contextual purposes, I also used the matplotlib library to plot a scatter plot with the latitude and longitude of the stops given.
Challenges I ran into
I wasn't really sure how to split the keys in a python dict that well, which took me 30 minutes to solve and to find the transfers given a station name was also a small challenge. Furthermore, it was orignally confusing to know which columns to target in the CSV file before beginning in order to isolate the factors I wanted using loops and vectorization.
Accomplishments that I'm proud of
I finally created something original based off my data science skills without being intimidated! Usually, with no inspiration for a subject, I delete the python file if I am not interested in the project after several days. However, this project is nearly complete and shows my good understanding of the pandas framework for data wrangling and preprocessing.
What I learned
How to apply certain classes within the Python Collections framework such as defaultdict and deque and certain data wrangling techniques via a pandas.dataframe on a CSV file I found online.
What's next for NYC MTA Open Subway Kiosk
Connecting the two parts of the Jupyter Notebook linked below to finally finish the project!

Log in or sign up for Devpost to join the conversation.